 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExternal Knowledge Injection for CLIP-Based Class-Incremental Learning
Mar 11, 2025Class-Incremental Learning (CIL) enables learning systems to continuously adapt to evolving data streams. With the advancement of pre-training, leveraging pre-trained vision-language models (e.g., CLIP) offers a promising starting point for CIL. However, CLIP makes decisions by matching visual embeddings to class names, overlooking the rich contextual information conveyed through language. For instance, the concept of ``cat'' can be decomposed into features like tail, fur, and face for recognition. Besides, since the model is continually updated, these detailed features are overwritten in CIL, requiring external knowledge for compensation. In this paper, we introduce ExterNal knowledGe INjEction (ENGINE) for CLIP-based CIL. To enhance knowledge transfer from outside the dataset, we propose a dual-branch injection tuning framework that encodes informative knowledge from both visual and textual modalities. The visual branch is enhanced with data augmentation to enrich the visual features, while the textual branch leverages GPT-4 to rewrite discriminative descriptors. In addition to this on-the-fly knowledge injection, we also implement post-tuning knowledge by re-ranking the prediction results during inference. With the injected knowledge, the model can better capture informative features for downstream tasks as data evolves. Extensive experiments demonstrate the state-of-the-art performance of ENGINE. Code is available at: https://github.com/RenaissCode/ENGINE
Continual Learning with Pre-Trained Models: A Survey
Jan 29, 2024



Nowadays, real-world applications often face streaming data, which requires the learning system to absorb new knowledge as data evolves. Continual Learning (CL) aims to achieve this goal and meanwhile overcome the catastrophic forgetting of former knowledge when learning new ones. Typical CL methods build the model from scratch to grow with incoming data. However, the advent of the pre-trained model (PTM) era has sparked immense research interest, particularly in leveraging PTMs' robust representational capabilities. This paper presents a comprehensive survey of the latest advancements in PTM-based CL. We categorize existing methodologies into three distinct groups, providing a comparative analysis of their similarities, differences, and respective advantages and disadvantages. Additionally, we offer an empirical study contrasting various state-of-the-art methods to highlight concerns regarding fairness in comparisons. The source code to reproduce these evaluations is available at: https://github.com/sun-hailong/LAMDA-PILOT
Learning without Forgetting for Vision-Language Models
May 30, 2023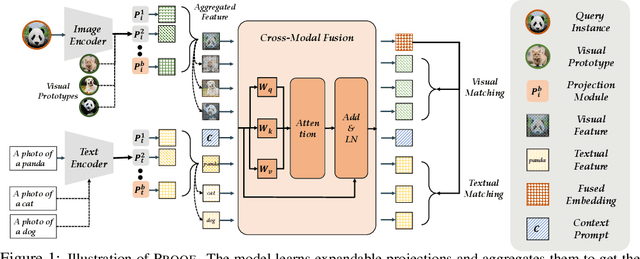
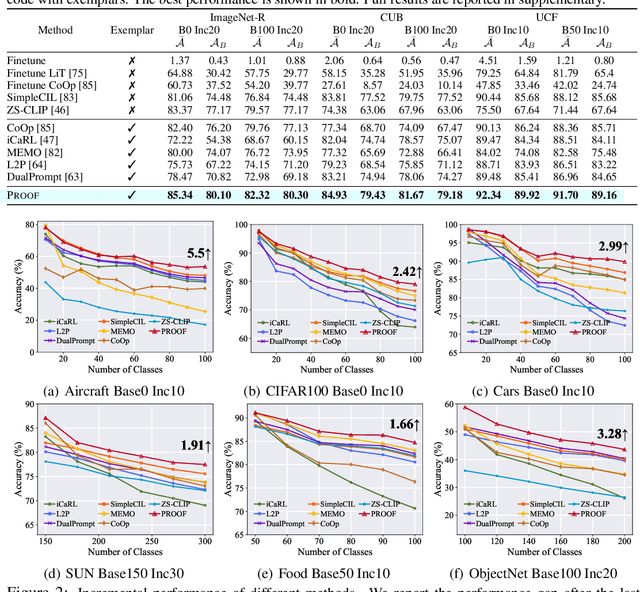
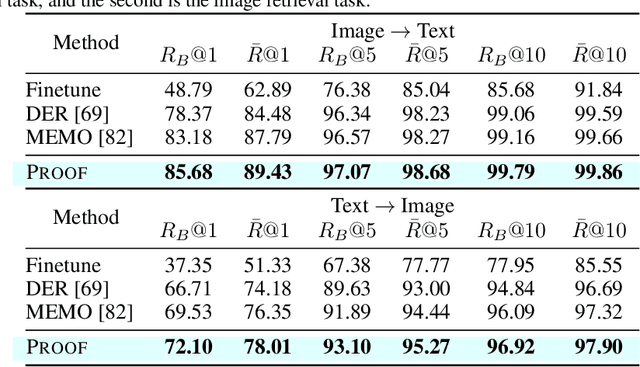
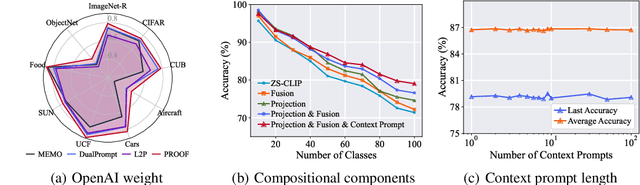
Class-Incremental Learning (CIL) or continual learning is a desired capability in the real world, which requires a learning system to adapt to new tasks without forgetting former ones. While traditional CIL methods focus on visual information to grasp core features, recent advances in Vision-Language Models (VLM) have shown promising capabilities in learning generalizable representations with the aid of textual information. However, when continually trained with new classes, VLMs often suffer from catastrophic forgetting of former knowledge. Applying VLMs to CIL poses two major challenges: 1) how to adapt the model without forgetting; and 2) how to make full use of the multi-modal information. To this end, we propose PROjectiOn Fusion (PROOF) that enables VLMs to learn without forgetting. To handle the first challenge, we propose training task-specific projections based on the frozen image/text encoders. When facing new tasks, new projections are expanded and former projections are fixed, alleviating the forgetting of old concepts. For the second challenge, we propose the fusion module to better utilize the cross-modality information. By jointly adjusting visual and textual features, the model can capture semantic information with stronger representation ability. Extensive experiments on nine benchmark datasets validate PROOF achieves state-of-the-art performance.