 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiGaussian: Real-Time Camera Pose Estimation via Feed-Forward 3D Gaussian Splatting Inversion
Nov 18, 2025Recent trends in SLAM and visual navigation have embraced 3D Gaussians as the preferred scene representation, highlighting the importance of estimating camera poses from a single image using a pre-built Gaussian model. However, existing approaches typically rely on an iterative \textit{render-compare-refine} loop, where candidate views are first rendered using NeRF or Gaussian Splatting, then compared against the target image, and finally, discrepancies are used to update the pose. This multi-round process incurs significant computational overhead, hindering real-time performance in robotics. In this paper, we propose iGaussian, a two-stage feed-forward framework that achieves real-time camera pose estimation through direct 3D Gaussian inversion. Our method first regresses a coarse 6DoF pose using a Gaussian Scene Prior-based Pose Regression Network with spatial uniform sampling and guided attention mechanisms, then refines it through feature matching and multi-model fusion. The key contribution lies in our cross-correlation module that aligns image embeddings with 3D Gaussian attributes without differentiable rendering, coupled with a Weighted Multiview Predictor that fuses features from Multiple strategically sampled viewpoints. Experimental results on the NeRF Synthetic, Mip-NeRF 360, and T\&T+DB datasets demonstrate a significant performance improvement over previous methods, reducing median rotation errors to 0.2° while achieving 2.87 FPS tracking on mobile robots, which is an impressive 10 times speedup compared to optimization-based approaches. Code: https://github.com/pythongod-exe/iGaussian
Pseudo Depth Meets Gaussian: A Feed-forward RGB SLAM Baseline
Aug 06, 2025Incrementally recovering real-sized 3D geometry from a pose-free RGB stream is a challenging task in 3D reconstruction, requiring minimal assumptions on input data. Existing methods can be broadly categorized into end-to-end and visual SLAM-based approaches, both of which either struggle with long sequences or depend on slow test-time optimization and depth sensors. To address this, we first integrate a depth estimator into an RGB-D SLAM system, but this approach is hindered by inaccurate geometric details in predicted depth. Through further investigation, we find that 3D Gaussian mapping can effectively solve this problem. Building on this, we propose an online 3D reconstruction method using 3D Gaussian-based SLAM, combined with a feed-forward recurrent prediction module to directly infer camera pose from optical flow. This approach replaces slow test-time optimization with fast network inference, significantly improving tracking speed. Additionally, we introduce a local graph rendering technique to enhance robustness in feed-forward pose prediction. Experimental results on the Replica and TUM-RGBD datasets, along with a real-world deployment demonstration, show that our method achieves performance on par with the state-of-the-art SplaTAM, while reducing tracking time by more than 90\%.
MoManipVLA: Transferring Vision-language-action Models for General Mobile Manipulation
Mar 17, 2025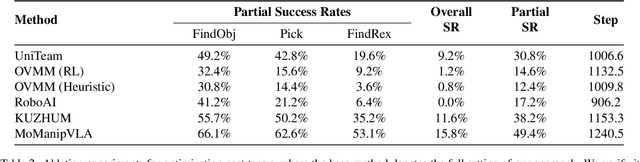
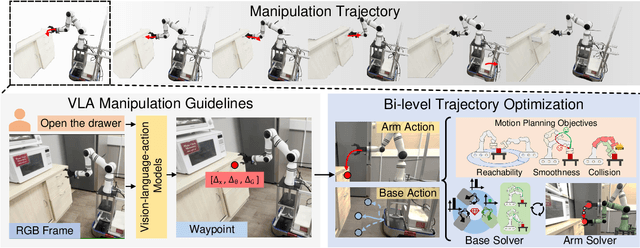
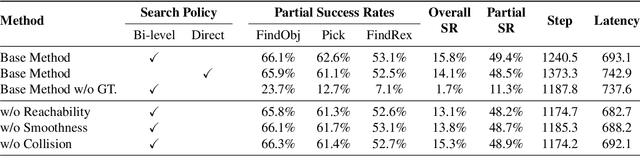

Mobile manipulation is the fundamental challenge for robotics to assist humans with diverse tasks and environments in everyday life. However, conventional mobile manipulation approaches often struggle to generalize across different tasks and environments because of the lack of large-scale training. In contrast, recent advances in vision-language-action (VLA) models have shown impressive generalization capabilities, but these foundation models are developed for fixed-base manipulation tasks. Therefore, we propose an efficient policy adaptation framework named MoManipVLA to transfer pre-trained VLA models of fix-base manipulation to mobile manipulation, so that high generalization ability across tasks and environments can be achieved in mobile manipulation policy. Specifically, we utilize pre-trained VLA models to generate waypoints of the end-effector with high generalization ability. We design motion planning objectives for the mobile base and the robot arm, which aim at maximizing the physical feasibility of the trajectory. Finally, we present an efficient bi-level objective optimization framework for trajectory generation, where the upper-level optimization predicts waypoints for base movement to enhance the manipulator policy space, and the lower-level optimization selects the optimal end-effector trajectory to complete the manipulation task. In this way, MoManipVLA can adjust the position of the robot base in a zero-shot manner, thus making the waypoints predicted from the fixed-base VLA models feasible. Extensive experimental results on OVMM and the real world demonstrate that MoManipVLA achieves a 4.2% higher success rate than the state-of-the-art mobile manipulation, and only requires 50 training cost for real world deployment due to the strong generalization ability in the pre-trained VLA models.
Embodied Instruction Following in Unknown Environments
Jun 17, 2024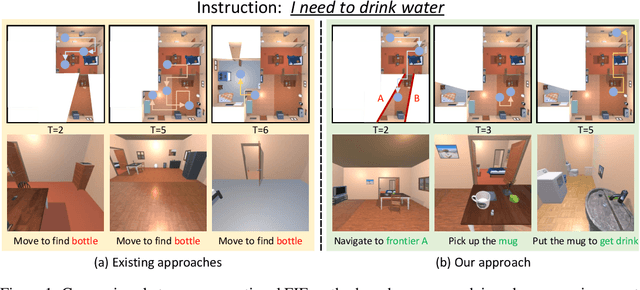
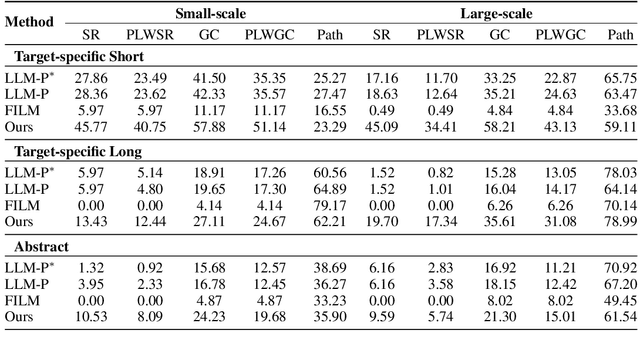
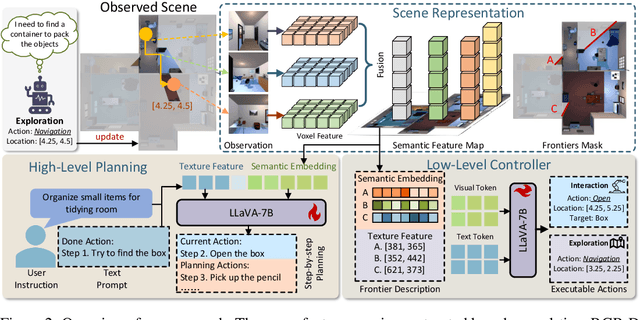
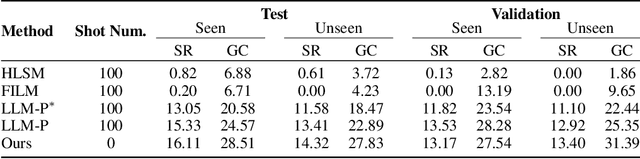
Enabling embodied agents to complete complex human instructions from natural language is crucial to autonomous systems in household services. Conventional methods can only accomplish human instructions in the known environment where all interactive objects are provided to the embodied agent, and directly deploying the existing approaches for the unknown environment usually generates infeasible plans that manipulate non-existing objects. On the contrary, we propose an embodied instruction following (EIF) method for complex tasks in the unknown environment, where the agent efficiently explores the unknown environment to generate feasible plans with existing objects to accomplish abstract instructions. Specifically, we build a hierarchical embodied instruction following framework including the high-level task planner and the low-level exploration controller with multimodal large language models. We then construct a semantic representation map of the scene with dynamic region attention to demonstrate the known visual clues, where the goal of task planning and scene exploration is aligned for human instruction. For the task planner, we generate the feasible step-by-step plans for human goal accomplishment according to the task completion process and the known visual clues. For the exploration controller, the optimal navigation or object interaction policy is predicted based on the generated step-wise plans and the known visual clues. The experimental results demonstrate that our method can achieve 45.09% success rate in 204 complex human instructions such as making breakfast and tidying rooms in large house-level scenes.
Hardness-Aware Scene Synthesis for Semi-Supervised 3D Object Detection
May 27, 2024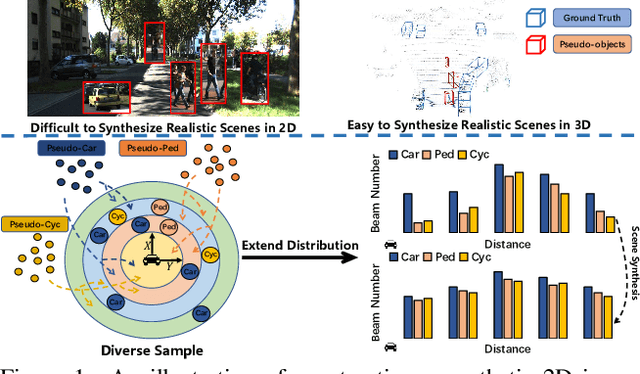
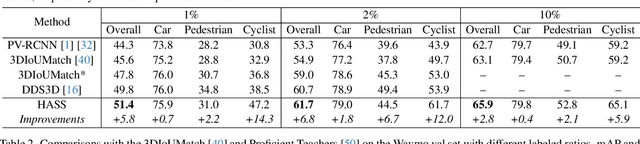
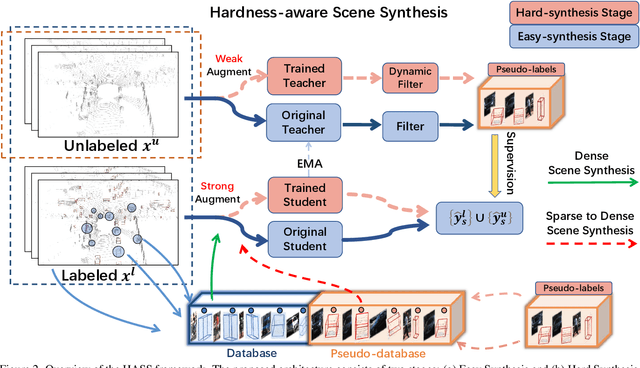
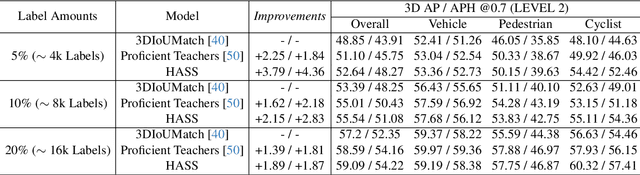
3D object detection aims to recover the 3D information of concerning objects and serves as the fundamental task of autonomous driving perception. Its performance greatly depends on the scale of labeled training data, yet it is costly to obtain high-quality annotations for point cloud data. While conventional methods focus on generating pseudo-labels for unlabeled samples as supplements for training, the structural nature of 3D point cloud data facilitates the composition of objects and backgrounds to synthesize realistic scenes. Motivated by this, we propose a hardness-aware scene synthesis (HASS) method to generate adaptive synthetic scenes to improve the generalization of the detection models. We obtain pseudo-labels for unlabeled objects and generate diverse scenes with different compositions of objects and backgrounds. As the scene synthesis is sensitive to the quality of pseudo-labels, we further propose a hardness-aware strategy to reduce the effect of low-quality pseudo-labels and maintain a dynamic pseudo-database to ensure the diversity and quality of synthetic scenes. Extensive experimental results on the widely used KITTI and Waymo datasets demonstrate the superiority of the proposed HASS method, which outperforms existing semi-supervised learning methods on 3D object detection. Code: https://github.com/wzzheng/HASS.
X-3D: Explicit 3D Structure Modeling for Point Cloud Recognition
Apr 23, 2024



Numerous prior studies predominantly emphasize constructing relation vectors for individual neighborhood points and generating dynamic kernels for each vector and embedding these into high-dimensional spaces to capture implicit local structures. However, we contend that such implicit high-dimensional structure modeling approch inadequately represents the local geometric structure of point clouds due to the absence of explicit structural information. Hence, we introduce X-3D, an explicit 3D structure modeling approach. X-3D functions by capturing the explicit local structural information within the input 3D space and employing it to produce dynamic kernels with shared weights for all neighborhood points within the current local region. This modeling approach introduces effective geometric prior and significantly diminishes the disparity between the local structure of the embedding space and the original input point cloud, thereby improving the extraction of local features. Experiments show that our method can be used on a variety of methods and achieves state-of-the-art performance on segmentation, classification, detection tasks with lower extra computational cost, such as \textbf{90.7\%} on ScanObjectNN for classification, \textbf{79.2\%} on S3DIS 6 fold and \textbf{74.3\%} on S3DIS Area 5 for segmentation, \textbf{76.3\%} on ScanNetV2 for segmentation and \textbf{64.5\%} mAP , \textbf{46.9\%} mAP on SUN RGB-D and \textbf{69.0\%} mAP , \textbf{51.1\%} mAP on ScanNetV2 . Our code is available at \href{https://github.com/sunshuofeng/X-3D}{https://github.com/sunshuofeng/X-3D}.
Anyview: Generalizable Indoor 3D Object Detection with Variable Frames
Oct 09, 2023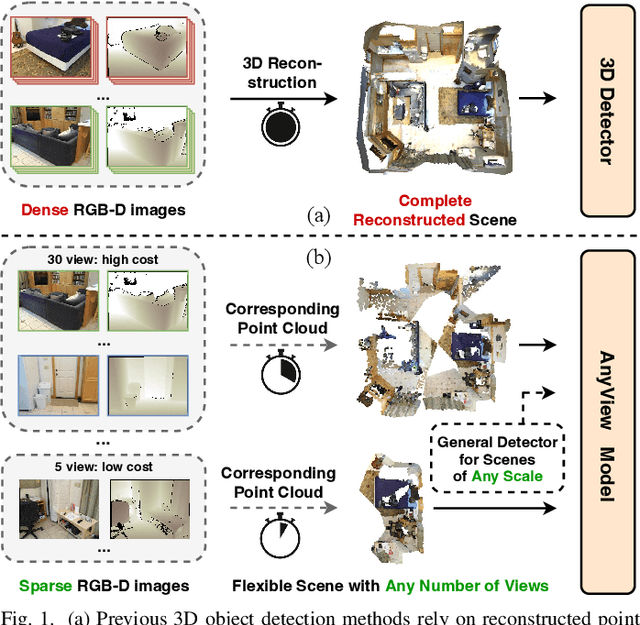
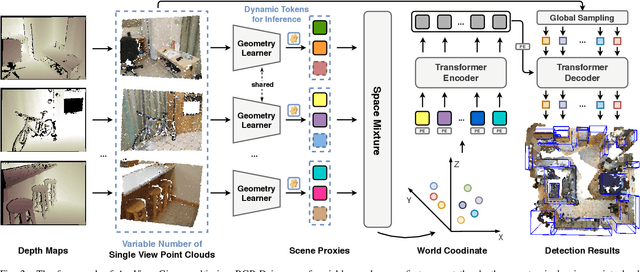

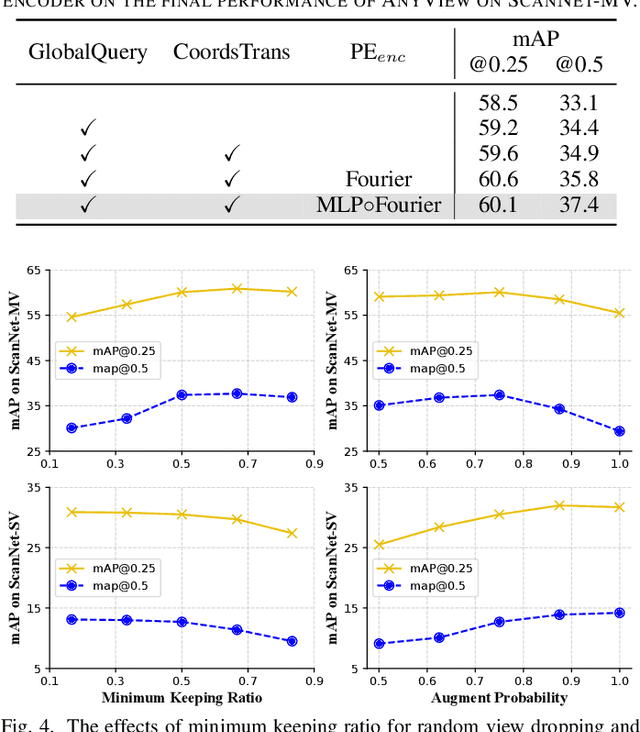
In this paper, we propose a novel network framework for indoor 3D object detection to handle variable input frame numbers in practical scenarios. Existing methods only consider fixed frames of input data for a single detector, such as monocular RGB-D images or point clouds reconstructed from dense multi-view RGB-D images. While in practical application scenes such as robot navigation and manipulation, the raw input to the 3D detectors is the RGB-D images with variable frame numbers instead of the reconstructed scene point cloud. However, the previous approaches can only handle fixed frame input data and have poor performance with variable frame input. In order to facilitate 3D object detection methods suitable for practical tasks, we present a novel 3D detection framework named AnyView for our practical applications, which generalizes well across different numbers of input frames with a single model. To be specific, we propose a geometric learner to mine the local geometric features of each input RGB-D image frame and implement local-global feature interaction through a designed spatial mixture module. Meanwhile, we further utilize a dynamic token strategy to adaptively adjust the number of extracted features for each frame, which ensures consistent global feature density and further enhances the generalization after fusion. Extensive experiments on the ScanNet dataset show our method achieves both great generalizability and high detection accuracy with a simple and clean architecture containing a similar amount of parameters with the baselines.
Embodied Task Planning with Large Language Models
Jul 04, 2023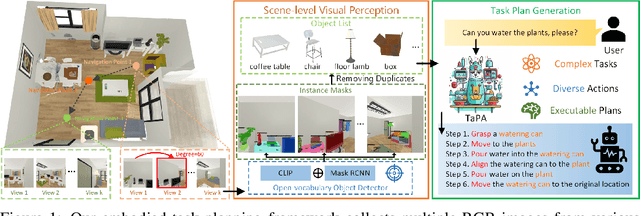

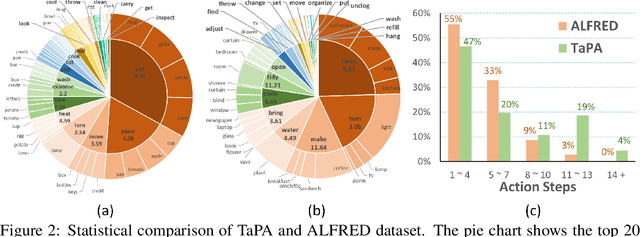
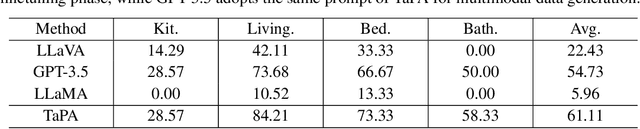
Equipping embodied agents with commonsense is important for robots to successfully complete complex human instructions in general environments. Recent large language models (LLM) can embed rich semantic knowledge for agents in plan generation of complex tasks, while they lack the information about the realistic world and usually yield infeasible action sequences. In this paper, we propose a TAsk Planing Agent (TaPA) in embodied tasks for grounded planning with physical scene constraint, where the agent generates executable plans according to the existed objects in the scene by aligning LLMs with the visual perception models. Specifically, we first construct a multimodal dataset containing triplets of indoor scenes, instructions and action plans, where we provide the designed prompts and the list of existing objects in the scene for GPT-3.5 to generate a large number of instructions and corresponding planned actions. The generated data is leveraged for grounded plan tuning of pre-trained LLMs. During inference, we discover the objects in the scene by extending open-vocabulary object detectors to multi-view RGB images collected in different achievable locations. Experimental results show that the generated plan from our TaPA framework can achieve higher success rate than LLaVA and GPT-3.5 by a sizable margin, which indicates the practicality of embodied task planning in general and complex environments.
Dense Hybrid Proposal Modulation for Lane Detection
Apr 28, 2023In this paper, we present a dense hybrid proposal modulation (DHPM) method for lane detection. Most existing methods perform sparse supervision on a subset of high-scoring proposals, while other proposals fail to obtain effective shape and location guidance, resulting in poor overall quality. To address this, we densely modulate all proposals to generate topologically and spatially high-quality lane predictions with discriminative representations. Specifically, we first ensure that lane proposals are physically meaningful by applying single-lane shape and location constraints. Benefitting from the proposed proposal-to-label matching algorithm, we assign each proposal a target ground truth lane to efficiently learn from spatial layout priors. To enhance the generalization and model the inter-proposal relations, we diversify the shape difference of proposals matching the same ground-truth lane. In addition to the shape and location constraints, we design a quality-aware classification loss to adaptively supervise each positive proposal so that the discriminative power can be further boosted. Our DHPM achieves very competitive performances on four popular benchmark datasets. Moreover, we consistently outperform the baseline model on most metrics without introducing new parameters and reducing inference speed.
Category-level Shape Estimation for Densely Cluttered Objects
Feb 23, 2023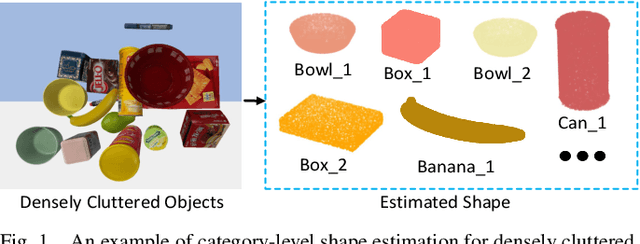
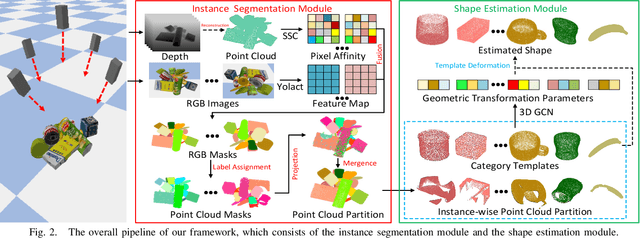
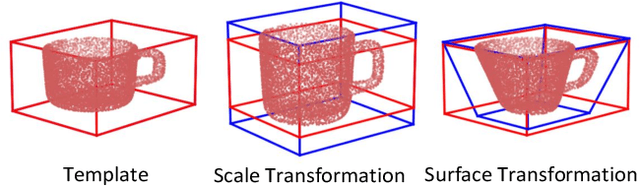
Accurately estimating the shape of objects in dense clutters makes important contribution to robotic packing, because the optimal object arrangement requires the robot planner to acquire shape information of all existed objects. However, the objects for packing are usually piled in dense clutters with severe occlusion, and the object shape varies significantly across different instances for the same category. They respectively cause large object segmentation errors and inaccurate shape recovery on unseen instances, which both degrade the performance of shape estimation during deployment. In this paper, we propose a category-level shape estimation method for densely cluttered objects. Our framework partitions each object in the clutter via the multi-view visual information fusion to achieve high segmentation accuracy, and the instance shape is recovered by deforming the category templates with diverse geometric transformations to obtain strengthened generalization ability. Specifically, we first collect the multi-view RGB-D images of the object clutters for point cloud reconstruction. Then we fuse the feature maps representing the visual information of multi-view RGB images and the pixel affinity learned from the clutter point cloud, where the acquired instance segmentation masks of multi-view RGB images are projected to partition the clutter point cloud. Finally, the instance geometry information is obtained from the partially observed instance point cloud and the corresponding category template, and the deformation parameters regarding the template are predicted for shape estimation. Experiments in the simulated environment and real world show that our method achieves high shape estimation accuracy for densely cluttered everyday objects with various shapes.