 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning based Autonomous Decision-Making for Cooperative UAVs: A Search and Rescue Real World Application
Feb 27, 2025This paper proposes a holistic framework for autonomous guidance, navigation, and task distribution among multi-drone systems operating in Global Navigation Satellite System (GNSS)-denied indoor settings. We advocate for a Deep Reinforcement Learning (DRL)-based guidance mechanism, utilising the Twin Delayed Deep Deterministic Policy Gradient algorithm. To improve the efficiency of the training process, we incorporate an Artificial Potential Field (APF)-based reward structure, enabling the agent to refine its movements, thereby promoting smoother paths and enhanced obstacle avoidance in indoor contexts. Furthermore, we tackle the issue of task distribution among cooperative UAVs through a DRL-trained Graph Convolutional Network (GCN). This GCN represents the interactions between drones and tasks, facilitating dynamic and real-time task allocation that reflects the current environmental conditions and the capabilities of the drones. Such an approach fosters effective coordination and collaboration among multiple drones during search and rescue operations or other exploratory endeavours. Lastly, to ensure precise odometry in environments lacking GNSS, we employ Light Detection And Ranging Simultaneous Localisation and Mapping complemented by a depth camera to mitigate the hallway problem. This integration offers robust localisation and mapping functionalities, thereby enhancing the systems dependability in indoor navigation. The proposed multi-drone framework not only elevates individual navigation capabilities but also optimises coordinated task allocation in complex, obstacle-laden environments. Experimental evaluations conducted in a setup tailored to meet the requirements of the NATO Sapience Autonomous Cooperative Drone Competition demonstrate the efficacy of the proposed system, yielding outstanding results and culminating in a first-place finish in the 2024 Sapience competition.
Explainable Convolutional Networks for Crater Detection and Lunar Landing Navigation
Aug 24, 2024
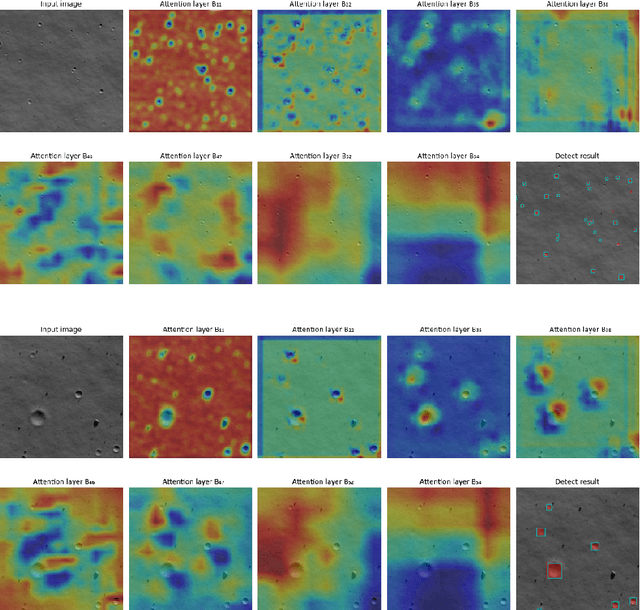
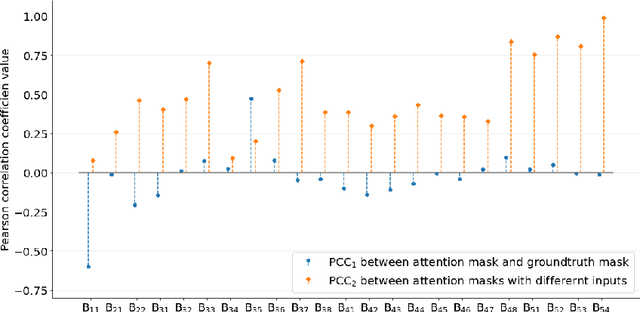
The Lunar landing has drawn great interest in lunar exploration in recent years, and autonomous lunar landing navigation is fundamental to this task. AI is expected to play a critical role in autonomous and intelligent space missions, yet human experts question the reliability of AI solutions. Thus, the \gls{xai} for vision-based lunar landing is studied in this paper, aiming at providing transparent and understandable predictions for intelligent lunar landing. Attention-based Darknet53 is proposed as the feature extraction structure. For crater detection and navigation tasks, attention-based YOLOv3 and attention-Darknet53-LSTM are presented respectively. The experimental results show that the offered networks provide competitive performance on relative crater detection and pose estimation during the lunar landing. The explainability of the provided networks is achieved by introducing an attention mechanism into the network during model building. Moreover, the PCC is utilised to quantitively evaluate the explainability of the proposed networks, with the findings showing the functions of various convolutional layers in the network.
Robust Adversarial Attacks Detection for Deep Learning based Relative Pose Estimation for Space Rendezvous
Nov 10, 2023Research on developing deep learning techniques for autonomous spacecraft relative navigation challenges is continuously growing in recent years. Adopting those techniques offers enhanced performance. However, such approaches also introduce heightened apprehensions regarding the trustability and security of such deep learning methods through their susceptibility to adversarial attacks. In this work, we propose a novel approach for adversarial attack detection for deep neural network-based relative pose estimation schemes based on the explainability concept. We develop for an orbital rendezvous scenario an innovative relative pose estimation technique adopting our proposed Convolutional Neural Network (CNN), which takes an image from the chaser's onboard camera and outputs accurately the target's relative position and rotation. We perturb seamlessly the input images using adversarial attacks that are generated by the Fast Gradient Sign Method (FGSM). The adversarial attack detector is then built based on a Long Short Term Memory (LSTM) network which takes the explainability measure namely SHapley Value from the CNN-based pose estimator and flags the detection of adversarial attacks when acting. Simulation results show that the proposed adversarial attack detector achieves a detection accuracy of 99.21%. Both the deep relative pose estimator and adversarial attack detector are then tested on real data captured from our laboratory-designed setup. The experimental results from our laboratory-designed setup demonstrate that the proposed adversarial attack detector achieves an average detection accuracy of 96.29%.
Orbital AI-based Autonomous Refuelling Solution
Sep 20, 2023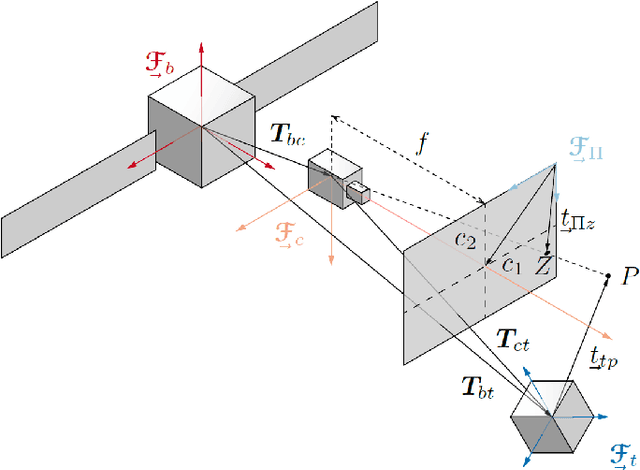

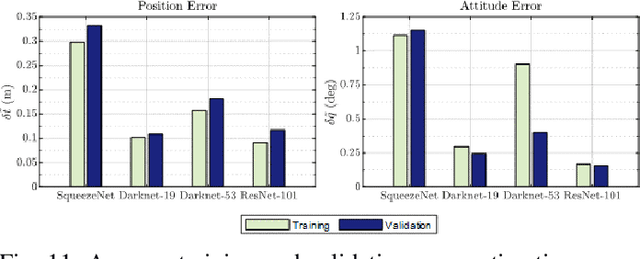

Cameras are rapidly becoming the choice for on-board sensors towards space rendezvous due to their small form factor and inexpensive power, mass, and volume costs. When it comes to docking, however, they typically serve a secondary role, whereas the main work is done by active sensors such as lidar. This paper documents the development of a proposed AI-based (artificial intelligence) navigation algorithm intending to mature the use of on-board visible wavelength cameras as a main sensor for docking and on-orbit servicing (OOS), reducing the dependency on lidar and greatly reducing costs. Specifically, the use of AI enables the expansion of the relative navigation solution towards multiple classes of scenarios, e.g., in terms of targets or illumination conditions, which would otherwise have to be crafted on a case-by-case manner using classical image processing methods. Multiple convolutional neural network (CNN) backbone architectures are benchmarked on synthetically generated data of docking manoeuvres with the International Space Station (ISS), achieving position and attitude estimates close to 1% range-normalised and 1 deg, respectively. The integration of the solution with a physical prototype of the refuelling mechanism is validated in laboratory using a robotic arm to simulate a berthing procedure.
TransPose: A Transformer-based 6D Object Pose Estimation Network with Depth Refinement
Jul 09, 2023



As demand for robotics manipulation application increases, accurate vision-based 6D pose estimation becomes essential for autonomous operations. Convolutional Neural Networks (CNNs) based approaches for pose estimation have been previously introduced. However, the quest for better performance still persists especially for accurate robotics manipulation. This quest extends to the Agri-robotics domain. In this paper, we propose TransPose, an improved Transformer-based 6D pose estimation with a depth refinement module. The architecture takes in only an RGB image as input with no additional supplementing modalities such as depth or thermal images. The architecture encompasses an innovative lighter depth estimation network that estimates depth from an RGB image using feature pyramid with an up-sampling method. A transformer-based detection network with additional prediction heads is proposed to directly regress the object's centre and predict the 6D pose of the target. A novel depth refinement module is then used alongside the predicted centers, 6D poses and depth patches to refine the accuracy of the estimated 6D pose. We extensively compared our results with other state-of-the-art methods and analysed our results for fruit-picking applications. The results we achieved show that our proposed technique outperforms the other methods available in the literature.
Explainability in Deep Reinforcement Learning, a Review into Current Methods and Applications
Jul 13, 2022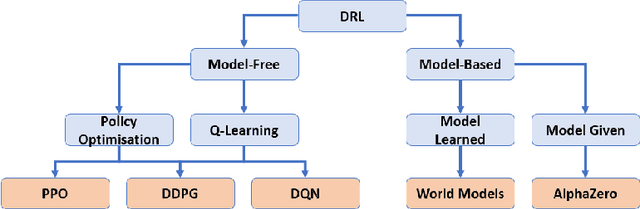
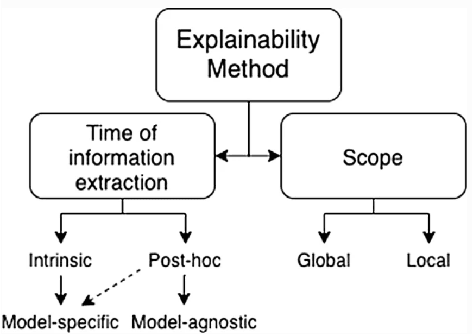
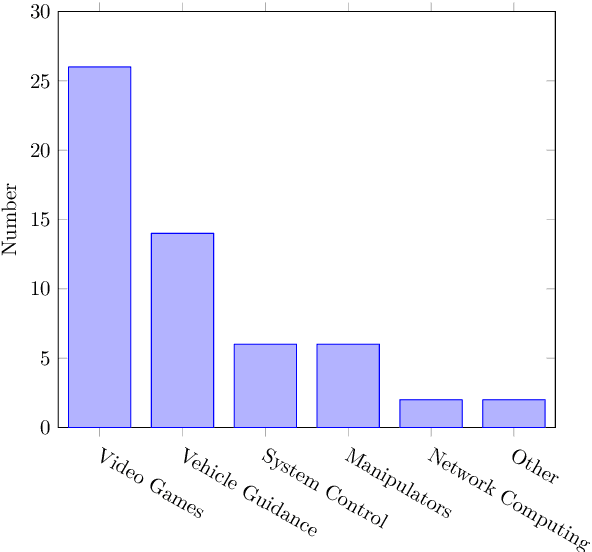
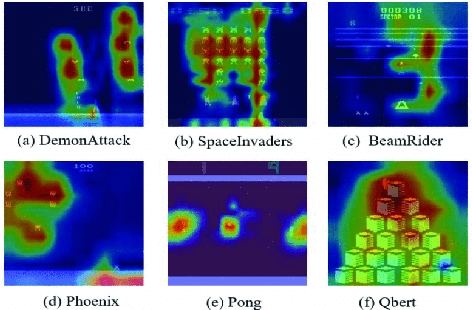
The use of Deep Reinforcement Learning (DRL) schemes has increased dramatically since their first introduction in 2015. Though uses in many different applications are being found they still have a problem with the lack of interpretability. This has bread a lack of understanding and trust in the use of DRL solutions from researchers and the general public. To solve this problem the field of explainable artificial intelligence (XAI) has emerged. This is a variety of different methods that look to open the DRL black boxes, they range from the use of interpretable symbolic decision trees to numerical methods like Shapley Values. This review looks at which methods are being used and what applications they are being used. This is done to identify which models are the best suited to each application or if a method is being underutilised.
Robust Adversarial Attacks Detection based on Explainable Deep Reinforcement Learning For UAV Guidance and Planning
Jun 07, 2022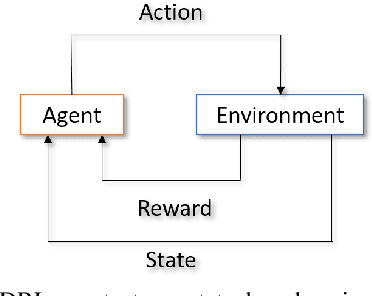

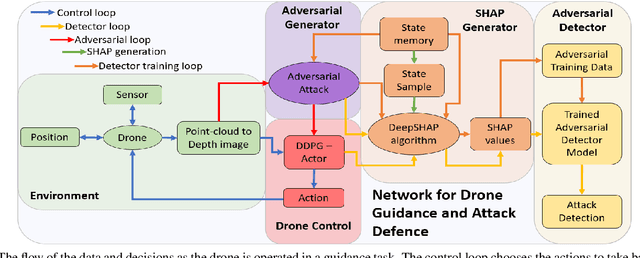
The danger of adversarial attacks to unprotected Uncrewed Aerial Vehicle (UAV) agents operating in public is growing. Adopting AI-based techniques and more specifically Deep Learning (DL) approaches to control and guide these UAVs can be beneficial in terms of performance but add more concerns regarding the safety of those techniques and their vulnerability against adversarial attacks causing the chances of collisions going up as the agent becomes confused. This paper proposes an innovative approach based on the explainability of DL methods to build an efficient detector that will protect these DL schemes and thus the UAVs adopting them from potential attacks. The agent is adopting a Deep Reinforcement Learning (DRL) scheme for guidance and planning. It is formed and trained with a Deep Deterministic Policy Gradient (DDPG) with Prioritised Experience Replay (PER) DRL scheme that utilises Artificial Potential Field (APF) to improve training times and obstacle avoidance performance. The adversarial attacks are generated by Fast Gradient Sign Method (FGSM) and Basic Iterative Method (BIM) algorithms and reduced obstacle course completion rates from 80\% to 35\%. A Realistic Synthetic environment for UAV explainable DRL based planning and guidance including obstacles and adversarial attacks is built. Two adversarial attack detectors are proposed. The first one adopts a Convolutional Neural Network (CNN) architecture and achieves an accuracy in detection of 80\%. The second detector is developed based on a Long Short Term Memory (LSTM) network and achieves an accuracy of 91\% with much faster computing times when compared to the CNN based detector.
Real-time multiview data fusion for object tracking with RGBD sensors
Oct 28, 2021This paper presents a new approach to accurately track a moving vehicle with a multiview setup of red-green-blue depth (RGBD) cameras. We first propose a correction method to eliminate a shift, which occurs in depth sensors when they become worn. This issue could not be otherwise corrected with the ordinary calibration procedure. Next, we present a sensor-wise filtering system to correct for an unknown vehicle motion. A data fusion algorithm is then used to optimally merge the sensor-wise estimated trajectories. We implement most parts of our solution in the graphic processor. Hence, the whole system is able to operate at up to 25 frames per second with a configuration of five cameras. Test results show the accuracy we achieved and the robustness of our solution to overcome uncertainties in the measurements and the modelling.
* Accepted in Robotica
GPU based GMM segmentation of kinect data
Oct 28, 2021


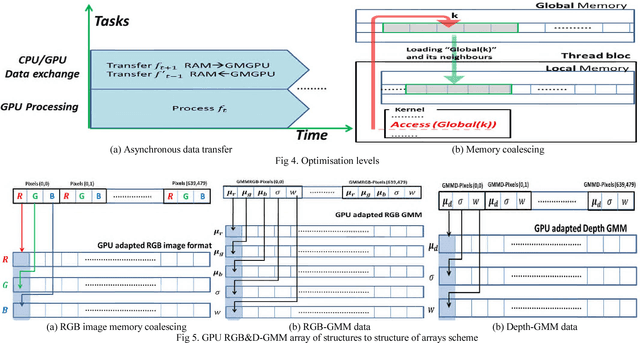
This paper presents a novel approach for background/foreground segmentation of RGBD data with the Gaussian Mixture Models (GMM). We first start by the background subtraction from the colour and depth images separately. The foregrounds resulting from both streams are then fused for a more accurate detection. Our segmentation solution is implemented on the GPU. Thus, it works at the full frame rate of the sensor (30fps). Test results show its robustness against illumination change, shadows and reflections.
* Accepted in ELMAR-2014 conference
A recursive robust filtering approach for 3D registration
Oct 28, 2021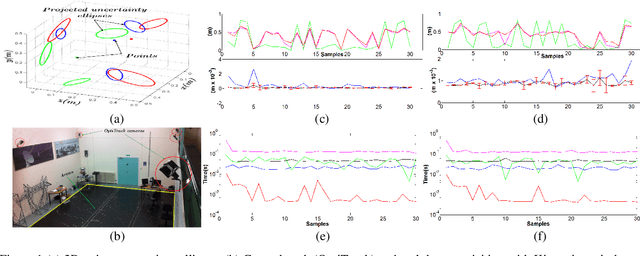
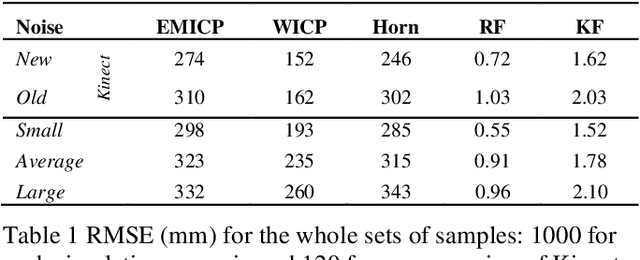
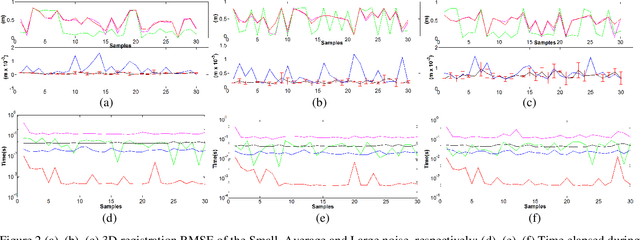
This work presents a new recursive robust filtering approach for feature-based 3D registration. Unlike the common state-of-the-art alignment algorithms, the proposed method has four advantages that have not yet occurred altogether in any previous solution. For instance, it is able to deal with inherent noise contaminating sensory data; it is robust to uncertainties caused by noisy feature localisation; it also combines the advantages of both (Formula presented.) and (Formula presented.) norms for a higher performance and a more prospective prevention of local minima. The result is an accurate and stable rigid body transformation. The latter enables a thorough control over the convergence regarding the alignment as well as a correct assessment of the quality of registration. The mathematical rationale behind the proposed approach is explained, and the results are validated on physical and synthetic data.
* Accepted in the journal of Signal Image and Video Processing