 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficientLLaVA:Generalizable Auto-Pruning for Large Vision-language Models
Mar 19, 2025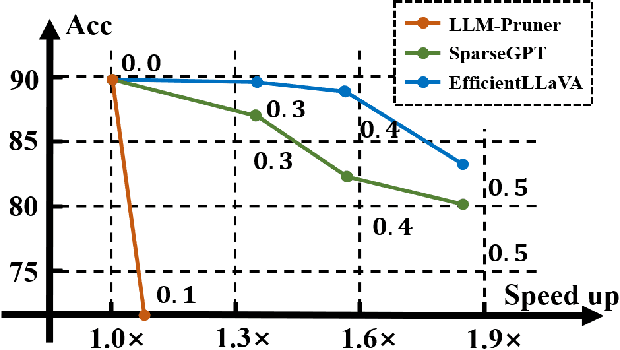
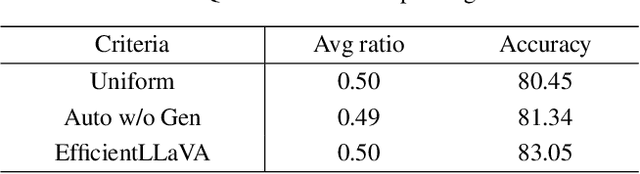
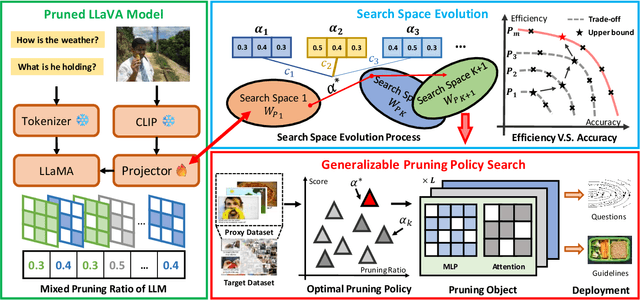
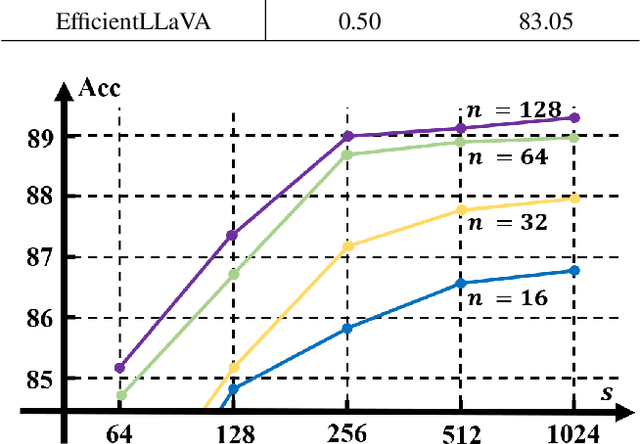
While multimodal large language models demonstrate strong performance in complex reasoning tasks, they pose significant challenges related to model complexity during deployment, especially for resource-limited devices. In this paper, we propose an automatic pruning method for large vision-language models to enhance the efficiency of multimodal reasoning. Conventional methods rely on the training data of the original model to select the proper pruning ratio for different network components. However, these methods are impractical for large vision-language models due to the unaffordable search costs caused by web-scale training corpus. In contrast, our approach only leverages a small number of samples to search for the desired pruning policy by maximizing its generalization ability on unknown training data while maintaining the model accuracy, which enables the achievement of an optimal trade-off between accuracy and efficiency for large visual language models. Specifically, we formulate the generalization gap of the pruning strategy using the structural risk minimization principle. Based on both task performance and generalization capability, we iteratively search for the optimal pruning policy within a given search space and optimize the vision projector to evolve the search space with higher upper bound of performance. We conduct extensive experiments on the ScienceQA, Vizwiz, MM-vet, and LLaVA-Bench datasets for the task of visual question answering. Using only 64 samples for pruning policy search, EfficientLLaVA achieves an accuracy of 83.05% on ScienceQA, along with a $\times$ 1.8 speedup compared to the dense LLaVA-v1.5-7B model.
MCUFormer: Deploying Vision Tranformers on Microcontrollers with Limited Memory
Oct 27, 2023



Due to the high price and heavy energy consumption of GPUs, deploying deep models on IoT devices such as microcontrollers makes significant contributions for ecological AI. Conventional methods successfully enable convolutional neural network inference of high resolution images on microcontrollers, while the framework for vision transformers that achieve the state-of-the-art performance in many vision applications still remains unexplored. In this paper, we propose a hardware-algorithm co-optimizations method called MCUFormer to deploy vision transformers on microcontrollers with extremely limited memory, where we jointly design transformer architecture and construct the inference operator library to fit the memory resource constraint. More specifically, we generalize the one-shot network architecture search (NAS) to discover the optimal architecture with highest task performance given the memory budget from the microcontrollers, where we enlarge the existing search space of vision transformers by considering the low-rank decomposition dimensions and patch resolution for memory reduction. For the construction of the inference operator library of vision transformers, we schedule the memory buffer during inference through operator integration, patch embedding decomposition, and token overwriting, allowing the memory buffer to be fully utilized to adapt to the forward pass of the vision transformer. Experimental results demonstrate that our MCUFormer achieves 73.62\% top-1 accuracy on ImageNet for image classification with 320KB memory on STM32F746 microcontroller. Code is available at https://github.com/liangyn22/MCUFormer.