 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStealthy Poisoning Attacks Bypass Defenses in Regression Settings
Jan 29, 2026Regression models are widely used in industrial processes, engineering and in natural and physical sciences, yet their robustness to poisoning has received less attention. When it has, studies often assume unrealistic threat models and are thus less useful in practice. In this paper, we propose a novel optimal stealthy attack formulation that considers different degrees of detectability and show that it bypasses state-of-the-art defenses. We further propose a new methodology based on normalization of objectives to evaluate different trade-offs between effectiveness and detectability. Finally, we develop a novel defense (BayesClean) against stealthy attacks. BayesClean improves on previous defenses when attacks are stealthy and the number of poisoning points is significant.
Hyperparameter Learning under Data Poisoning: Analysis of the Influence of Regularization via Multiobjective Bilevel Optimization
Jun 02, 2023



Machine Learning (ML) algorithms are vulnerable to poisoning attacks, where a fraction of the training data is manipulated to deliberately degrade the algorithms' performance. Optimal attacks can be formulated as bilevel optimization problems and help to assess their robustness in worst-case scenarios. We show that current approaches, which typically assume that hyperparameters remain constant, lead to an overly pessimistic view of the algorithms' robustness and of the impact of regularization. We propose a novel optimal attack formulation that considers the effect of the attack on the hyperparameters and models the attack as a multiobjective bilevel optimization problem. This allows to formulate optimal attacks, learn hyperparameters and evaluate robustness under worst-case conditions. We apply this attack formulation to several ML classifiers using $L_2$ and $L_1$ regularization. Our evaluation on multiple datasets confirms the limitations of previous strategies and evidences the benefits of using $L_2$ and $L_1$ regularization to dampen the effect of poisoning attacks.
Explainability in Deep Reinforcement Learning, a Review into Current Methods and Applications
Jul 13, 2022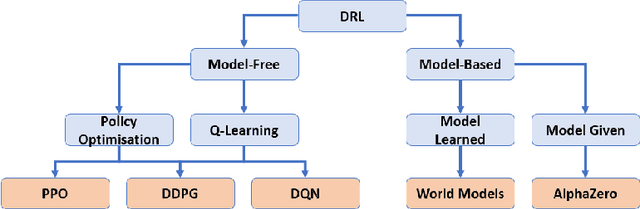
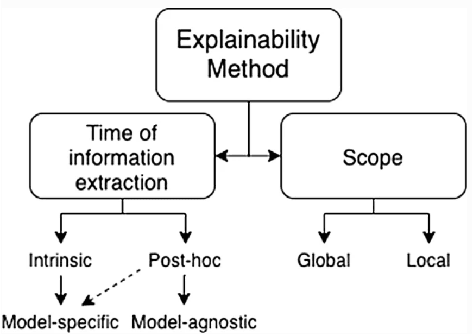
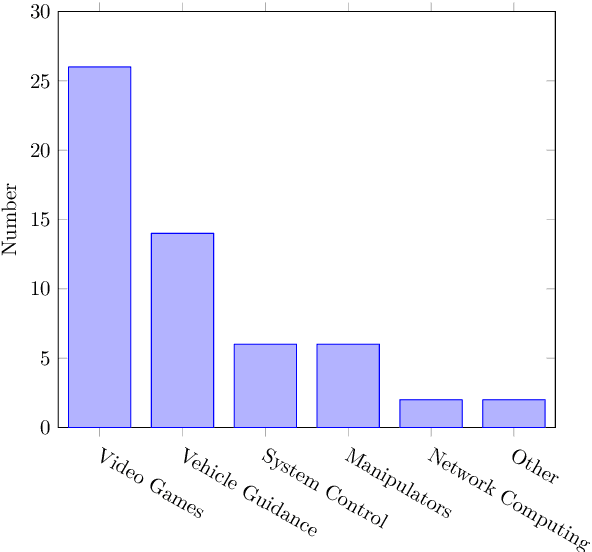
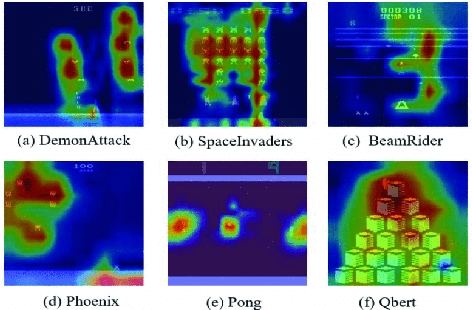
The use of Deep Reinforcement Learning (DRL) schemes has increased dramatically since their first introduction in 2015. Though uses in many different applications are being found they still have a problem with the lack of interpretability. This has bread a lack of understanding and trust in the use of DRL solutions from researchers and the general public. To solve this problem the field of explainable artificial intelligence (XAI) has emerged. This is a variety of different methods that look to open the DRL black boxes, they range from the use of interpretable symbolic decision trees to numerical methods like Shapley Values. This review looks at which methods are being used and what applications they are being used. This is done to identify which models are the best suited to each application or if a method is being underutilised.
Robust Adversarial Attacks Detection based on Explainable Deep Reinforcement Learning For UAV Guidance and Planning
Jun 07, 2022

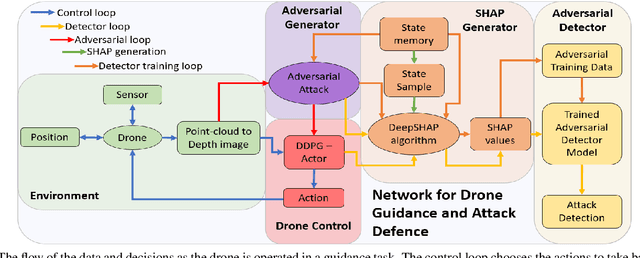
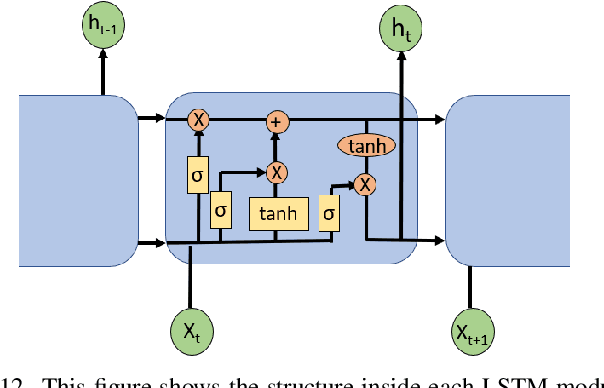
The danger of adversarial attacks to unprotected Uncrewed Aerial Vehicle (UAV) agents operating in public is growing. Adopting AI-based techniques and more specifically Deep Learning (DL) approaches to control and guide these UAVs can be beneficial in terms of performance but add more concerns regarding the safety of those techniques and their vulnerability against adversarial attacks causing the chances of collisions going up as the agent becomes confused. This paper proposes an innovative approach based on the explainability of DL methods to build an efficient detector that will protect these DL schemes and thus the UAVs adopting them from potential attacks. The agent is adopting a Deep Reinforcement Learning (DRL) scheme for guidance and planning. It is formed and trained with a Deep Deterministic Policy Gradient (DDPG) with Prioritised Experience Replay (PER) DRL scheme that utilises Artificial Potential Field (APF) to improve training times and obstacle avoidance performance. The adversarial attacks are generated by Fast Gradient Sign Method (FGSM) and Basic Iterative Method (BIM) algorithms and reduced obstacle course completion rates from 80\% to 35\%. A Realistic Synthetic environment for UAV explainable DRL based planning and guidance including obstacles and adversarial attacks is built. Two adversarial attack detectors are proposed. The first one adopts a Convolutional Neural Network (CNN) architecture and achieves an accuracy in detection of 80\%. The second detector is developed based on a Long Short Term Memory (LSTM) network and achieves an accuracy of 91\% with much faster computing times when compared to the CNN based detector.
Regularization Can Help Mitigate Poisoning Attacks... with the Right Hyperparameters
May 23, 2021

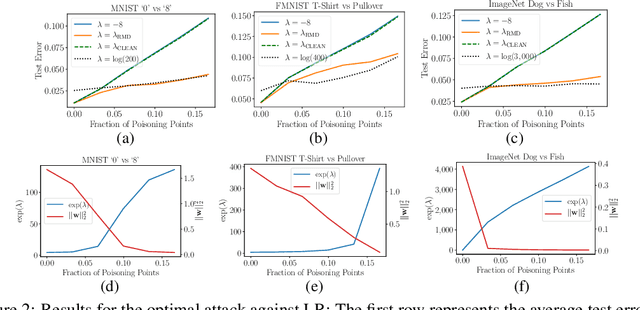
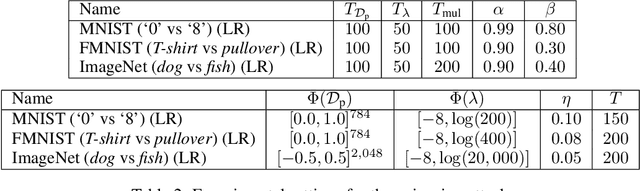
Machine learning algorithms are vulnerable to poisoning attacks, where a fraction of the training data is manipulated to degrade the algorithms' performance. We show that current approaches, which typically assume that regularization hyperparameters remain constant, lead to an overly pessimistic view of the algorithms' robustness and of the impact of regularization. We propose a novel optimal attack formulation that considers the effect of the attack on the hyperparameters, modelling the attack as a \emph{minimax bilevel optimization problem}. This allows to formulate optimal attacks, select hyperparameters and evaluate robustness under worst case conditions. We apply this formulation to logistic regression using $L_2$ regularization, empirically show the limitations of previous strategies and evidence the benefits of using $L_2$ regularization to dampen the effect of poisoning attacks.
Regularisation Can Mitigate Poisoning Attacks: A Novel Analysis Based on Multiobjective Bilevel Optimisation
Feb 28, 2020



Machine Learning (ML) algorithms are vulnerable to poisoning attacks, where a fraction of the training data can be manipulated to deliberately degrade the algorithms' performance. Optimal poisoning attacks, which can be formulated as bilevel optimisation problems, help to assess the robustness of learning algorithms in worst-case scenarios. However, current attacks against algorithms with hyperparameters typically assume that these hyperparameters are constant and thus ignore the effect the attack has on them. In this paper, we show that this approach leads to an overly pessimistic view of the robustness of the learning algorithms tested. We propose a novel optimal attack formulation that considers the effect of the attack on the hyperparameters by modelling the attack as a multiobjective bilevel optimisation problem. We apply this novel attack formulation to ML classifiers using $L_2$ regularisation and show that, in contrast to results previously reported in the literature, $L_2$ regularisation enhances the stability of the learning algorithms and helps to partially mitigate poisoning attacks. Our empirical evaluation on different datasets confirms the limitations of previous poisoning attack strategies, evidences the benefits of using $L_2$ regularisation to dampen the effect of poisoning attacks and shows that the regularisation hyperparameter increases as more malicious data points are injected in the training dataset.