 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSA-VLA: Spatially-Aware Flow-Matching for Vision-Language-Action Reinforcement Learning
Jan 31, 2026Vision-Language-Action (VLA) models exhibit strong generalization in robotic manipulation, yet reinforcement learning (RL) fine-tuning often degrades robustness under spatial distribution shifts. For flow-matching VLA policies, this degradation is closely associated with the erosion of spatial inductive bias during RL adaptation, as sparse rewards and spatially agnostic exploration increasingly favor short-horizon visual cues. To address this issue, we propose \textbf{SA-VLA}, a spatially-aware RL adaptation framework that preserves spatial grounding during policy optimization by aligning representation learning, reward design, and exploration with task geometry. SA-VLA fuses implicit spatial representations with visual tokens, provides dense rewards that reflect geometric progress, and employs \textbf{SCAN}, a spatially-conditioned annealed exploration strategy tailored to flow-matching dynamics. Across challenging multi-object and cluttered manipulation benchmarks, SA-VLA enables stable RL fine-tuning and improves zero-shot spatial generalization, yielding more robust and transferable behaviors. Code and project page are available at https://xupan.top/Projects/savla.
E2HiL: Entropy-Guided Sample Selection for Efficient Real-World Human-in-the-Loop Reinforcement Learning
Jan 27, 2026Human-in-the-loop guidance has emerged as an effective approach for enabling faster convergence in online reinforcement learning (RL) of complex real-world manipulation tasks. However, existing human-in-the-loop RL (HiL-RL) frameworks often suffer from low sample efficiency, requiring substantial human interventions to achieve convergence and thereby leading to high labor costs. To address this, we propose a sample-efficient real-world human-in-the-loop RL framework named \method, which requires fewer human intervention by actively selecting informative samples. Specifically, stable reduction of policy entropy enables improved trade-off between exploration and exploitation with higher sample efficiency. We first build influence functions of different samples on the policy entropy, which is efficiently estimated by the covariance of action probabilities and soft advantages of policies. Then we select samples with moderate values of influence functions, where shortcut samples that induce sharp entropy drops and noisy samples with negligible effect are pruned. Extensive experiments on four real-world manipulation tasks demonstrate that \method achieves a 42.1\% higher success rate while requiring 10.1\% fewer human interventions compared to the state-of-the-art HiL-RL method, validating its effectiveness. The project page providing code, videos, and mathematical formulations can be found at https://e2hil.github.io/.
RAICL: Retrieval-Augmented In-Context Learning for Vision-Language-Model Based EEG Seizure Detection
Jan 25, 2026Electroencephalogram (EEG) decoding is a critical component of medical diagnostics, rehabilitation engineering, and brain-computer interfaces. However, contemporary decoding methodologies remain heavily dependent on task-specific datasets to train specialized neural network architectures. Consequently, limited data availability impedes the development of generalizable large brain decoding models. In this work, we propose a paradigm shift from conventional signal-based decoding by leveraging large-scale vision-language models (VLMs) to analyze EEG waveform plots. By converting multivariate EEG signals into stacked waveform images and integrating neuroscience domain expertise into textual prompts, we demonstrate that foundational VLMs can effectively differentiate between different patterns in the human brain. To address the inherent non-stationarity of EEG signals, we introduce a Retrieval-Augmented In-Context Learning (RAICL) approach, which dynamically selects the most representative and relevant few-shot examples to condition the autoregressive outputs of the VLM. Experiments on EEG-based seizure detection indicate that state-of-the-art VLMs under RAICL achieved better or comparable performance with traditional time series based approaches. These findings suggest a new direction in physiological signal processing that effectively bridges the modalities of vision, language, and neural activities. Furthermore, the utilization of off-the-shelf VLMs, without the need for retraining or downstream architecture construction, offers a readily deployable solution for clinical applications.
Backpropagation-Free Test-Time Adaptation for Lightweight EEG-Based Brain-Computer Interfaces
Jan 12, 2026Electroencephalogram (EEG)-based brain-computer interfaces (BCIs) face significant deployment challenges due to inter-subject variability, signal non-stationarity, and computational constraints. While test-time adaptation (TTA) mitigates distribution shifts under online data streams without per-use calibration sessions, existing TTA approaches heavily rely on explicitly defined loss objectives that require backpropagation for updating model parameters, which incurs computational overhead, privacy risks, and sensitivity to noisy data streams. This paper proposes Backpropagation-Free Transformations (BFT), a TTA approach for EEG decoding that eliminates such issues. BFT applies multiple sample-wise transformations of knowledge-guided augmentations or approximate Bayesian inference to each test trial, generating multiple prediction scores for a single test sample. A learning-to-rank module enhances the weighting of these predictions, enabling robust aggregation for uncertainty suppression during inference under theoretical justifications. Extensive experiments on five EEG datasets of motor imagery classification and driver drowsiness regression tasks demonstrate the effectiveness, versatility, robustness, and efficiency of BFT. This research enables lightweight plug-and-play BCIs on resource-constrained devices, broadening the real-world deployment of decoding algorithms for EEG-based BCI.
NORA-1.5: A Vision-Language-Action Model Trained using World Model- and Action-based Preference Rewards
Nov 18, 2025



Vision--language--action (VLA) models have recently shown promising performance on a variety of embodied tasks, yet they still fall short in reliability and generalization, especially when deployed across different embodiments or real-world environments. In this work, we introduce NORA-1.5, a VLA model built from the pre-trained NORA backbone by adding to it a flow-matching-based action expert. This architectural enhancement alone yields substantial performance gains, enabling NORA-1.5 to outperform NORA and several state-of-the-art VLA models across both simulated and real-world benchmarks. To further improve robustness and task success, we develop a set of reward models for post-training VLA policies. Our rewards combine (i) an action-conditioned world model (WM) that evaluates whether generated actions lead toward the desired goal, and (ii) a deviation-from-ground-truth heuristic that distinguishes good actions from poor ones. Using these reward signals, we construct preference datasets and adapt NORA-1.5 to target embodiments through direct preference optimization (DPO). Extensive evaluations show that reward-driven post-training consistently improves performance in both simulation and real-robot settings, demonstrating significant VLA model-reliability gains through simple yet effective reward models. Our findings highlight NORA-1.5 and reward-guided post-training as a viable path toward more dependable embodied agents suitable for real-world deployment.
ProBench: Benchmarking GUI Agents with Accurate Process Information
Nov 12, 2025With the deep integration of artificial intelligence and interactive technology, Graphical User Interface (GUI) Agent, as the carrier connecting goal-oriented natural language and real-world devices, has received widespread attention from the community. Contemporary benchmarks aim to evaluate the comprehensive capabilities of GUI agents in GUI operation tasks, generally determining task completion solely by inspecting the final screen state. However, GUI operation tasks consist of multiple chained steps while not all critical information is presented in the final few pages. Although a few research has begun to incorporate intermediate steps into evaluation, accurately and automatically capturing this process information still remains an open challenge. To address this weakness, we introduce ProBench, a comprehensive mobile benchmark with over 200 challenging GUI tasks covering widely-used scenarios. Remaining the traditional State-related Task evaluation, we extend our dataset to include Process-related Task and design a specialized evaluation method. A newly introduced Process Provider automatically supplies accurate process information, enabling presice assessment of agent's performance. Our evaluation of advanced GUI agents reveals significant limitations for real-world GUI scenarios. These shortcomings are prevalent across diverse models, including both large-scale generalist models and smaller, GUI-specific models. A detailed error analysis further exposes several universal problems, outlining concrete directions for future improvements.
MAP-VLA: Memory-Augmented Prompting for Vision-Language-Action Model in Robotic Manipulation
Nov 12, 2025Pre-trained Vision-Language-Action (VLA) models have achieved remarkable success in improving robustness and generalization for end-to-end robotic manipulation. However, these models struggle with long-horizon tasks due to their lack of memory and reliance solely on immediate sensory inputs. To address this limitation, we propose Memory-Augmented Prompting for Vision-Language-Action model (MAP-VLA), a novel framework that empowers pre-trained VLA models with demonstration-derived memory prompts to augment action generation for long-horizon robotic manipulation tasks. To achieve this, MAP-VLA first constructs a memory library from historical demonstrations, where each memory unit captures information about a specific stage of a task. These memory units are implemented as learnable soft prompts optimized through prompt tuning. Then, during real-time task execution, MAP-VLA retrieves relevant memory through trajectory similarity matching and dynamically integrates it into the VLA model for augmented action generation. Importantly, this prompt tuning and retrieval augmentation approach operates as a plug-and-play module for a frozen VLA model, offering a lightweight and flexible solution to improve task performance. Experimental results show that MAP-VLA delivers up to 7.0% absolute performance gains in the simulation benchmark and 25.0% on real robot evaluations for long-horizon tasks, surpassing the current state-of-the-art methods.
History-Aware Reasoning for GUI Agents
Nov 12, 2025Advances in Multimodal Large Language Models have significantly enhanced Graphical User Interface (GUI) automation. Equipping GUI agents with reliable episodic reasoning capabilities is essential for bridging the gap between users' concise task descriptions and the complexities of real-world execution. Current methods integrate Reinforcement Learning (RL) with System-2 Chain-of-Thought, yielding notable gains in reasoning enhancement. For long-horizon GUI tasks, historical interactions connect each screen to the goal-oriented episode chain, and effectively leveraging these clues is crucial for the current decision. However, existing native GUI agents exhibit weak short-term memory in their explicit reasoning, interpreting the chained interactions as discrete screen understanding, i.e., unawareness of the historical interactions within the episode. This history-agnostic reasoning challenges their performance in GUI automation. To alleviate this weakness, we propose a History-Aware Reasoning (HAR) framework, which encourages an agent to reflect on its own errors and acquire episodic reasoning knowledge from them via tailored strategies that enhance short-term memory in long-horizon interaction. The framework mainly comprises constructing a reflective learning scenario, synthesizing tailored correction guidelines, and designing a hybrid RL reward function. Using the HAR framework, we develop a native end-to-end model, HAR-GUI-3B, which alters the inherent reasoning mode from history-agnostic to history-aware, equipping the GUI agent with stable short-term memory and reliable perception of screen details. Comprehensive evaluations across a range of GUI-related benchmarks demonstrate the effectiveness and generalization of our method.
10 Open Challenges Steering the Future of Vision-Language-Action Models
Nov 08, 2025Due to their ability of follow natural language instructions, vision-language-action (VLA) models are increasingly prevalent in the embodied AI arena, following the widespread success of their precursors -- LLMs and VLMs. In this paper, we discuss 10 principal milestones in the ongoing development of VLA models -- multimodality, reasoning, data, evaluation, cross-robot action generalization, efficiency, whole-body coordination, safety, agents, and coordination with humans. Furthermore, we discuss the emerging trends of using spatial understanding, modeling world dynamics, post training, and data synthesis -- all aiming to reach these milestones. Through these discussions, we hope to bring attention to the research avenues that may accelerate the development of VLA models into wider acceptability.
Towards Scalable Web Accessibility Audit with MLLMs as Copilots
Nov 05, 2025


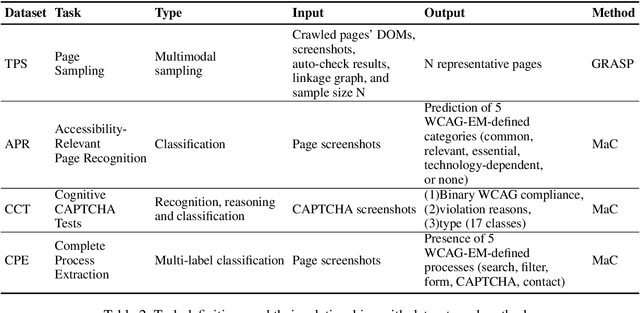
Ensuring web accessibility is crucial for advancing social welfare, justice, and equality in digital spaces, yet the vast majority of website user interfaces remain non-compliant, due in part to the resource-intensive and unscalable nature of current auditing practices. While WCAG-EM offers a structured methodology for site-wise conformance evaluation, it involves great human efforts and lacks practical support for execution at scale. In this work, we present an auditing framework, AAA, which operationalizes WCAG-EM through a human-AI partnership model. AAA is anchored by two key innovations: GRASP, a graph-based multimodal sampling method that ensures representative page coverage via learned embeddings of visual, textual, and relational cues; and MaC, a multimodal large language model-based copilot that supports auditors through cross-modal reasoning and intelligent assistance in high-effort tasks. Together, these components enable scalable, end-to-end web accessibility auditing, empowering human auditors with AI-enhanced assistance for real-world impact. We further contribute four novel datasets designed for benchmarking core stages of the audit pipeline. Extensive experiments demonstrate the effectiveness of our methods, providing insights that small-scale language models can serve as capable experts when fine-tuned.