 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAwareVLN: Reasoning with Self-awareness for Vision-Language Navigation
May 21, 2026Vision-and-Language Navigation (VLN) requires an agent to ground language instructions to its own movement within a visual environment. While state-of-the-art methods leverage the reasoning capabilities of Vision-Language Models (VLMs) for end-to-end action prediction, they often lack an explicit and explainable understanding of the relationships between the agent, the instruction, and the scene. Conversely, explicitly building a scene map for heuristic planning is intuitively appealing but relies on additional 3D sensors and hinders large-scale vision-language pre-training. To bridge this gap, we propose AwareVLN, a novel framework that equips the navigation model with a self-aware reasoning mechanism, enabling it to understand the agent's state and task progress in a fully end-to-end and data-driven manner. Our approach features two key innovations: (1) a structural reasoning module that fosters spatial and task-oriented self-awareness, and (2) an automatic data engine with progress division for effective training. Extensive experiments on various datasets in Habitat simulator show our AwareVLN significantly outperforms previous state-of-the-art vision-language navigation methods. Project page: https://gwxuan.github.io/AwareVLN/.
CMP: Robust Whole-Body Tracking for Loco-Manipulation via Competence Manifold Projection
Apr 08, 2026While decoupled control schemes for legged mobile manipulators have shown robustness, learning holistic whole-body control policies for tracking global end-effector poses remains fragile against Out-of-Distribution (OOD) inputs induced by sensor noise or infeasible user commands. To improve robustness against these perturbations without sacrificing task performance and continuity, we propose Competence Manifold Projection (CMP). Specifically, we utilize a Frame-Wise Safety Scheme that transforms the infinite-horizon safety constraint into a computationally efficient single-step manifold inclusion. To instantiate this competence manifold, we employ a Lower-Bounded Safety Estimator that distinguishes unmastered intentions from the training distribution. We then introduce an Isomorphic Latent Space (ILS) that aligns manifold geometry with safety probability, enabling efficient O(1) seamless defense against arbitrary OOD intents. Experiments demonstrate that CMP achieves up to a 10-fold survival rate improvement in typical OOD scenarios where baselines suffer catastrophic failure, incurring under 10% tracking degradation. Notably, the system exhibits emergent ``best-effort'' generalization behaviors to progressively accomplish OOD goals by adhering to the competence boundaries. Result videos are available at: https://shepherd1226.github.io/CMP.
F2F-AP: Flow-to-Future Asynchronous Policy for Real-time Dynamic Manipulation
Apr 02, 2026Asynchronous inference has emerged as a prevalent paradigm in robotic manipulation, achieving significant progress in ensuring trajectory smoothness and efficiency. However, a systemic challenge remains unresolved, as inherent latency causes generated actions to inevitably lag behind the real-time environment. This issue is particularly exacerbated in dynamic scenarios, where such temporal misalignment severely compromises the policy's ability to interpret and react to rapidly evolving surroundings. In this paper, we propose a novel framework that leverages predicted object flow to synthesize future observations, incorporating a flow-based contrastive learning objective to align the visual feature representations of predicted observations with ground-truth future states. Empowered by this anticipated visual context, our asynchronous policy gains the capacity for proactive planning and motion, enabling it to explicitly compensate for latency and robustly execute manipulation tasks involving actively moving objects. Experimental results demonstrate that our approach significantly enhances responsiveness and success rates in complex dynamic manipulation tasks.
iGaussian: Real-Time Camera Pose Estimation via Feed-Forward 3D Gaussian Splatting Inversion
Nov 18, 2025Recent trends in SLAM and visual navigation have embraced 3D Gaussians as the preferred scene representation, highlighting the importance of estimating camera poses from a single image using a pre-built Gaussian model. However, existing approaches typically rely on an iterative \textit{render-compare-refine} loop, where candidate views are first rendered using NeRF or Gaussian Splatting, then compared against the target image, and finally, discrepancies are used to update the pose. This multi-round process incurs significant computational overhead, hindering real-time performance in robotics. In this paper, we propose iGaussian, a two-stage feed-forward framework that achieves real-time camera pose estimation through direct 3D Gaussian inversion. Our method first regresses a coarse 6DoF pose using a Gaussian Scene Prior-based Pose Regression Network with spatial uniform sampling and guided attention mechanisms, then refines it through feature matching and multi-model fusion. The key contribution lies in our cross-correlation module that aligns image embeddings with 3D Gaussian attributes without differentiable rendering, coupled with a Weighted Multiview Predictor that fuses features from Multiple strategically sampled viewpoints. Experimental results on the NeRF Synthetic, Mip-NeRF 360, and T\&T+DB datasets demonstrate a significant performance improvement over previous methods, reducing median rotation errors to 0.2° while achieving 2.87 FPS tracking on mobile robots, which is an impressive 10 times speedup compared to optimization-based approaches. Code: https://github.com/pythongod-exe/iGaussian
Pseudo Depth Meets Gaussian: A Feed-forward RGB SLAM Baseline
Aug 06, 2025Incrementally recovering real-sized 3D geometry from a pose-free RGB stream is a challenging task in 3D reconstruction, requiring minimal assumptions on input data. Existing methods can be broadly categorized into end-to-end and visual SLAM-based approaches, both of which either struggle with long sequences or depend on slow test-time optimization and depth sensors. To address this, we first integrate a depth estimator into an RGB-D SLAM system, but this approach is hindered by inaccurate geometric details in predicted depth. Through further investigation, we find that 3D Gaussian mapping can effectively solve this problem. Building on this, we propose an online 3D reconstruction method using 3D Gaussian-based SLAM, combined with a feed-forward recurrent prediction module to directly infer camera pose from optical flow. This approach replaces slow test-time optimization with fast network inference, significantly improving tracking speed. Additionally, we introduce a local graph rendering technique to enhance robustness in feed-forward pose prediction. Experimental results on the Replica and TUM-RGBD datasets, along with a real-world deployment demonstration, show that our method achieves performance on par with the state-of-the-art SplaTAM, while reducing tracking time by more than 90\%.
IGL-Nav: Incremental 3D Gaussian Localization for Image-goal Navigation
Aug 01, 2025



Visual navigation with an image as goal is a fundamental and challenging problem. Conventional methods either rely on end-to-end RL learning or modular-based policy with topological graph or BEV map as memory, which cannot fully model the geometric relationship between the explored 3D environment and the goal image. In order to efficiently and accurately localize the goal image in 3D space, we build our navigation system upon the renderable 3D gaussian (3DGS) representation. However, due to the computational intensity of 3DGS optimization and the large search space of 6-DoF camera pose, directly leveraging 3DGS for image localization during agent exploration process is prohibitively inefficient. To this end, we propose IGL-Nav, an Incremental 3D Gaussian Localization framework for efficient and 3D-aware image-goal navigation. Specifically, we incrementally update the scene representation as new images arrive with feed-forward monocular prediction. Then we coarsely localize the goal by leveraging the geometric information for discrete space matching, which can be equivalent to efficient 3D convolution. When the agent is close to the goal, we finally solve the fine target pose with optimization via differentiable rendering. The proposed IGL-Nav outperforms existing state-of-the-art methods by a large margin across diverse experimental configurations. It can also handle the more challenging free-view image-goal setting and be deployed on real-world robotic platform using a cellphone to capture goal image at arbitrary pose. Project page: https://gwxuan.github.io/IGL-Nav/.
EfficientLLaVA:Generalizable Auto-Pruning for Large Vision-language Models
Mar 19, 2025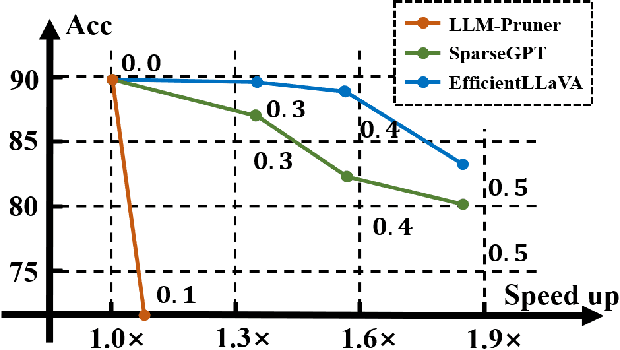
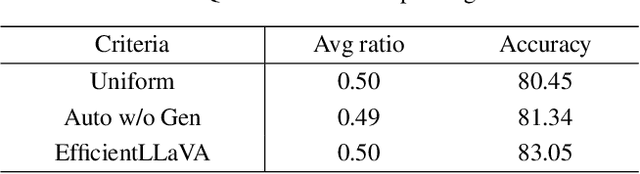
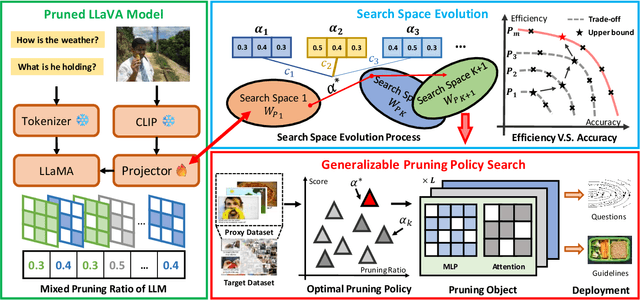
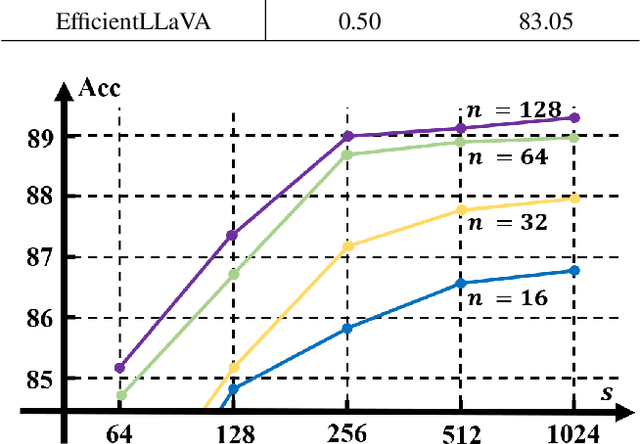
While multimodal large language models demonstrate strong performance in complex reasoning tasks, they pose significant challenges related to model complexity during deployment, especially for resource-limited devices. In this paper, we propose an automatic pruning method for large vision-language models to enhance the efficiency of multimodal reasoning. Conventional methods rely on the training data of the original model to select the proper pruning ratio for different network components. However, these methods are impractical for large vision-language models due to the unaffordable search costs caused by web-scale training corpus. In contrast, our approach only leverages a small number of samples to search for the desired pruning policy by maximizing its generalization ability on unknown training data while maintaining the model accuracy, which enables the achievement of an optimal trade-off between accuracy and efficiency for large visual language models. Specifically, we formulate the generalization gap of the pruning strategy using the structural risk minimization principle. Based on both task performance and generalization capability, we iteratively search for the optimal pruning policy within a given search space and optimize the vision projector to evolve the search space with higher upper bound of performance. We conduct extensive experiments on the ScienceQA, Vizwiz, MM-vet, and LLaVA-Bench datasets for the task of visual question answering. Using only 64 samples for pruning policy search, EfficientLLaVA achieves an accuracy of 83.05% on ScienceQA, along with a $\times$ 1.8 speedup compared to the dense LLaVA-v1.5-7B model.
MoManipVLA: Transferring Vision-language-action Models for General Mobile Manipulation
Mar 17, 2025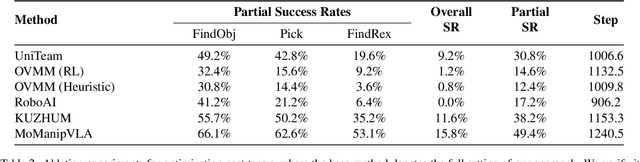
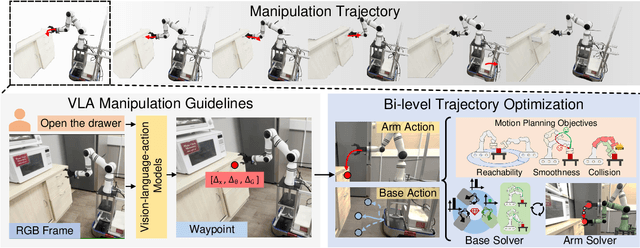
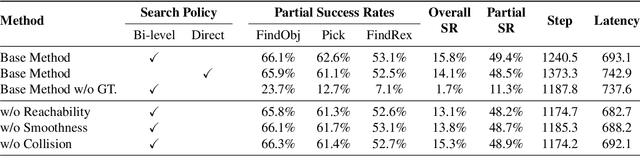

Mobile manipulation is the fundamental challenge for robotics to assist humans with diverse tasks and environments in everyday life. However, conventional mobile manipulation approaches often struggle to generalize across different tasks and environments because of the lack of large-scale training. In contrast, recent advances in vision-language-action (VLA) models have shown impressive generalization capabilities, but these foundation models are developed for fixed-base manipulation tasks. Therefore, we propose an efficient policy adaptation framework named MoManipVLA to transfer pre-trained VLA models of fix-base manipulation to mobile manipulation, so that high generalization ability across tasks and environments can be achieved in mobile manipulation policy. Specifically, we utilize pre-trained VLA models to generate waypoints of the end-effector with high generalization ability. We design motion planning objectives for the mobile base and the robot arm, which aim at maximizing the physical feasibility of the trajectory. Finally, we present an efficient bi-level objective optimization framework for trajectory generation, where the upper-level optimization predicts waypoints for base movement to enhance the manipulator policy space, and the lower-level optimization selects the optimal end-effector trajectory to complete the manipulation task. In this way, MoManipVLA can adjust the position of the robot base in a zero-shot manner, thus making the waypoints predicted from the fixed-base VLA models feasible. Extensive experimental results on OVMM and the real world demonstrate that MoManipVLA achieves a 4.2% higher success rate than the state-of-the-art mobile manipulation, and only requires 50 training cost for real world deployment due to the strong generalization ability in the pre-trained VLA models.
UniGoal: Towards Universal Zero-shot Goal-oriented Navigation
Mar 13, 2025In this paper, we propose a general framework for universal zero-shot goal-oriented navigation. Existing zero-shot methods build inference framework upon large language models (LLM) for specific tasks, which differs a lot in overall pipeline and fails to generalize across different types of goal. Towards the aim of universal zero-shot navigation, we propose a uniform graph representation to unify different goals, including object category, instance image and text description. We also convert the observation of agent into an online maintained scene graph. With this consistent scene and goal representation, we preserve most structural information compared with pure text and are able to leverage LLM for explicit graph-based reasoning. Specifically, we conduct graph matching between the scene graph and goal graph at each time instant and propose different strategies to generate long-term goal of exploration according to different matching states. The agent first iteratively searches subgraph of goal when zero-matched. With partial matching, the agent then utilizes coordinate projection and anchor pair alignment to infer the goal location. Finally scene graph correction and goal verification are applied for perfect matching. We also present a blacklist mechanism to enable robust switch between stages. Extensive experiments on several benchmarks show that our UniGoal achieves state-of-the-art zero-shot performance on three studied navigation tasks with a single model, even outperforming task-specific zero-shot methods and supervised universal methods.
SG-Nav: Online 3D Scene Graph Prompting for LLM-based Zero-shot Object Navigation
Oct 10, 2024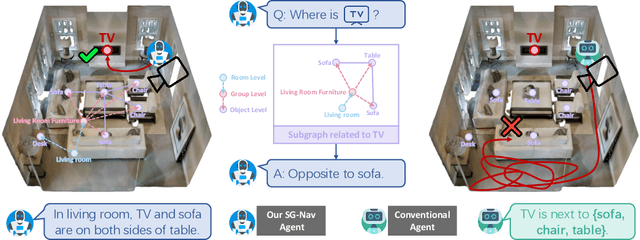
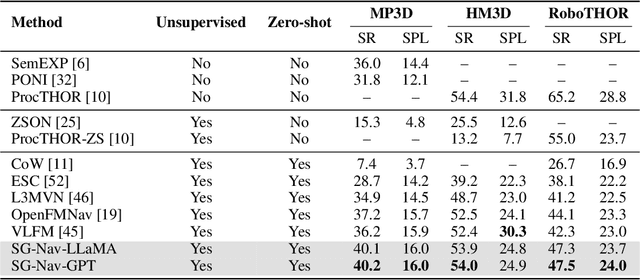
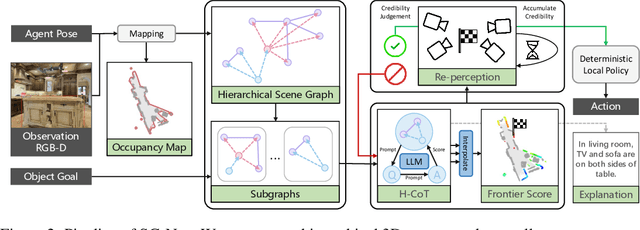

In this paper, we propose a new framework for zero-shot object navigation. Existing zero-shot object navigation methods prompt LLM with the text of spatially closed objects, which lacks enough scene context for in-depth reasoning. To better preserve the information of environment and fully exploit the reasoning ability of LLM, we propose to represent the observed scene with 3D scene graph. The scene graph encodes the relationships between objects, groups and rooms with a LLM-friendly structure, for which we design a hierarchical chain-of-thought prompt to help LLM reason the goal location according to scene context by traversing the nodes and edges. Moreover, benefit from the scene graph representation, we further design a re-perception mechanism to empower the object navigation framework with the ability to correct perception error. We conduct extensive experiments on MP3D, HM3D and RoboTHOR environments, where SG-Nav surpasses previous state-of-the-art zero-shot methods by more than 10% SR on all benchmarks, while the decision process is explainable. To the best of our knowledge, SG-Nav is the first zero-shot method that achieves even higher performance than supervised object navigation methods on the challenging MP3D benchmark.