 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMM-fair: An Interactive Toolkit for Exploring and Operationalizing Multi-Fairness Trade-offs
Sep 09, 2025Fairness-aware classification requires balancing performance and fairness, often intensified by intersectional biases. Conflicting fairness definitions further complicate the task, making it difficult to identify universally fair solutions. Despite growing regulatory and societal demands for equitable AI, popular toolkits offer limited support for exploring multi-dimensional fairness and related trade-offs. To address this, we present mmm-fair, an open-source toolkit leveraging boosting-based ensemble approaches that dynamically optimizes model weights to jointly minimize classification errors and diverse fairness violations, enabling flexible multi-objective optimization. The system empowers users to deploy models that align with their context-specific needs while reliably uncovering intersectional biases often missed by state-of-the-art methods. In a nutshell, mmm-fair uniquely combines in-depth multi-attribute fairness, multi-objective optimization, a no-code, chat-based interface, LLM-powered explanations, interactive Pareto exploration for model selection, custom fairness constraint definition, and deployment-ready models in a single open-source toolkit, a combination rarely found in existing fairness tools. Demo walkthrough available at: https://youtu.be/_rcpjlXFqkw.
Achieving Hilbert-Schmidt Independence Under Rényi Differential Privacy for Fair and Private Data Generation
Aug 29, 2025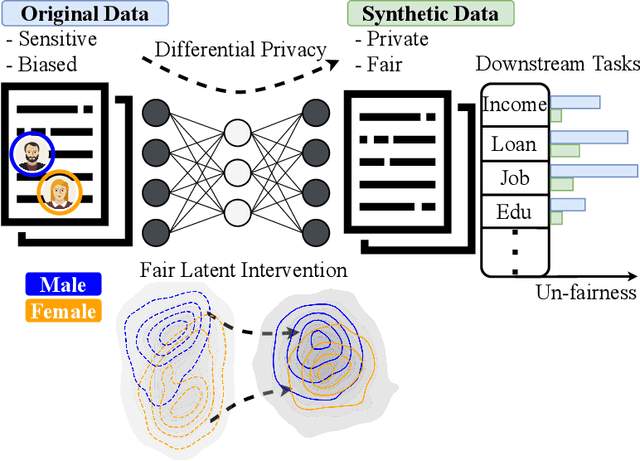
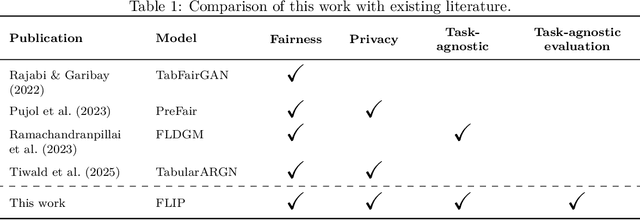
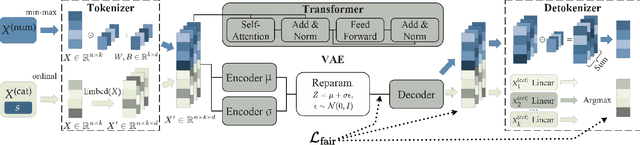

As privacy regulations such as the GDPR and HIPAA and responsibility frameworks for artificial intelligence such as the AI Act gain traction, the ethical and responsible use of real-world data faces increasing constraints. Synthetic data generation has emerged as a promising solution to risk-aware data sharing and model development, particularly for tabular datasets that are foundational to sensitive domains such as healthcare. To address both privacy and fairness concerns in this setting, we propose FLIP (Fair Latent Intervention under Privacy guarantees), a transformer-based variational autoencoder augmented with latent diffusion to generate heterogeneous tabular data. Unlike the typical setup in fairness-aware data generation, we assume a task-agnostic setup, not reliant on a fixed, defined downstream task, thus offering broader applicability. To ensure privacy, FLIP employs R\'enyi differential privacy (RDP) constraints during training and addresses fairness in the input space with RDP-compatible balanced sampling that accounts for group-specific noise levels across multiple sampling rates. In the latent space, we promote fairness by aligning neuron activation patterns across protected groups using Centered Kernel Alignment (CKA), a similarity measure extending the Hilbert-Schmidt Independence Criterion (HSIC). This alignment encourages statistical independence between latent representations and the protected feature. Empirical results demonstrate that FLIP effectively provides significant fairness improvements for task-agnostic fairness and across diverse downstream tasks under differential privacy constraints.
ALMA: Aggregated Lipschitz Maximization Attack on Auto-encoders
May 06, 2025Despite the extensive use of deep autoencoders (AEs) in critical applications, their adversarial robustness remains relatively underexplored compared to classification models. AE robustness is characterized by the Lipschitz bounds of its components. Existing robustness evaluation frameworks based on white-box attacks do not fully exploit the vulnerabilities of intermediate ill-conditioned layers in AEs. In the context of optimizing imperceptible norm-bounded additive perturbations to maximize output damage, existing methods struggle to effectively propagate adversarial loss gradients throughout the network, often converging to less effective perturbations. To address this, we propose a novel layer-conditioning-based adversarial optimization objective that effectively guides the adversarial map toward regions of local Lipschitz bounds by enhancing loss gradient information propagation during attack optimization. We demonstrate through extensive experiments on state-of-the-art AEs that our adversarial objective results in stronger attacks, outperforming existing methods in both universal and sample-specific scenarios. As a defense method against this attack, we introduce an inference-time adversarially trained defense plugin that mitigates the effects of adversarial examples.
Explanations as Bias Detectors: A Critical Study of Local Post-hoc XAI Methods for Fairness Exploration
May 01, 2025As Artificial Intelligence (AI) is increasingly used in areas that significantly impact human lives, concerns about fairness and transparency have grown, especially regarding their impact on protected groups. Recently, the intersection of explainability and fairness has emerged as an important area to promote responsible AI systems. This paper explores how explainability methods can be leveraged to detect and interpret unfairness. We propose a pipeline that integrates local post-hoc explanation methods to derive fairness-related insights. During the pipeline design, we identify and address critical questions arising from the use of explanations as bias detectors such as the relationship between distributive and procedural fairness, the effect of removing the protected attribute, the consistency and quality of results across different explanation methods, the impact of various aggregation strategies of local explanations on group fairness evaluations, and the overall trustworthiness of explanations as bias detectors. Our results show the potential of explanation methods used for fairness while highlighting the need to carefully consider the aforementioned critical aspects.
Emerging Security Challenges of Large Language Models
Dec 23, 2024Large language models (LLMs) have achieved record adoption in a short period of time across many different sectors including high importance areas such as education [4] and healthcare [23]. LLMs are open-ended models trained on diverse data without being tailored for specific downstream tasks, enabling broad applicability across various domains. They are commonly used for text generation, but also widely used to assist with code generation [3], and even analysis of security information, as Microsoft Security Copilot demonstrates [18]. Traditional Machine Learning (ML) models are vulnerable to adversarial attacks [9]. So the concerns on the potential security implications of such wide scale adoption of LLMs have led to the creation of this working group on the security of LLMs. During the Dagstuhl seminar on "Network Attack Detection and Defense - AI-Powered Threats and Responses", the working group discussions focused on the vulnerability of LLMs to adversarial attacks, rather than their potential use in generating malware or enabling cyberattacks. Although we note the potential threat represented by the latter, the role of the LLMs in such uses is mostly as an accelerator for development, similar to what it is in benign use. To make the analysis more specific, the working group employed ChatGPT as a concrete example of an LLM and addressed the following points, which also form the structure of this report: 1. How do LLMs differ in vulnerabilities from traditional ML models? 2. What are the attack objectives in LLMs? 3. How complex it is to assess the risks posed by the vulnerabilities of LLMs? 4. What is the supply chain in LLMs, how data flow in and out of systems and what are the security implications? We conclude with an overview of open challenges and outlook.
Unlocking LLMs: Addressing Scarce Data and Bias Challenges in Mental Health
Dec 17, 2024



Large language models (LLMs) have shown promising capabilities in healthcare analysis but face several challenges like hallucinations, parroting, and bias manifestation. These challenges are exacerbated in complex, sensitive, and low-resource domains. Therefore, in this work we introduce IC-AnnoMI, an expert-annotated motivational interviewing (MI) dataset built upon AnnoMI by generating in-context conversational dialogues leveraging LLMs, particularly ChatGPT. IC-AnnoMI employs targeted prompts accurately engineered through cues and tailored information, taking into account therapy style (empathy, reflection), contextual relevance, and false semantic change. Subsequently, the dialogues are annotated by experts, strictly adhering to the Motivational Interviewing Skills Code (MISC), focusing on both the psychological and linguistic dimensions of MI dialogues. We comprehensively evaluate the IC-AnnoMI dataset and ChatGPT's emotional reasoning ability and understanding of domain intricacies by modeling novel classification tasks employing several classical machine learning and current state-of-the-art transformer approaches. Finally, we discuss the effects of progressive prompting strategies and the impact of augmented data in mitigating the biases manifested in IC-AnnoM. Our contributions provide the MI community with not only a comprehensive dataset but also valuable insights for using LLMs in empathetic text generation for conversational therapy in supervised settings.
Shape error prediction in 5-axis machining using graph neural networks
Dec 13, 2024



This paper presents an innovative method for predicting shape errors in 5-axis machining using graph neural networks. The graph structure is defined with nodes representing workpiece surface points and edges denoting the neighboring relationships. The dataset encompasses data from a material removal simulation, process data, and post-machining quality information. Experimental results show that the presented approach can generalize the shape error prediction for the investigated workpiece geometry. Moreover, by modelling spatial and temporal connections within the workpiece, the approach handles a low number of labels compared to non-graphical methods such as Support Vector Machines.
Transparent Neighborhood Approximation for Text Classifier Explanation
Nov 25, 2024



Recent literature highlights the critical role of neighborhood construction in deriving model-agnostic explanations, with a growing trend toward deploying generative models to improve synthetic instance quality, especially for explaining text classifiers. These approaches overcome the challenges in neighborhood construction posed by the unstructured nature of texts, thereby improving the quality of explanations. However, the deployed generators are usually implemented via neural networks and lack inherent explainability, sparking arguments over the transparency of the explanation process itself. To address this limitation while preserving neighborhood quality, this paper introduces a probability-based editing method as an alternative to black-box text generators. This approach generates neighboring texts by implementing manipulations based on in-text contexts. Substituting the generator-based construction process with recursive probability-based editing, the resultant explanation method, XPROB (explainer with probability-based editing), exhibits competitive performance according to the evaluation conducted on two real-world datasets. Additionally, XPROB's fully transparent and more controllable construction process leads to superior stability compared to the generator-based explainers.
TABCF: Counterfactual Explanations for Tabular Data Using a Transformer-Based VAE
Oct 14, 2024In the field of Explainable AI (XAI), counterfactual (CF) explanations are one prominent method to interpret a black-box model by suggesting changes to the input that would alter a prediction. In real-world applications, the input is predominantly in tabular form and comprised of mixed data types and complex feature interdependencies. These unique data characteristics are difficult to model, and we empirically show that they lead to bias towards specific feature types when generating CFs. To overcome this issue, we introduce TABCF, a CF explanation method that leverages a transformer-based Variational Autoencoder (VAE) tailored for modeling tabular data. Our approach uses transformers to learn a continuous latent space and a novel Gumbel-Softmax detokenizer that enables precise categorical reconstruction while preserving end-to-end differentiability. Extensive quantitative evaluation on five financial datasets demonstrates that TABCF does not exhibit bias toward specific feature types, and outperforms existing methods in producing effective CFs that align with common CF desiderata.
Synthetic Tabular Data Generation for Class Imbalance and Fairness: A Comparative Study
Sep 08, 2024



Due to their data-driven nature, Machine Learning (ML) models are susceptible to bias inherited from data, especially in classification problems where class and group imbalances are prevalent. Class imbalance (in the classification target) and group imbalance (in protected attributes like sex or race) can undermine both ML utility and fairness. Although class and group imbalances commonly coincide in real-world tabular datasets, limited methods address this scenario. While most methods use oversampling techniques, like interpolation, to mitigate imbalances, recent advancements in synthetic tabular data generation offer promise but have not been adequately explored for this purpose. To this end, this paper conducts a comparative analysis to address class and group imbalances using state-of-the-art models for synthetic tabular data generation and various sampling strategies. Experimental results on four datasets, demonstrate the effectiveness of generative models for bias mitigation, creating opportunities for further exploration in this direction.