 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining and Validating a Treatment Recommender with Partial Verification Evidence
Jun 10, 2024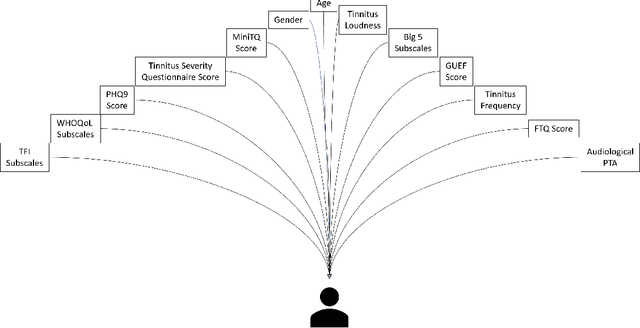

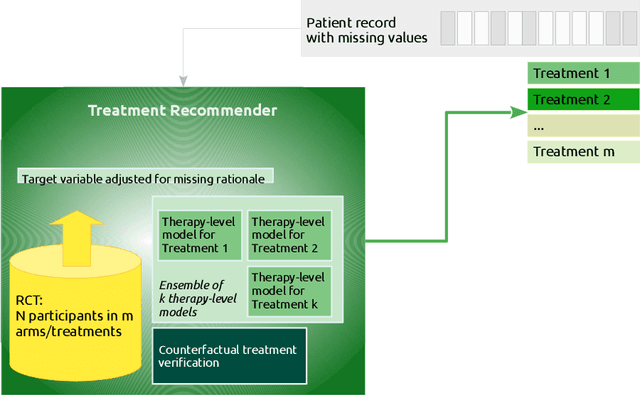

Current clinical decision support systems (DSS) are trained and validated on observational data from the target clinic. This is problematic for treatments validated in a randomized clinical trial (RCT), but not yet introduced in any clinic. In this work, we report on a method for training and validating the DSS using the RCT data. The key challenges we address are of missingness -- missing rationale for treatment assignment (the assignment is at random), and missing verification evidence, since the effectiveness of a treatment for a patient can only be verified (ground truth) for treatments what were actually assigned to a patient. We use data from a multi-armed RCT that investigated the effectiveness of single- and combination- treatments for 240+ tinnitus patients recruited and treated in 5 clinical centers. To deal with the 'missing rationale' challenge, we re-model the target variable (outcome) in order to suppress the effect of the randomly-assigned treatment, and control on the effect of treatment in general. Our methods are also robust to missing values in features and with a small number of patients per RCT arm. We deal with 'missing verification evidence' by using counterfactual treatment verification, which compares the effectiveness of the DSS recommendations to the effectiveness of the RCT assignments when they are aligned v/s not aligned. We demonstrate that our approach leverages the RCT data for learning and verification, by showing that the DSS suggests treatments that improve the outcome. The results are limited through the small number of patients per treatment; while our ensemble is designed to mitigate this effect, the predictive performance of the methods is affected by the smallness of the data. We provide a basis for the establishment of decision supporting routines on treatments that have been tested in RCTs but have not yet been deployed clinically.
A cost-based multi-layer network approach for the discovery of patient phenotypes
Sep 20, 2022
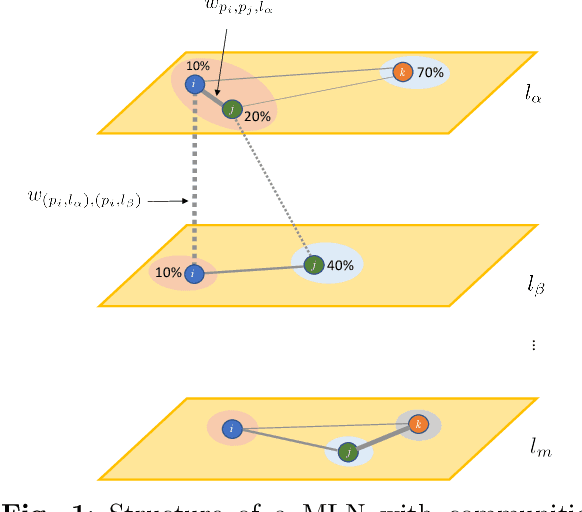
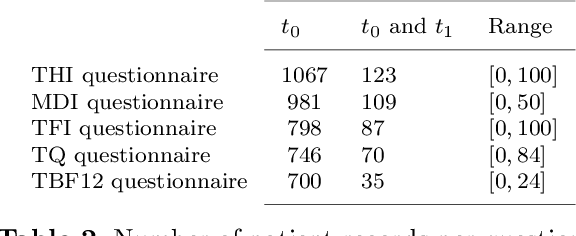
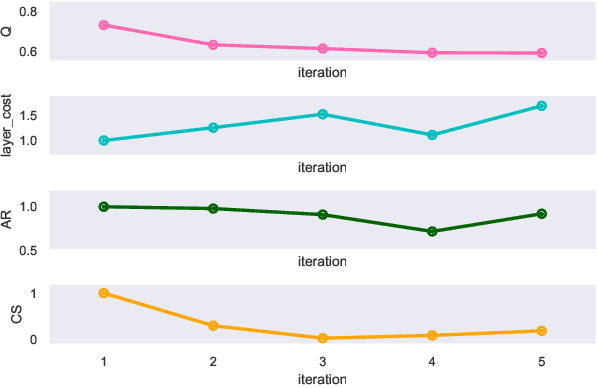
Clinical records frequently include assessments of the characteristics of patients, which may include the completion of various questionnaires. These questionnaires provide a variety of perspectives on a patient's current state of well-being. Not only is it critical to capture the heterogeneity given by these perspectives, but there is also a growing demand for developing cost-effective technologies for clinical phenotyping. Filling out many questionnaires may be a strain for the patients and therefore costly. In this work, we propose COBALT -- a cost-based layer selector model for detecting phenotypes using a community detection approach. Our goal is to minimize the number of features used to build these phenotypes while preserving its quality. We test our model using questionnaire data from chronic tinnitus patients and represent the data in a multi-layer network structure. The model is then evaluated by predicting post-treatment data using baseline features (age, gender, and pre-treatment data) as well as the identified phenotypes as a feature. For some post-treatment variables, predictors using phenotypes from COBALT as features outperformed those using phenotypes detected by traditional clustering methods. Moreover, using phenotype data to predict post-treatment data proved beneficial in comparison with predictors that were solely trained with baseline features.
Probabilistic Active Learning for Active Class Selection
Aug 09, 2021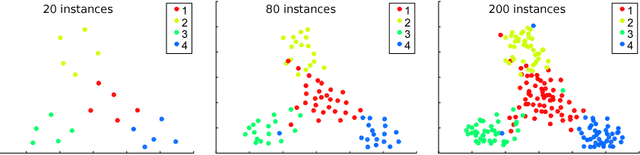
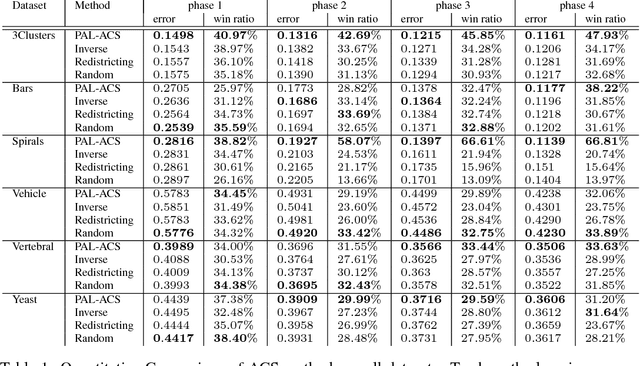
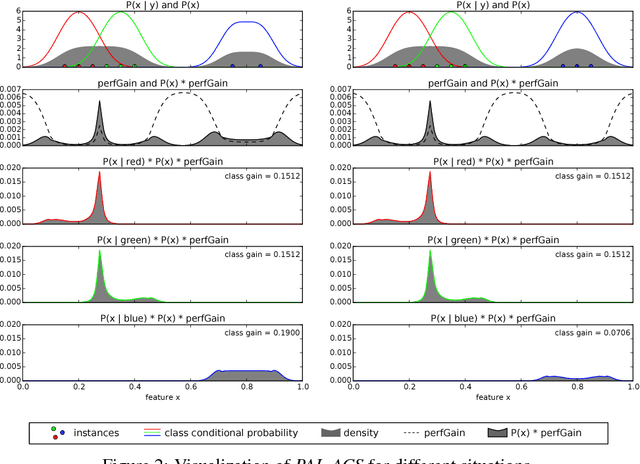
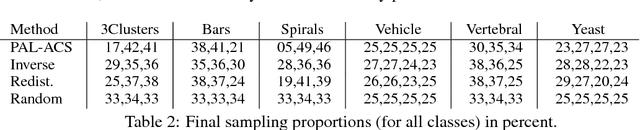
In machine learning, active class selection (ACS) algorithms aim to actively select a class and ask the oracle to provide an instance for that class to optimize a classifier's performance while minimizing the number of requests. In this paper, we propose a new algorithm (PAL-ACS) that transforms the ACS problem into an active learning task by introducing pseudo instances. These are used to estimate the usefulness of an upcoming instance for each class using the performance gain model from probabilistic active learning. Our experimental evaluation (on synthetic and real data) shows the advantages of our algorithm compared to state-of-the-art algorithms. It effectively prefers the sampling of difficult classes and thereby improves the classification performance.
A Framework for Authorial Clustering of Shorter Texts in Latent Semantic Spaces
Nov 30, 2020
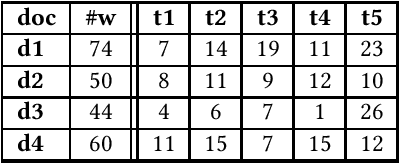

Authorial clustering involves the grouping of documents written by the same author or team of authors without any prior positive examples of an author's writing style or thematic preferences. For authorial clustering on shorter texts (paragraph-length texts that are typically shorter than conventional documents), the document representation is particularly important: very high-dimensional feature spaces lead to data sparsity and suffer from serious consequences like the curse of dimensionality, while feature selection may lead to information loss. We propose a high-level framework which utilizes a compact data representation in a latent feature space derived with non-parametric topic modeling. Authorial clusters are identified thereafter in two scenarios: (a) fully unsupervised and (b) semi-supervised where a small number of shorter texts are known to belong to the same author (must-link constraints) or not (cannot-link constraints). We report on experiments with 120 collections in three languages and two genres and show that the topic-based latent feature space provides a promising level of performance while reducing the dimensionality by a factor of 1500 compared to state-of-the-arts. We also demonstrate that, while prior knowledge on the precise number of authors (i.e. authorial clusters) does not contribute much to additional quality, little knowledge on constraints in authorial clusters memberships leads to clear performance improvements in front of this difficult task. Thorough experimentation with standard metrics indicates that there still remains an ample room for improvement for authorial clustering, especially with shorter texts
Cardiac Cohort Classification based on Morphologic and Hemodynamic Parameters extracted from 4D PC-MRI Data
Oct 12, 2020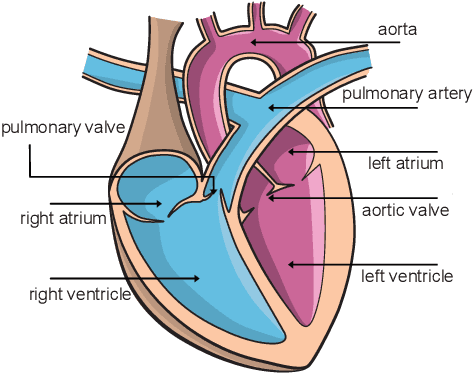

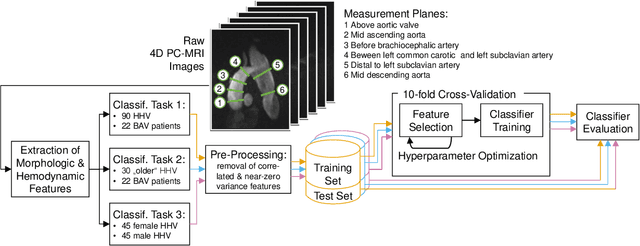

An accurate assessment of the cardiovascular system and prediction of cardiovascular diseases (CVDs) are crucial. Measured cardiac blood flow data provide insights about patient-specific hemodynamics, where many specialized techniques have been developed for the visual exploration of such data sets to better understand the influence of morphological and hemodynamic conditions on CVDs. However, there is a lack of machine learning approaches techniques that allow a feature-based classification of heart-healthy people and patients with CVDs.In this work, we investigate the potential of morphological and hemodynamic characteristics, extracted from measured blood flow data in the aorta, for the classification of heart-healthy volunteers and patients with bicuspid aortic valve (BAV). Furthermore, we research if there are characteristic features to classify male and female as well as younger and older heart-healthy volunteers. We propose a data analysis pipeline for the classification of the cardiac status, encompassing feature selection, model training and hyperparameter tuning. In our experiments, we use several feature selection methods and classification algorithms to train separate models for the healthy subgroups and BAV patients. We report on classification performance and investigate the predictive power of morphological and hemodynamic features with regard to the classification oft he defined groups. Finally, we identify the key features for the best models.
Incremental Active Opinion Learning Over a Stream of Opinionated Documents
Sep 03, 2015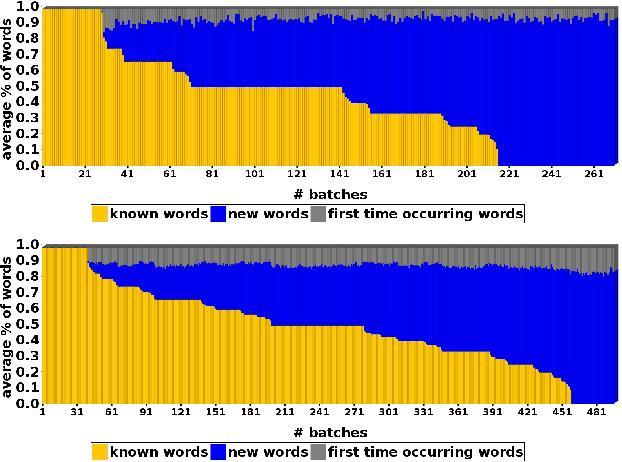

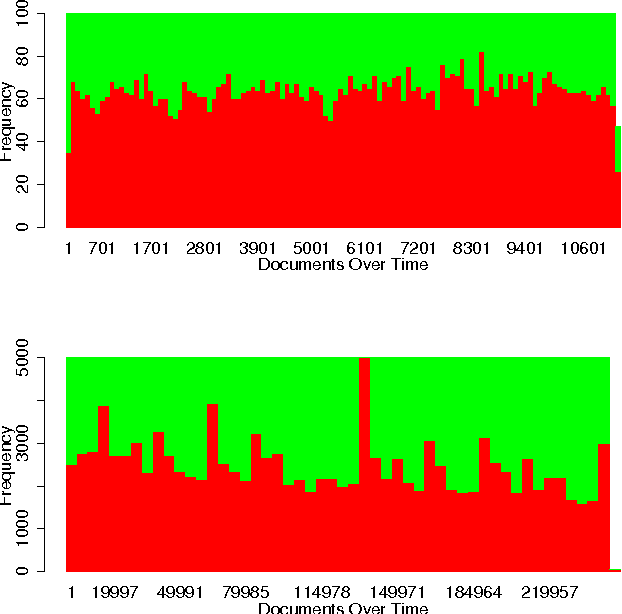
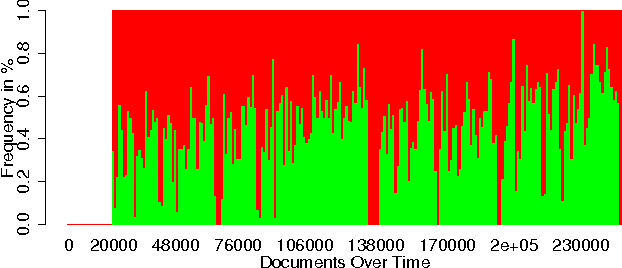
Applications that learn from opinionated documents, like tweets or product reviews, face two challenges. First, the opinionated documents constitute an evolving stream, where both the author's attitude and the vocabulary itself may change. Second, labels of documents are scarce and labels of words are unreliable, because the sentiment of a word depends on the (unknown) context in the author's mind. Most of the research on mining over opinionated streams focuses on the first aspect of the problem, whereas for the second a continuous supply of labels from the stream is assumed. Such an assumption though is utopian as the stream is infinite and the labeling cost is prohibitive. To this end, we investigate the potential of active stream learning algorithms that ask for labels on demand. Our proposed ACOSTREAM 1 approach works with limited labels: it uses an initial seed of labeled documents, occasionally requests additional labels for documents from the human expert and incrementally adapts to the underlying stream while exploiting the available labeled documents. In its core, ACOSTREAM consists of a MNB classifier coupled with "sampling" strategies for requesting class labels for new unlabeled documents. In the experiments, we evaluate the classifier performance over time by varying: (a) the class distribution of the opinionated stream, while assuming that the set of the words in the vocabulary is fixed but their polarities may change with the class distribution; and (b) the number of unknown words arriving at each moment, while the class polarity may also change. Our results show that active learning on a stream of opinionated documents, delivers good performance while requiring a small selection of labels
Data Mining to Measure and Improve the Success of Web Sites
Aug 15, 2000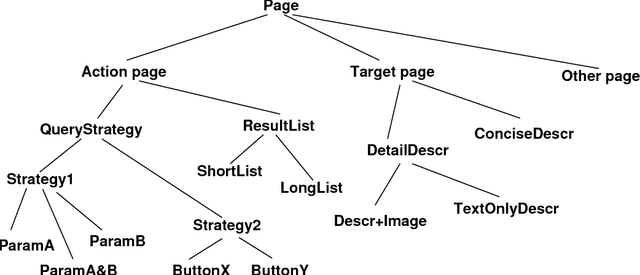



For many companies, competitiveness in e-commerce requires a successful presence on the web. Web sites are used to establish the company's image, to promote and sell goods and to provide customer support. The success of a web site affects and reflects directly the success of the company in the electronic market. In this study, we propose a methodology to improve the ``success'' of web sites, based on the exploitation of navigation pattern discovery. In particular, we present a theory, in which success is modelled on the basis of the navigation behaviour of the site's users. We then exploit WUM, a navigation pattern discovery miner, to study how the success of a site is reflected in the users' behaviour. With WUM we measure the success of a site's components and obtain concrete indications of how the site should be improved. We report on our first experiments with an online catalog, the success of which we have studied. Our mining analysis has shown very promising results, on the basis of which the site is currently undergoing concrete improvements.