 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStealthy Poisoning Attacks Bypass Defenses in Regression Settings
Jan 29, 2026Regression models are widely used in industrial processes, engineering and in natural and physical sciences, yet their robustness to poisoning has received less attention. When it has, studies often assume unrealistic threat models and are thus less useful in practice. In this paper, we propose a novel optimal stealthy attack formulation that considers different degrees of detectability and show that it bypasses state-of-the-art defenses. We further propose a new methodology based on normalization of objectives to evaluate different trade-offs between effectiveness and detectability. Finally, we develop a novel defense (BayesClean) against stealthy attacks. BayesClean improves on previous defenses when attacks are stealthy and the number of poisoning points is significant.
Incident Response Planning Using a Lightweight Large Language Model with Reduced Hallucination
Aug 07, 2025Timely and effective incident response is key to managing the growing frequency of cyberattacks. However, identifying the right response actions for complex systems is a major technical challenge. A promising approach to mitigate this challenge is to use the security knowledge embedded in large language models (LLMs) to assist security operators during incident handling. Recent research has demonstrated the potential of this approach, but current methods are mainly based on prompt engineering of frontier LLMs, which is costly and prone to hallucinations. We address these limitations by presenting a novel way to use an LLM for incident response planning with reduced hallucination. Our method includes three steps: fine-tuning, information retrieval, and lookahead planning. We prove that our method generates response plans with a bounded probability of hallucination and that this probability can be made arbitrarily small at the expense of increased planning time under certain assumptions. Moreover, we show that our method is lightweight and can run on commodity hardware. We evaluate our method on logs from incidents reported in the literature. The experimental results show that our method a) achieves up to 22% shorter recovery times than frontier LLMs and b) generalizes to a broad range of incident types and response actions.
Emerging Security Challenges of Large Language Models
Dec 23, 2024Large language models (LLMs) have achieved record adoption in a short period of time across many different sectors including high importance areas such as education [4] and healthcare [23]. LLMs are open-ended models trained on diverse data without being tailored for specific downstream tasks, enabling broad applicability across various domains. They are commonly used for text generation, but also widely used to assist with code generation [3], and even analysis of security information, as Microsoft Security Copilot demonstrates [18]. Traditional Machine Learning (ML) models are vulnerable to adversarial attacks [9]. So the concerns on the potential security implications of such wide scale adoption of LLMs have led to the creation of this working group on the security of LLMs. During the Dagstuhl seminar on "Network Attack Detection and Defense - AI-Powered Threats and Responses", the working group discussions focused on the vulnerability of LLMs to adversarial attacks, rather than their potential use in generating malware or enabling cyberattacks. Although we note the potential threat represented by the latter, the role of the LLMs in such uses is mostly as an accelerator for development, similar to what it is in benign use. To make the analysis more specific, the working group employed ChatGPT as a concrete example of an LLM and addressed the following points, which also form the structure of this report: 1. How do LLMs differ in vulnerabilities from traditional ML models? 2. What are the attack objectives in LLMs? 3. How complex it is to assess the risks posed by the vulnerabilities of LLMs? 4. What is the supply chain in LLMs, how data flow in and out of systems and what are the security implications? We conclude with an overview of open challenges and outlook.
Hyperparameter Learning under Data Poisoning: Analysis of the Influence of Regularization via Multiobjective Bilevel Optimization
Jun 02, 2023



Machine Learning (ML) algorithms are vulnerable to poisoning attacks, where a fraction of the training data is manipulated to deliberately degrade the algorithms' performance. Optimal attacks can be formulated as bilevel optimization problems and help to assess their robustness in worst-case scenarios. We show that current approaches, which typically assume that hyperparameters remain constant, lead to an overly pessimistic view of the algorithms' robustness and of the impact of regularization. We propose a novel optimal attack formulation that considers the effect of the attack on the hyperparameters and models the attack as a multiobjective bilevel optimization problem. This allows to formulate optimal attacks, learn hyperparameters and evaluate robustness under worst-case conditions. We apply this attack formulation to several ML classifiers using $L_2$ and $L_1$ regularization. Our evaluation on multiple datasets confirms the limitations of previous strategies and evidences the benefits of using $L_2$ and $L_1$ regularization to dampen the effect of poisoning attacks.
Using 3D Shadows to Detect Object Hiding Attacks on Autonomous Vehicle Perception
Apr 29, 2022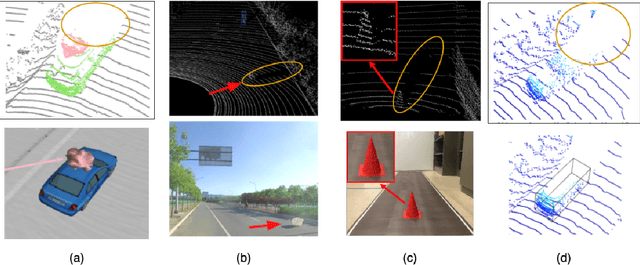

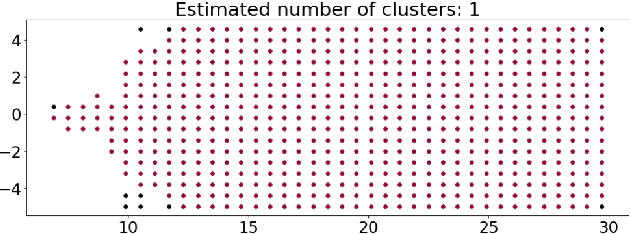
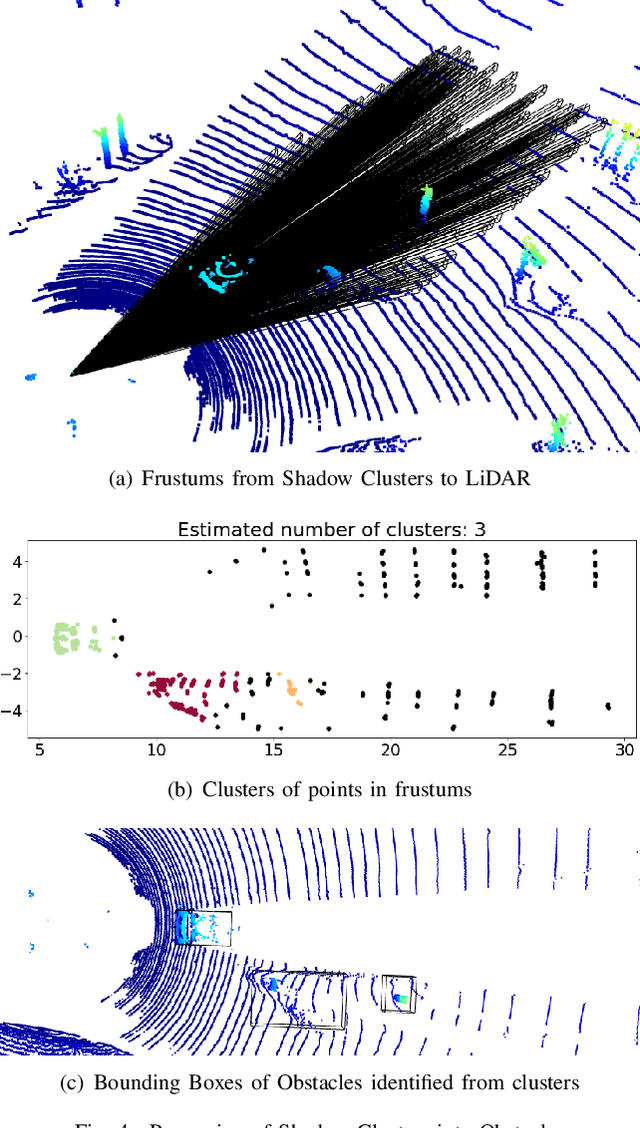
Autonomous Vehicles (AVs) are mostly reliant on LiDAR sensors which enable spatial perception of their surroundings and help make driving decisions. Recent works demonstrated attacks that aim to hide objects from AV perception, which can result in severe consequences. 3D shadows, are regions void of measurements in 3D point clouds which arise from occlusions of objects in a scene. 3D shadows were proposed as a physical invariant valuable for detecting spoofed or fake objects. In this work, we leverage 3D shadows to locate obstacles that are hidden from object detectors. We achieve this by searching for void regions and locating the obstacles that cause these shadows. Our proposed methodology can be used to detect an object that has been hidden by an adversary as these objects, while hidden from 3D object detectors, still induce shadow artifacts in 3D point clouds, which we use for obstacle detection. We show that using 3D shadows for obstacle detection can achieve high accuracy in matching shadows to their object and provide precise prediction of an obstacle's distance from the ego-vehicle.
Jacobian Ensembles Improve Robustness Trade-offs to Adversarial Attacks
Apr 19, 2022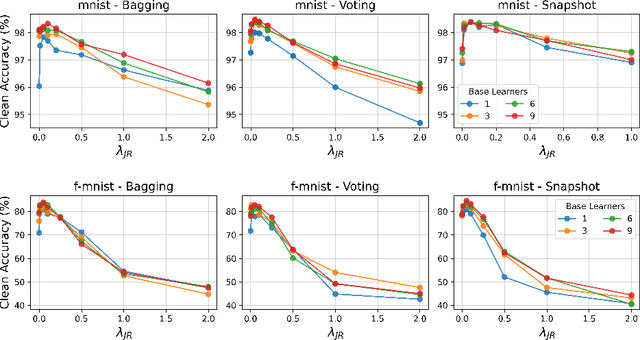

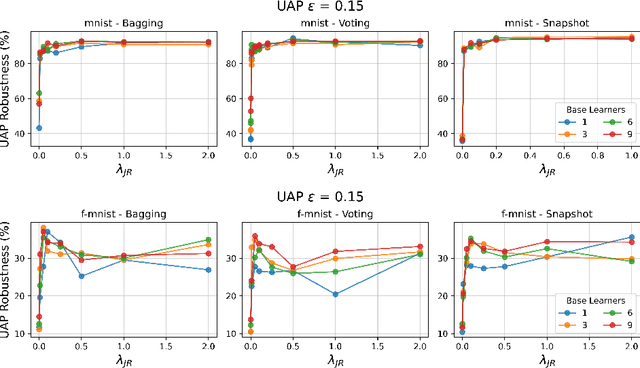

Deep neural networks have become an integral part of our software infrastructure and are being deployed in many widely-used and safety-critical applications. However, their integration into many systems also brings with it the vulnerability to test time attacks in the form of Universal Adversarial Perturbations (UAPs). UAPs are a class of perturbations that when applied to any input causes model misclassification. Although there is an ongoing effort to defend models against these adversarial attacks, it is often difficult to reconcile the trade-offs in model accuracy and robustness to adversarial attacks. Jacobian regularization has been shown to improve the robustness of models against UAPs, whilst model ensembles have been widely adopted to improve both predictive performance and model robustness. In this work, we propose a novel approach, Jacobian Ensembles-a combination of Jacobian regularization and model ensembles to significantly increase the robustness against UAPs whilst maintaining or improving model accuracy. Our results show that Jacobian Ensembles achieves previously unseen levels of accuracy and robustness, greatly improving over previous methods that tend to skew towards only either accuracy or robustness.
Regularization Can Help Mitigate Poisoning Attacks... with the Right Hyperparameters
May 23, 2021

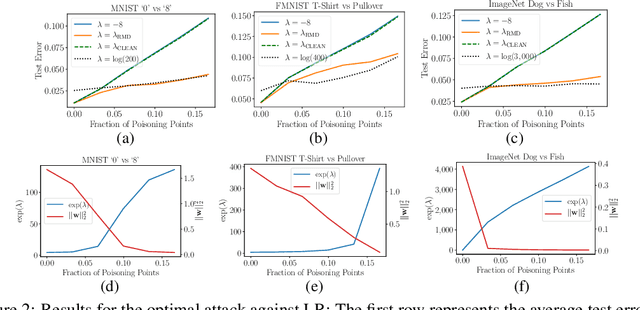
Machine learning algorithms are vulnerable to poisoning attacks, where a fraction of the training data is manipulated to degrade the algorithms' performance. We show that current approaches, which typically assume that regularization hyperparameters remain constant, lead to an overly pessimistic view of the algorithms' robustness and of the impact of regularization. We propose a novel optimal attack formulation that considers the effect of the attack on the hyperparameters, modelling the attack as a \emph{minimax bilevel optimization problem}. This allows to formulate optimal attacks, select hyperparameters and evaluate robustness under worst case conditions. We apply this formulation to logistic regression using $L_2$ regularization, empirically show the limitations of previous strategies and evidence the benefits of using $L_2$ regularization to dampen the effect of poisoning attacks.
Real-time Detection of Practical Universal Adversarial Perturbations
May 22, 2021

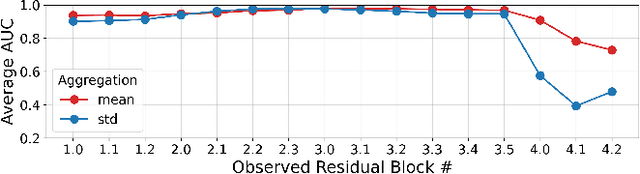
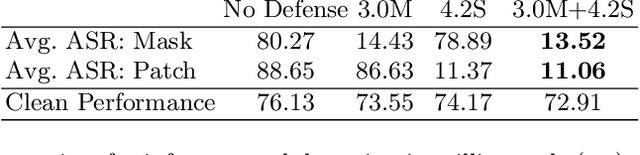
Universal Adversarial Perturbations (UAPs) are a prominent class of adversarial examples that exploit the systemic vulnerabilities and enable physically realizable and robust attacks against Deep Neural Networks (DNNs). UAPs generalize across many different inputs; this leads to realistic and effective attacks that can be applied at scale. In this paper we propose HyperNeuron, an efficient and scalable algorithm that allows for the real-time detection of UAPs by identifying suspicious neuron hyper-activations. Our results show the effectiveness of HyperNeuron on multiple tasks (image classification, object detection), against a wide variety of universal attacks, and in realistic scenarios, like perceptual ad-blocking and adversarial patches. HyperNeuron is able to simultaneously detect both adversarial mask and patch UAPs with comparable or better performance than existing UAP defenses whilst introducing a significantly reduced latency of only 0.86 milliseconds per image. This suggests that many realistic and practical universal attacks can be reliably mitigated in real-time, which shows promise for the robust deployment of machine learning systems.
Jacobian Regularization for Mitigating Universal Adversarial Perturbations
Apr 21, 2021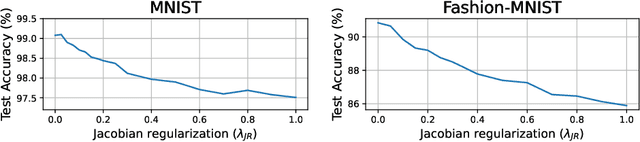
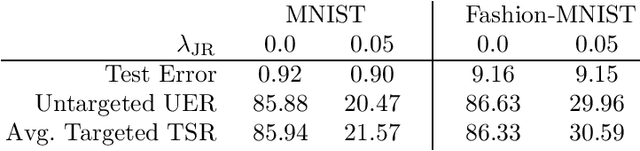
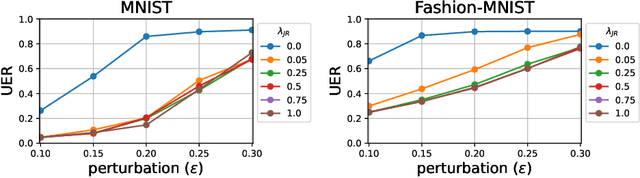
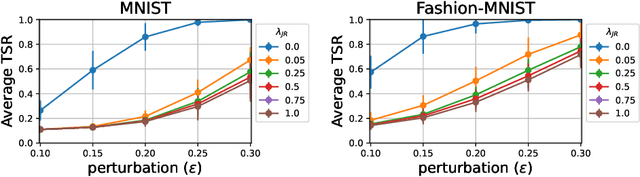
Universal Adversarial Perturbations (UAPs) are input perturbations that can fool a neural network on large sets of data. They are a class of attacks that represents a significant threat as they facilitate realistic, practical, and low-cost attacks on neural networks. In this work, we derive upper bounds for the effectiveness of UAPs based on norms of data-dependent Jacobians. We empirically verify that Jacobian regularization greatly increases model robustness to UAPs by up to four times whilst maintaining clean performance. Our theoretical analysis also allows us to formulate a metric for the strength of shared adversarial perturbations between pairs of inputs. We apply this metric to benchmark datasets and show that it is highly correlated with the actual observed robustness. This suggests that realistic and practical universal attacks can be reliably mitigated without sacrificing clean accuracy, which shows promise for the robustness of machine learning systems.
Object Removal Attacks on LiDAR-based 3D Object Detectors
Feb 07, 2021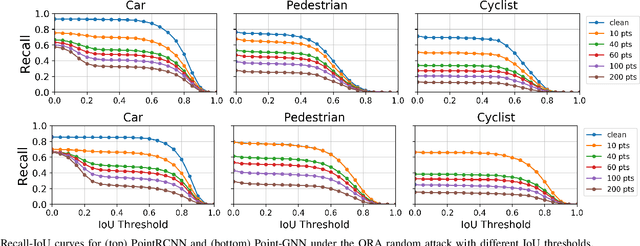
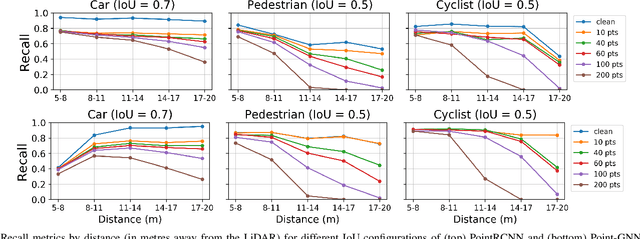
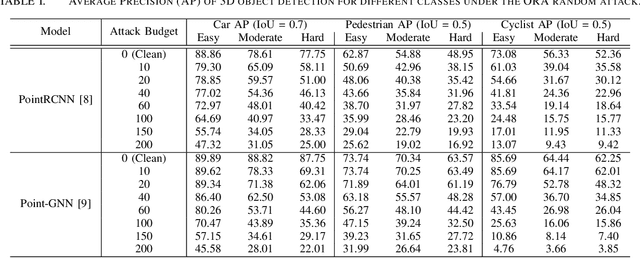
LiDARs play a critical role in Autonomous Vehicles' (AVs) perception and their safe operations. Recent works have demonstrated that it is possible to spoof LiDAR return signals to elicit fake objects. In this work we demonstrate how the same physical capabilities can be used to mount a new, even more dangerous class of attacks, namely Object Removal Attacks (ORAs). ORAs aim to force 3D object detectors to fail. We leverage the default setting of LiDARs that record a single return signal per direction to perturb point clouds in the region of interest (RoI) of 3D objects. By injecting illegitimate points behind the target object, we effectively shift points away from the target objects' RoIs. Our initial results using a simple random point selection strategy show that the attack is effective in degrading the performance of commonly used 3D object detection models.