 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Label Refinement for Semantic Segmentation of Satellite Images
Sep 12, 2023
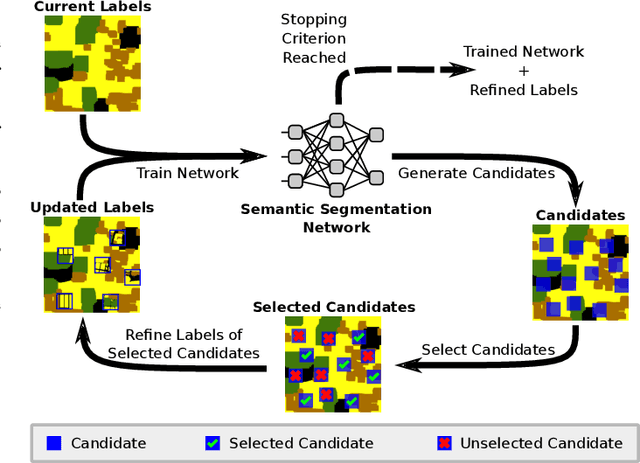
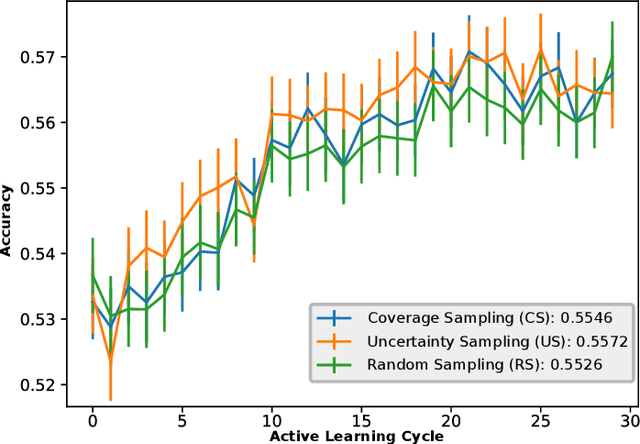
Remote sensing through semantic segmentation of satellite images contributes to the understanding and utilisation of the earth's surface. For this purpose, semantic segmentation networks are typically trained on large sets of labelled satellite images. However, obtaining expert labels for these images is costly. Therefore, we propose to rely on a low-cost approach, e.g. crowdsourcing or pretrained networks, to label the images in the first step. Since these initial labels are partially erroneous, we use active learning strategies to cost-efficiently refine the labels in the second step. We evaluate the active learning strategies using satellite images of Bengaluru in India, labelled with land cover and land use labels. Our experimental results suggest that an active label refinement to improve the semantic segmentation network's performance is beneficial.
Fast Bayesian Updates for Deep Learning with a Use Case in Active Learning
Oct 12, 2022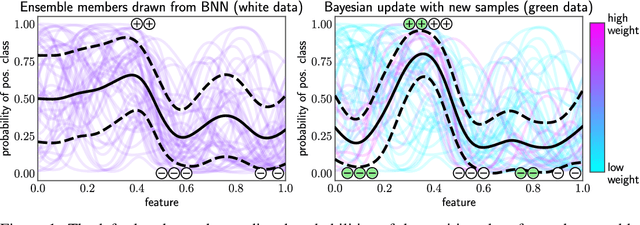
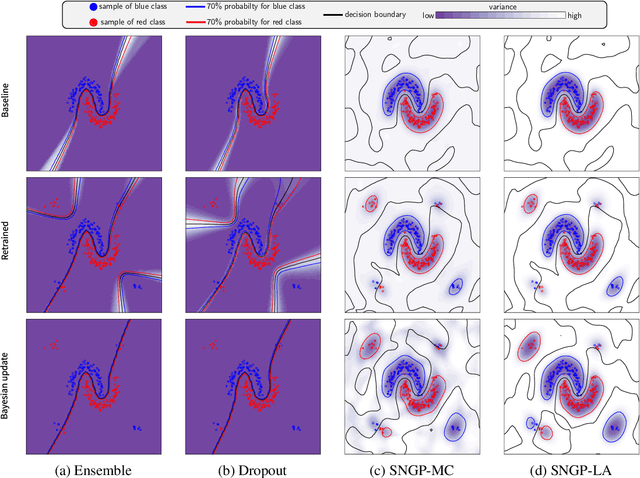
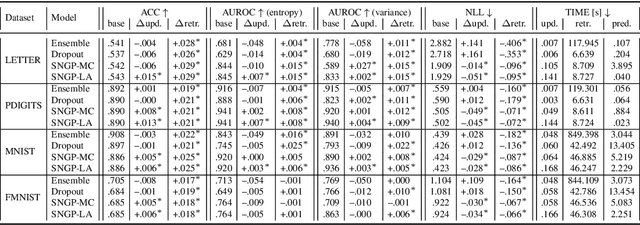
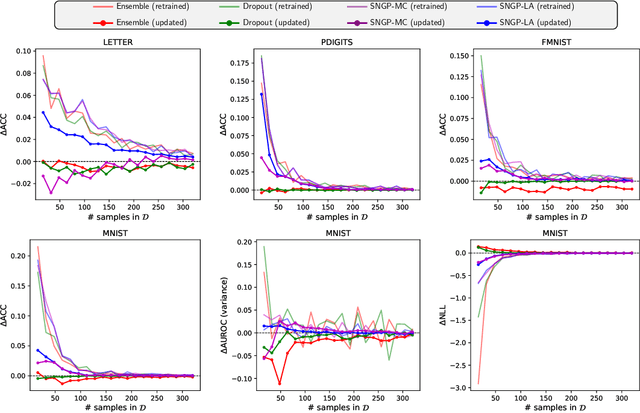
Retraining deep neural networks when new data arrives is typically computationally expensive. Moreover, certain applications do not allow such costly retraining due to time or computational constraints. Fast Bayesian updates are a possible solution to this issue. Therefore, we propose a Bayesian update based on Monte-Carlo samples and a last-layer Laplace approximation for different Bayesian neural network types, i.e., Dropout, Ensemble, and Spectral Normalized Neural Gaussian Process (SNGP). In a large-scale evaluation study, we show that our updates combined with SNGP represent a fast and competitive alternative to costly retraining. As a use case, we combine the Bayesian updates for SNGP with different sequential query strategies to exemplarily demonstrate their improved selection performance in active learning.
Probabilistic Active Learning for Active Class Selection
Aug 09, 2021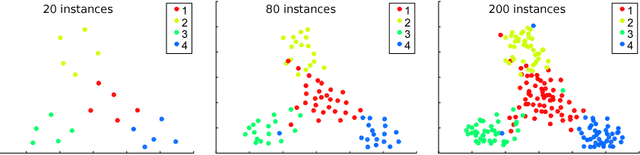
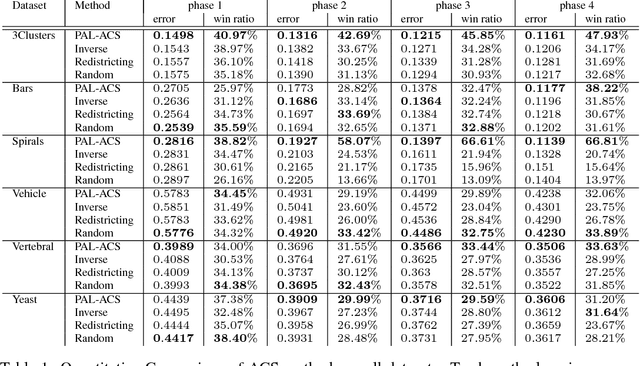
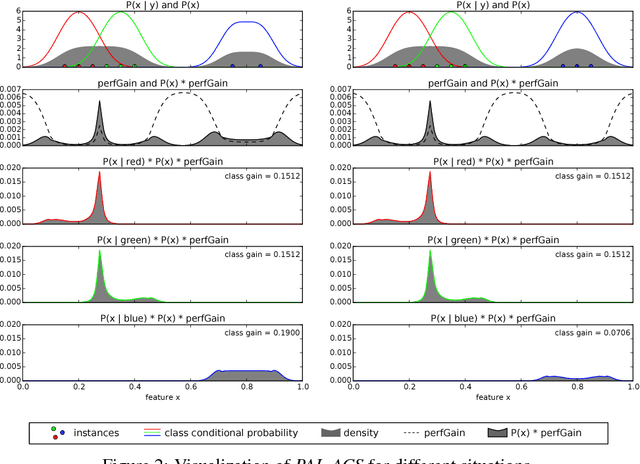
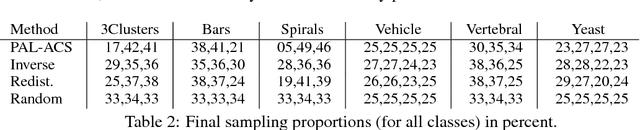
In machine learning, active class selection (ACS) algorithms aim to actively select a class and ask the oracle to provide an instance for that class to optimize a classifier's performance while minimizing the number of requests. In this paper, we propose a new algorithm (PAL-ACS) that transforms the ACS problem into an active learning task by introducing pseudo instances. These are used to estimate the usefulness of an upcoming instance for each class using the performance gain model from probabilistic active learning. Our experimental evaluation (on synthetic and real data) shows the advantages of our algorithm compared to state-of-the-art algorithms. It effectively prefers the sampling of difficult classes and thereby improves the classification performance.
Efficient SVDD Sampling with Approximation Guarantees for the Decision Boundary
Sep 29, 2020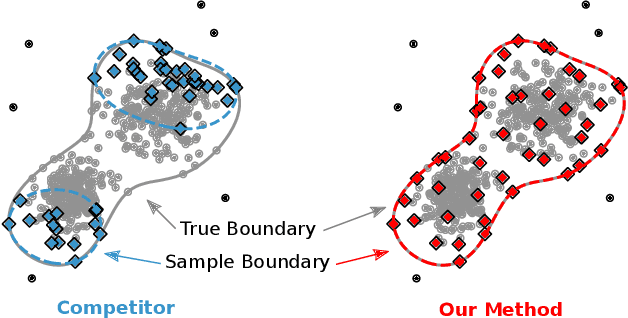
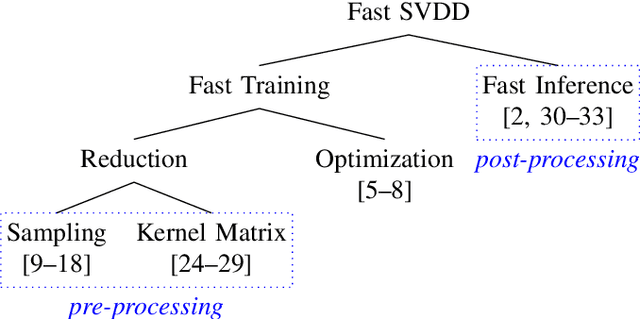
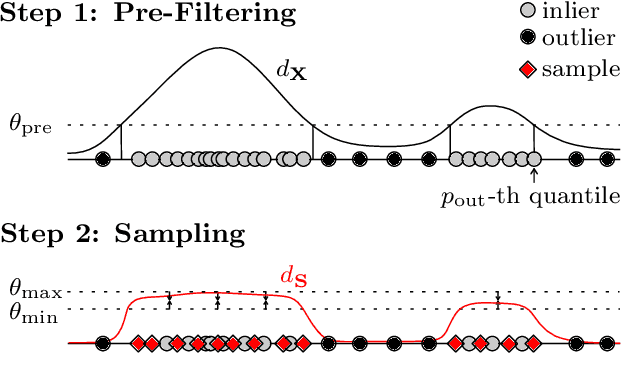
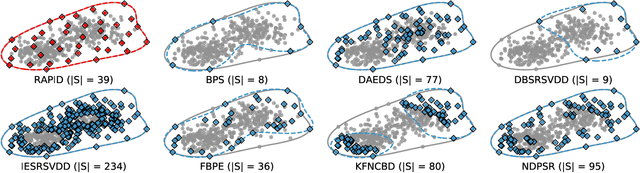
Support Vector Data Description (SVDD) is a popular one-class classifiers for anomaly and novelty detection. But despite its effectiveness, SVDD does not scale well with data size. To avoid prohibitive training times, sampling methods select small subsets of the training data on which SVDD trains a decision boundary hopefully equivalent to the one obtained on the full data set. According to the literature, a good sample should therefore contain so-called boundary observations that SVDD would select as support vectors on the full data set. However, non-boundary observations also are essential to not fragment contiguous inlier regions and avoid poor classification accuracy. Other aspects, such as selecting a sufficiently representative sample, are important as well. But existing sampling methods largely overlook them, resulting in poor classification accuracy. In this article, we study how to select a sample considering these points. Our approach is to frame SVDD sampling as an optimization problem, where constraints guarantee that sampling indeed approximates the original decision boundary. We then propose RAPID, an efficient algorithm to solve this optimization problem. RAPID does not require any tuning of parameters, is easy to implement and scales well to large data sets. We evaluate our approach on real-world and synthetic data. Our evaluation is the most comprehensive one for SVDD sampling so far. Our results show that RAPID outperforms its competitors in classification accuracy, in sample size, and in runtime.
Toward Optimal Probabilistic Active Learning Using a Bayesian Approach
Jun 02, 2020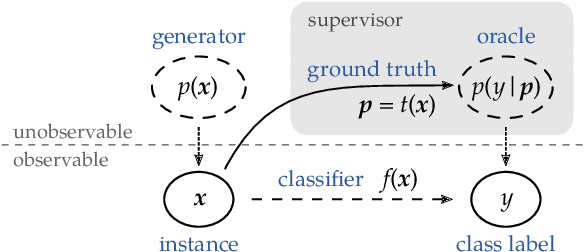
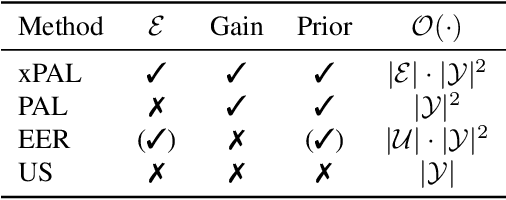
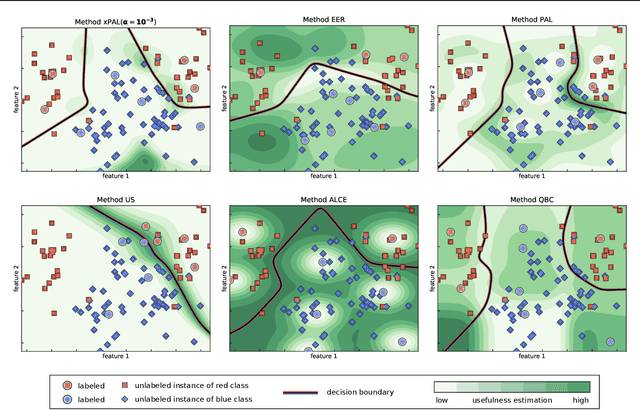
Gathering labeled data to train well-performing machine learning models is one of the critical challenges in many applications. Active learning aims at reducing the labeling costs by an efficient and effective allocation of costly labeling resources. In this article, we propose a decision-theoretic selection strategy that (1) directly optimizes the gain in misclassification error, and (2) uses a Bayesian approach by introducing a conjugate prior distribution to determine the class posterior to deal with uncertainties. By reformulating existing selection strategies within our proposed model, we can explain which aspects are not covered in current state-of-the-art and why this leads to the superior performance of our approach. Extensive experiments on a large variety of datasets and different kernels validate our claims.
Limitations of Assessing Active Learning Performance at Runtime
Jan 29, 2019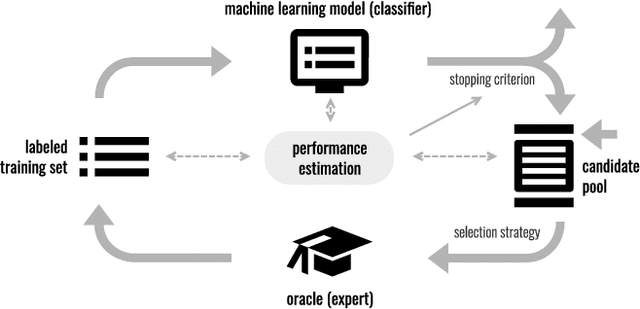
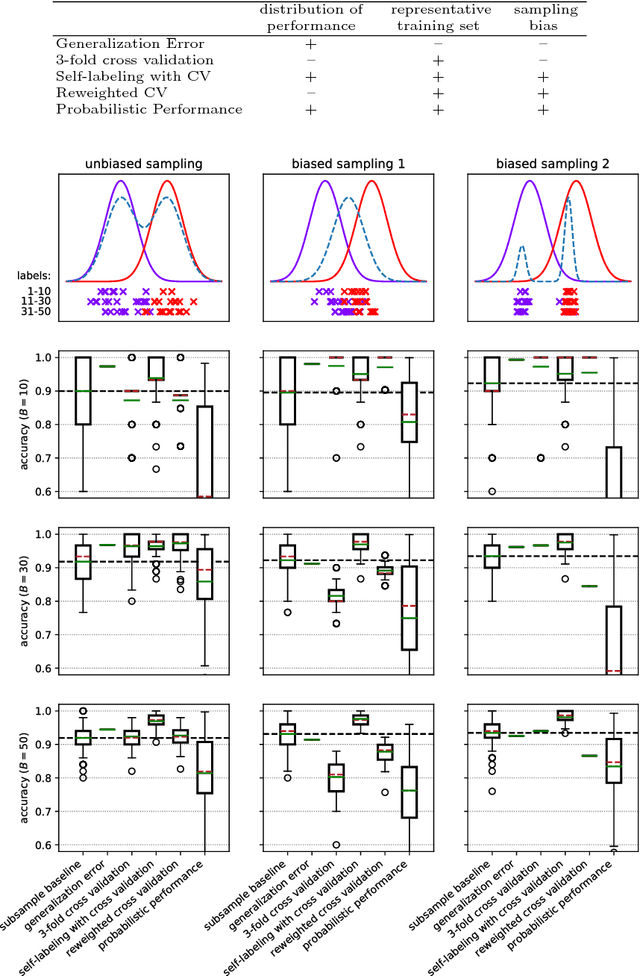
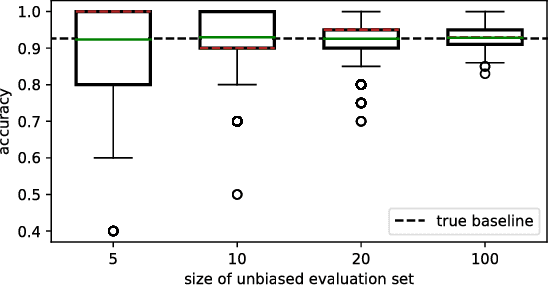
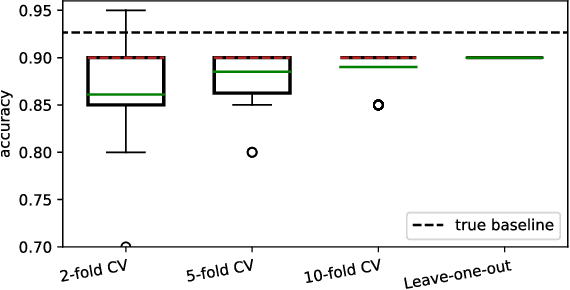
Classification algorithms aim to predict an unknown label (e.g., a quality class) for a new instance (e.g., a product). Therefore, training samples (instances and labels) are used to deduct classification hypotheses. Often, it is relatively easy to capture instances but the acquisition of the corresponding labels remain difficult or expensive. Active learning algorithms select the most beneficial instances to be labeled to reduce cost. In research, this labeling procedure is simulated and therefore a ground truth is available. But during deployment, active learning is a one-shot problem and an evaluation set is not available. Hence, it is not possible to reliably estimate the performance of the classification system during learning and it is difficult to decide when the system fulfills the quality requirements (stopping criteria). In this article, we formalize the task and review existing strategies to assess the performance of an actively trained classifier during training. Furthermore, we identified three major challenges: 1)~to derive a performance distribution, 2)~to preserve representativeness of the labeled subset, and 3) to correct against sampling bias induced by an intelligent selection strategy. In a qualitative analysis, we evaluate different existing approaches and show that none of them reliably estimates active learning performance stating a major challenge for future research for such systems. All plots and experiments are provided in a Jupyter notebook that is available for download.