 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriplets Better Than Pairs: Towards Stable and Effective Self-Play Fine-Tuning for LLMs
Jan 13, 2026Recently, self-play fine-tuning (SPIN) has been proposed to adapt large language models to downstream applications with scarce expert-annotated data, by iteratively generating synthetic responses from the model itself. However, SPIN is designed to optimize the current reward advantages of annotated responses over synthetic responses at hand, which may gradually vanish during iterations, leading to unstable optimization. Moreover, the utilization of reference policy induces a misalignment issue between the reward formulation for training and the metric for generation. To address these limitations, we propose a novel Triplet-based Self-Play fIne-tuNing (T-SPIN) method that integrates two key designs. First, beyond current advantages, T-SPIN additionally incorporates historical advantages between iteratively generated responses and proto-synthetic responses produced by the initial policy. Even if the current advantages diminish, historical advantages remain effective, stabilizing the overall optimization. Second, T-SPIN introduces the entropy constraint into the self-play framework, which is theoretically justified to support reference-free fine-tuning, eliminating the training-generation discrepancy. Empirical results on various tasks demonstrate not only the superior performance of T-SPIN over SPIN, but also its stable evolution during iterations. Remarkably, compared to supervised fine-tuning, T-SPIN achieves comparable or even better performance with only 25% samples, highlighting its effectiveness when faced with scarce annotated data.
Multimodal Tabular Reasoning with Privileged Structured Information
Jun 04, 2025Tabular reasoning involves multi-step information extraction and logical inference over tabular data. While recent advances have leveraged large language models (LLMs) for reasoning over structured tables, such high-quality textual representations are often unavailable in real-world settings, where tables typically appear as images. In this paper, we tackle the task of tabular reasoning from table images, leveraging privileged structured information available during training to enhance multimodal large language models (MLLMs). The key challenges lie in the complexity of accurately aligning structured information with visual representations, and in effectively transferring structured reasoning skills to MLLMs despite the input modality gap. To address these, we introduce TabUlar Reasoning with Bridged infOrmation ({\sc Turbo}), a new framework for multimodal tabular reasoning with privileged structured tables. {\sc Turbo} benefits from a structure-aware reasoning trace generator based on DeepSeek-R1, contributing to high-quality modality-bridged data. On this basis, {\sc Turbo} repeatedly generates and selects the advantageous reasoning paths, further enhancing the model's tabular reasoning ability. Experimental results demonstrate that, with limited ($9$k) data, {\sc Turbo} achieves state-of-the-art performance ($+7.2\%$ vs. previous SOTA) across multiple datasets.
Mitigating Visual Forgetting via Take-along Visual Conditioning for Multi-modal Long CoT Reasoning
Mar 17, 2025Recent advancements in Large Language Models (LLMs) have demonstrated enhanced reasoning capabilities, evolving from Chain-of-Thought (CoT) prompting to advanced, product-oriented solutions like OpenAI o1. During our re-implementation of this model, we noticed that in multimodal tasks requiring visual input (e.g., geometry problems), Multimodal LLMs (MLLMs) struggle to maintain focus on the visual information, in other words, MLLMs suffer from a gradual decline in attention to visual information as reasoning progresses, causing text-over-relied outputs. To investigate this, we ablate image inputs during long-chain reasoning. Concretely, we truncate the reasoning process midway, then re-complete the reasoning process with the input image removed. We observe only a ~2% accuracy drop on MathVista's test-hard subset, revealing the model's textual outputs dominate the following reasoning process. Motivated by this, we propose Take-along Visual Conditioning (TVC), a strategy that shifts image input to critical reasoning stages and compresses redundant visual tokens via dynamic pruning. This methodology helps the model retain attention to the visual components throughout the reasoning. Our approach achieves state-of-the-art performance on average across five mathematical reasoning benchmarks (+3.4% vs previous sota), demonstrating the effectiveness of TVC in enhancing multimodal reasoning systems.
MOS: Model Surgery for Pre-Trained Model-Based Class-Incremental Learning
Dec 12, 2024Class-Incremental Learning (CIL) requires models to continually acquire knowledge of new classes without forgetting old ones. Despite Pre-trained Models (PTMs) have shown excellent performance in CIL, catastrophic forgetting still occurs as the model learns new concepts. Existing work seeks to utilize lightweight components to adjust the PTM, while the forgetting phenomenon still comes from {\em parameter and retrieval} levels. Specifically, iterative updates of the model result in parameter drift, while mistakenly retrieving irrelevant modules leads to the mismatch during inference. To this end, we propose MOdel Surgery (MOS) to rescue the model from forgetting previous knowledge. By training task-specific adapters, we continually adjust the PTM to downstream tasks. To mitigate parameter-level forgetting, we present an adapter merging approach to learn task-specific adapters, which aims to bridge the gap between different components while reserve task-specific information. Besides, to address retrieval-level forgetting, we introduce a training-free self-refined adapter retrieval mechanism during inference, which leverages the model's inherent ability for better adapter retrieval. By jointly rectifying the model with those steps, MOS can robustly resist catastrophic forgetting in the learning process. Extensive experiments on seven benchmark datasets validate MOS's state-of-the-art performance. Code is available at: https://github.com/sun-hailong/AAAI25-MOS
Insight-V: Exploring Long-Chain Visual Reasoning with Multimodal Large Language Models
Nov 21, 2024



Large Language Models (LLMs) demonstrate enhanced capabilities and reliability by reasoning more, evolving from Chain-of-Thought prompting to product-level solutions like OpenAI o1. Despite various efforts to improve LLM reasoning, high-quality long-chain reasoning data and optimized training pipelines still remain inadequately explored in vision-language tasks. In this paper, we present Insight-V, an early effort to 1) scalably produce long and robust reasoning data for complex multi-modal tasks, and 2) an effective training pipeline to enhance the reasoning capabilities of multi-modal large language models (MLLMs). Specifically, to create long and structured reasoning data without human labor, we design a two-step pipeline with a progressive strategy to generate sufficiently long and diverse reasoning paths and a multi-granularity assessment method to ensure data quality. We observe that directly supervising MLLMs with such long and complex reasoning data will not yield ideal reasoning ability. To tackle this problem, we design a multi-agent system consisting of a reasoning agent dedicated to performing long-chain reasoning and a summary agent trained to judge and summarize reasoning results. We further incorporate an iterative DPO algorithm to enhance the reasoning agent's generation stability and quality. Based on the popular LLaVA-NeXT model and our stronger base MLLM, we demonstrate significant performance gains across challenging multi-modal benchmarks requiring visual reasoning. Benefiting from our multi-agent system, Insight-V can also easily maintain or improve performance on perception-focused multi-modal tasks.
Parrot: Multilingual Visual Instruction Tuning
Jun 04, 2024
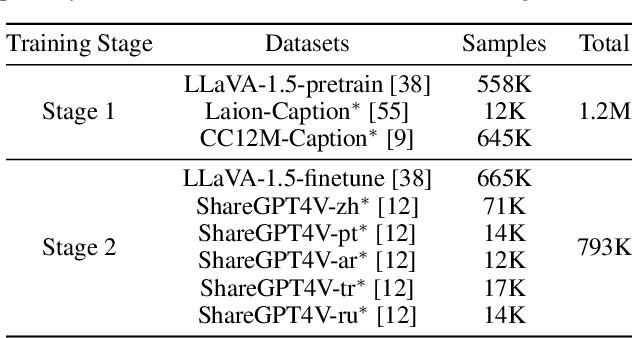


The rapid development of Multimodal Large Language Models (MLLMs) like GPT-4V has marked a significant step towards artificial general intelligence. Existing methods mainly focus on aligning vision encoders with LLMs through supervised fine-tuning (SFT) to endow LLMs with multimodal abilities, making MLLMs' inherent ability to react to multiple languages progressively deteriorate as the training process evolves. We empirically find that the imbalanced SFT datasets, primarily composed of English-centric image-text pairs, lead to significantly reduced performance in non-English languages. This is due to the failure of aligning the vision encoder and LLM with multilingual tokens during the SFT process. In this paper, we introduce Parrot, a novel method that utilizes textual guidance to drive visual token alignment at the language level. Parrot makes the visual tokens condition on diverse language inputs and uses Mixture-of-Experts (MoE) to promote the alignment of multilingual tokens. Specifically, to enhance non-English visual tokens alignment, we compute the cross-attention using the initial visual features and textual embeddings, the result of which is then fed into the MoE router to select the most relevant experts. The selected experts subsequently convert the initial visual tokens into language-specific visual tokens. Moreover, considering the current lack of benchmarks for evaluating multilingual capabilities within the field, we collect and make available a Massive Multilingual Multimodal Benchmark which includes 6 languages, 15 categories, and 12,000 questions, named as MMMB. Our method not only demonstrates state-of-the-art performance on multilingual MMBench and MMMB, but also excels across a broad range of multimodal tasks. Both the source code and the training dataset of Parrot will be made publicly available.
Expandable Subspace Ensemble for Pre-Trained Model-Based Class-Incremental Learning
Mar 18, 2024



Class-Incremental Learning (CIL) requires a learning system to continually learn new classes without forgetting. Despite the strong performance of Pre-Trained Models (PTMs) in CIL, a critical issue persists: learning new classes often results in the overwriting of old ones. Excessive modification of the network causes forgetting, while minimal adjustments lead to an inadequate fit for new classes. As a result, it is desired to figure out a way of efficient model updating without harming former knowledge. In this paper, we propose ExpAndable Subspace Ensemble (EASE) for PTM-based CIL. To enable model updating without conflict, we train a distinct lightweight adapter module for each new task, aiming to create task-specific subspaces. These adapters span a high-dimensional feature space, enabling joint decision-making across multiple subspaces. As data evolves, the expanding subspaces render the old class classifiers incompatible with new-stage spaces. Correspondingly, we design a semantic-guided prototype complement strategy that synthesizes old classes' new features without using any old class instance. Extensive experiments on seven benchmark datasets verify EASE's state-of-the-art performance. Code is available at: https://github.com/sun-hailong/CVPR24-Ease
Continual Learning with Pre-Trained Models: A Survey
Jan 29, 2024



Nowadays, real-world applications often face streaming data, which requires the learning system to absorb new knowledge as data evolves. Continual Learning (CL) aims to achieve this goal and meanwhile overcome the catastrophic forgetting of former knowledge when learning new ones. Typical CL methods build the model from scratch to grow with incoming data. However, the advent of the pre-trained model (PTM) era has sparked immense research interest, particularly in leveraging PTMs' robust representational capabilities. This paper presents a comprehensive survey of the latest advancements in PTM-based CL. We categorize existing methodologies into three distinct groups, providing a comparative analysis of their similarities, differences, and respective advantages and disadvantages. Additionally, we offer an empirical study contrasting various state-of-the-art methods to highlight concerns regarding fairness in comparisons. The source code to reproduce these evaluations is available at: https://github.com/sun-hailong/LAMDA-PILOT
PILOT: A Pre-Trained Model-Based Continual Learning Toolbox
Sep 13, 2023While traditional machine learning can effectively tackle a wide range of problems, it primarily operates within a closed-world setting, which presents limitations when dealing with streaming data. As a solution, incremental learning emerges to address real-world scenarios involving new data's arrival. Recently, pre-training has made significant advancements and garnered the attention of numerous researchers. The strong performance of these pre-trained models (PTMs) presents a promising avenue for developing continual learning algorithms that can effectively adapt to real-world scenarios. Consequently, exploring the utilization of PTMs in incremental learning has become essential. This paper introduces a pre-trained model-based continual learning toolbox known as PILOT. On the one hand, PILOT implements some state-of-the-art class-incremental learning algorithms based on pre-trained models, such as L2P, DualPrompt, and CODA-Prompt. On the other hand, PILOT also fits typical class-incremental learning algorithms (e.g., DER, FOSTER, and MEMO) within the context of pre-trained models to evaluate their effectiveness.