 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHY-Embodied-0.5: Embodied Foundation Models for Real-World Agents
Apr 08, 2026We introduce HY-Embodied-0.5, a family of foundation models specifically designed for real-world embodied agents. To bridge the gap between general Vision-Language Models (VLMs) and the demands of embodied agents, our models are developed to enhance the core capabilities required by embodied intelligence: spatial and temporal visual perception, alongside advanced embodied reasoning for prediction, interaction, and planning. The HY-Embodied-0.5 suite comprises two primary variants: an efficient model with 2B activated parameters designed for edge deployment, and a powerful model with 32B activated parameters targeted for complex reasoning. To support the fine-grained visual perception essential for embodied tasks, we adopt a Mixture-of-Transformers (MoT) architecture to enable modality-specific computing. By incorporating latent tokens, this design effectively enhances the perceptual representation of the models. To improve reasoning capabilities, we introduce an iterative, self-evolving post-training paradigm. Furthermore, we employ on-policy distillation to transfer the advanced capabilities of the large model to the smaller variant, thereby maximizing the performance potential of the compact model. Extensive evaluations across 22 benchmarks, spanning visual perception, spatial reasoning, and embodied understanding, demonstrate the effectiveness of our approach. Our MoT-2B model outperforms similarly sized state-of-the-art models on 16 benchmarks, while the 32B variant achieves performance comparable to frontier models such as Gemini 3.0 Pro. In downstream robot control experiments, we leverage our robust VLM foundation to train an effective Vision-Language-Action (VLA) model, achieving compelling results in real-world physical evaluations. Code and models are open-sourced at https://github.com/Tencent-Hunyuan/HY-Embodied.
Insight-V++: Towards Advanced Long-Chain Visual Reasoning with Multimodal Large Language Models
Mar 18, 2026Large Language Models (LLMs) have achieved remarkable reliability and advanced capabilities through extended test-time reasoning. However, extending these capabilities to Multi-modal Large Language Models (MLLMs) remains a significant challenge due to a critical scarcity of high-quality, long-chain reasoning data and optimized training pipelines. To bridge this gap, we present a unified multi-agent visual reasoning framework that systematically evolves from our foundational image-centric model, Insight-V, into a generalized spatial-temporal architecture, Insight-V++. We first propose a scalable data generation pipeline equipped with multi-granularity assessment that autonomously synthesizes structured, complex reasoning trajectories across image and video domains without human intervention. Recognizing that directly supervising MLLMs with such intricate data yields sub-optimal results, we design a dual-agent architecture comprising a reasoning agent to execute extensive analytical chains, and a summary agent to critically evaluate and distill final outcomes. While our initial framework utilized Direct Preference Optimization (DPO), its off-policy nature fundamentally constrained reinforcement learning potential. To overcome these limitations, particularly for long-horizon video understanding, Insight-V++ introduces two novel algorithms, ST-GRPO and J-GRPO, which enhance spatial-temporal reasoning and improve evaluative robustness. Crucially, by leveraging reliable feedback from the summary agent, we guide an iterative reasoning path generation process, retraining the entire multi-agent system in a continuous, self-improving loop. Extensive experiments on base models like LLaVA-NeXT and Qwen2.5-VL demonstrate significant performance gains across challenging image and video reasoning benchmarks while preserving strong capabilities on traditional perception-focused tasks.
Spatial-TTT: Streaming Visual-based Spatial Intelligence with Test-Time Training
Mar 12, 2026Humans perceive and understand real-world spaces through a stream of visual observations. Therefore, the ability to streamingly maintain and update spatial evidence from potentially unbounded video streams is essential for spatial intelligence. The core challenge is not simply longer context windows but how spatial information is selected, organized, and retained over time. In this paper, we propose Spatial-TTT towards streaming visual-based spatial intelligence with test-time training (TTT), which adapts a subset of parameters (fast weights) to capture and organize spatial evidence over long-horizon scene videos. Specifically, we design a hybrid architecture and adopt large-chunk updates parallel with sliding-window attention for efficient spatial video processing. To further promote spatial awareness, we introduce a spatial-predictive mechanism applied to TTT layers with 3D spatiotemporal convolution, which encourages the model to capture geometric correspondence and temporal continuity across frames. Beyond architecture design, we construct a dataset with dense 3D spatial descriptions, which guides the model to update its fast weights to memorize and organize global 3D spatial signals in a structured manner. Extensive experiments demonstrate that Spatial-TTT improves long-horizon spatial understanding and achieves state-of-the-art performance on video spatial benchmarks. Project page: https://liuff19.github.io/Spatial-TTT.
GeoVista: Web-Augmented Agentic Visual Reasoning for Geolocalization
Nov 19, 2025Current research on agentic visual reasoning enables deep multimodal understanding but primarily focuses on image manipulation tools, leaving a gap toward more general-purpose agentic models. In this work, we revisit the geolocalization task, which requires not only nuanced visual grounding but also web search to confirm or refine hypotheses during reasoning. Since existing geolocalization benchmarks fail to meet the need for high-resolution imagery and the localization challenge for deep agentic reasoning, we curate GeoBench, a benchmark that includes photos and panoramas from around the world, along with a subset of satellite images of different cities to rigorously evaluate the geolocalization ability of agentic models. We also propose GeoVista, an agentic model that seamlessly integrates tool invocation within the reasoning loop, including an image-zoom-in tool to magnify regions of interest and a web-search tool to retrieve related web information. We develop a complete training pipeline for it, including a cold-start supervised fine-tuning (SFT) stage to learn reasoning patterns and tool-use priors, followed by a reinforcement learning (RL) stage to further enhance reasoning ability. We adopt a hierarchical reward to leverage multi-level geographical information and improve overall geolocalization performance. Experimental results show that GeoVista surpasses other open-source agentic models on the geolocalization task greatly and achieves performance comparable to closed-source models such as Gemini-2.5-flash and GPT-5 on most metrics.
X-Omni: Reinforcement Learning Makes Discrete Autoregressive Image Generative Models Great Again
Jul 29, 2025Numerous efforts have been made to extend the ``next token prediction'' paradigm to visual contents, aiming to create a unified approach for both image generation and understanding. Nevertheless, attempts to generate images through autoregressive modeling with discrete tokens have been plagued by issues such as low visual fidelity, distorted outputs, and failure to adhere to complex instructions when rendering intricate details. These shortcomings are likely attributed to cumulative errors during autoregressive inference or information loss incurred during the discretization process. Probably due to this challenge, recent research has increasingly shifted toward jointly training image generation with diffusion objectives and language generation with autoregressive objectives, moving away from unified modeling approaches. In this work, we demonstrate that reinforcement learning can effectively mitigate artifacts and largely enhance the generation quality of a discrete autoregressive modeling method, thereby enabling seamless integration of image and language generation. Our framework comprises a semantic image tokenizer, a unified autoregressive model for both language and images, and an offline diffusion decoder for image generation, termed X-Omni. X-Omni achieves state-of-the-art performance in image generation tasks using a 7B language model, producing images with high aesthetic quality while exhibiting strong capabilities in following instructions and rendering long texts.
Vision Generalist Model: A Survey
Jun 11, 2025Recently, we have witnessed the great success of the generalist model in natural language processing. The generalist model is a general framework trained with massive data and is able to process various downstream tasks simultaneously. Encouraged by their impressive performance, an increasing number of researchers are venturing into the realm of applying these models to computer vision tasks. However, the inputs and outputs of vision tasks are more diverse, and it is difficult to summarize them as a unified representation. In this paper, we provide a comprehensive overview of the vision generalist models, delving into their characteristics and capabilities within the field. First, we review the background, including the datasets, tasks, and benchmarks. Then, we dig into the design of frameworks that have been proposed in existing research, while also introducing the techniques employed to enhance their performance. To better help the researchers comprehend the area, we take a brief excursion into related domains, shedding light on their interconnections and potential synergies. To conclude, we provide some real-world application scenarios, undertake a thorough examination of the persistent challenges, and offer insights into possible directions for future research endeavors.
SparseMM: Head Sparsity Emerges from Visual Concept Responses in MLLMs
Jun 05, 2025Multimodal Large Language Models (MLLMs) are commonly derived by extending pre-trained Large Language Models (LLMs) with visual capabilities. In this work, we investigate how MLLMs process visual inputs by analyzing their attention mechanisms. We reveal a surprising sparsity phenomenon: only a small subset (approximately less than 5%) of attention heads in LLMs actively contribute to visual understanding, termed visual heads. To identify these heads efficiently, we design a training-free framework that quantifies head-level visual relevance through targeted response analysis. Building on this discovery, we introduce SparseMM, a KV-Cache optimization strategy that allocates asymmetric computation budgets to heads in LLMs based on their visual scores, leveraging the sparity of visual heads for accelerating the inference of MLLMs. Compared with prior KV-Cache acceleration methods that ignore the particularity of visual, SparseMM prioritizes stress and retaining visual semantics during decoding. Extensive evaluations across mainstream multimodal benchmarks demonstrate that SparseMM achieves superior accuracy-efficiency trade-offs. Notably, SparseMM delivers 1.38x real-time acceleration and 52% memory reduction during generation while maintaining performance parity on efficiency test. Our project is open sourced at https://github.com/CR400AF-A/SparseMM.
Unveiling the Compositional Ability Gap in Vision-Language Reasoning Model
May 26, 2025While large language models (LLMs) demonstrate strong reasoning capabilities utilizing reinforcement learning (RL) with verifiable reward, whether large vision-language models (VLMs) can directly inherit such capabilities through similar post-training strategies remains underexplored. In this work, we conduct a systematic compositional probing study to evaluate whether current VLMs trained with RL or other post-training strategies can compose capabilities across modalities or tasks under out-of-distribution conditions. We design a suite of diagnostic tasks that train models on unimodal tasks or isolated reasoning skills, and evaluate them on multimodal, compositional variants requiring skill integration. Through comparisons between supervised fine-tuning (SFT) and RL-trained models, we identify three key findings: (1) RL-trained models consistently outperform SFT on compositional generalization, demonstrating better integration of learned skills; (2) although VLMs achieve strong performance on individual tasks, they struggle to generalize compositionally under cross-modal and cross-task scenario, revealing a significant gap in current training strategies; (3) enforcing models to explicitly describe visual content before reasoning (e.g., caption-before-thinking), along with rewarding progressive vision-to-text grounding, yields notable gains. It highlights two essential ingredients for improving compositionality in VLMs: visual-to-text alignment and accurate visual grounding. Our findings shed light on the current limitations of RL-based reasoning VLM training and provide actionable insights toward building models that reason compositionally across modalities and tasks.
R-Bench: Graduate-level Multi-disciplinary Benchmarks for LLM & MLLM Complex Reasoning Evaluation
May 04, 2025Reasoning stands as a cornerstone of intelligence, enabling the synthesis of existing knowledge to solve complex problems. Despite remarkable progress, existing reasoning benchmarks often fail to rigorously evaluate the nuanced reasoning capabilities required for complex, real-world problemsolving, particularly in multi-disciplinary and multimodal contexts. In this paper, we introduce a graduate-level, multi-disciplinary, EnglishChinese benchmark, dubbed as Reasoning Bench (R-Bench), for assessing the reasoning capability of both language and multimodal models. RBench spans 1,094 questions across 108 subjects for language model evaluation and 665 questions across 83 subjects for multimodal model testing in both English and Chinese. These questions are meticulously curated to ensure rigorous difficulty calibration, subject balance, and crosslinguistic alignment, enabling the assessment to be an Olympiad-level multi-disciplinary benchmark. We evaluate widely used models, including OpenAI o1, GPT-4o, DeepSeek-R1, etc. Experimental results indicate that advanced models perform poorly on complex reasoning, especially multimodal reasoning. Even the top-performing model OpenAI o1 achieves only 53.2% accuracy on our multimodal evaluation. Data and code are made publicly available at here.
BREEN: Bridge Data-Efficient Encoder-Free Multimodal Learning with Learnable Queries
Mar 16, 2025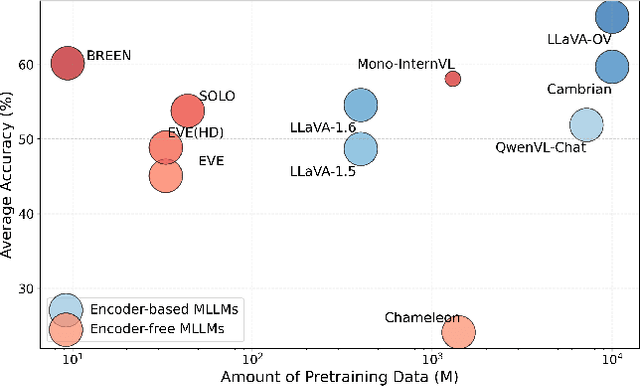
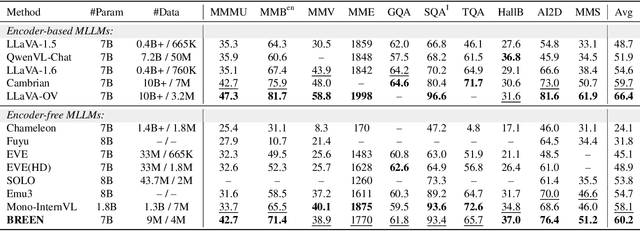
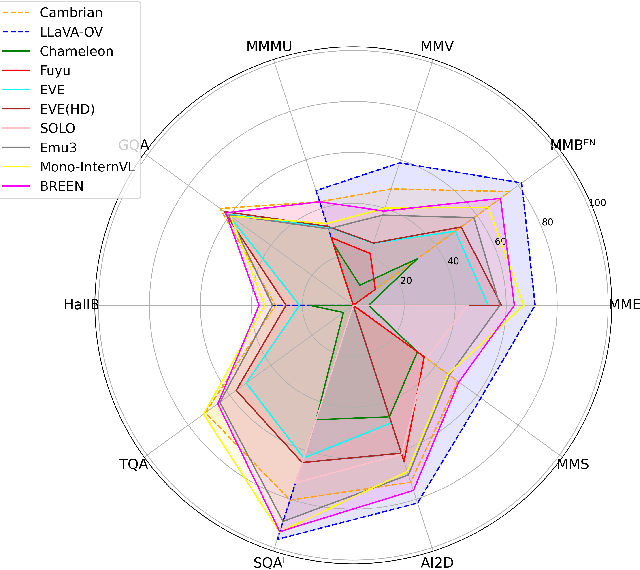
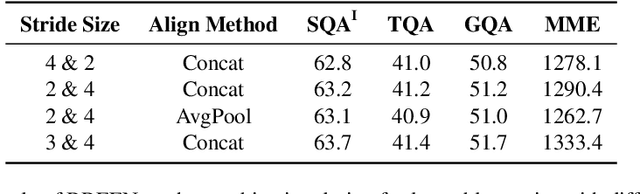
Encoder-free multimodal large language models(MLLMs) eliminate the need for a well-trained vision encoder by directly processing image tokens before the language model. While this approach reduces computational overhead and model complexity, it often requires large amounts of training data to effectively capture the visual knowledge typically encoded by vision models like CLIP. The absence of a vision encoder implies that the model is likely to rely on substantial data to learn the necessary visual-semantic alignments. In this work, we present BREEN, a data-efficient encoder-free multimodal architecture that mitigates this issue. BREEN leverages a learnable query and image experts to achieve comparable performance with significantly less training data. The learnable query, positioned between image and text tokens, is supervised by the output of a pretrained CLIP model to distill visual knowledge, bridging the gap between visual and textual modalities. Additionally, the image expert processes image tokens and learnable queries independently, improving efficiency and reducing interference with the LLM's textual capabilities. BREEN achieves comparable performance to prior encoder-free state-of-the-art models like Mono-InternVL, using only 13 million text-image pairs in training about one percent of the data required by existing methods. Our work highlights a promising direction for data-efficient encoder-free multimodal learning, offering an alternative to traditional encoder-based approaches.