 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtoAda: Prototype-Guided Adaptive Adapter Expansion and Geometric Consolidation for Multimodal Continual Instruction Tuning
Jun 01, 2026Multimodal Large Language Models (MLLMs) achieve strong performance through instruction tuning, but real-world deployment requires them to continually acquire new vision-language capabilities, making Multimodal Continual Instruction Tuning (MCIT) essential. To reduce inter-task interference and promote collaboration, recent methods often employ sparse architectures like Mixture of LoRA Experts with image-text similarity routing. However, tasks with distinct response structures could share highly similar visual-linguistic semantics and thus be wrongly routed to the same expert; image-text similarity alone is insufficient for reliable task assignment. For example, an expert in a grounding task requiring coordinate prediction may be biased toward producing short textual answers after learning semantically similar VQA tasks. This format-blind task assignment integrates heterogeneous response types into shared parameters, inducing gradient interference and ineffective expert collaboration. To address this problem, we propose ProtoAda, a prototype-guided adaptive tuning framework. ProtoAda introduces format-aware task prototypes to align task assignment and routing with both task semantics and output structure, and further consolidates format-compatible updates in a geometry-aware manner to effectively reuse and progressively refine existing parameters. Extensive experiments on multiple benchmarks demonstrate that ProtoAda achieves superior performance, especially on tasks whose answer structures are easily corrupted by sequential tuning.
CRAM: Centroid-Routing and Adaptive MoE for Multimodal Continual Instruction Tuning
Jun 01, 2026Multimodal Large Language Models (MLLMs) unify heterogeneous vision-language tasks under a shared generative framework via instruction tuning, yet real-world deployment demands continuous capability expansion, making Multimodal Continual Instruction Tuning (MCIT) essential. Existing methods either update all tasks with a shared parameter set or allocate dedicated modules for each new task. Shared updates force heterogeneous tasks to compete, causing forgetting of learned capabilities. Conversely, isolated expansion prevents interference but severely limits parameter efficiency over long task streams. To address this dilemma, we propose CRAM. Specifically, by isolating task-specific patterns into independent modules, CRAM mitigates catastrophic forgetting across tasks. To further boost parameter efficiency, we utilize adaptive-rank instantiation to identify the capability gap between existing expert capability and new task demands, and dynamically allocate only the necessary parameters. To ensure stable reuse among tasks, centroid-guided routing recognizes and activates existing experts' capabilities, while an orthogonality penalty confines new updates to task-specific directions, preventing re-learning general capability. Extensive experiments across diverse benchmarks consistently demonstrate its superiority over existing methods.
AREA: Attribute Extraction and Aggregation for CLIP-Based Class-Incremental Learning
May 27, 2026Class-Incremental Learning (CIL) is important in building real-world learning systems. In CLIP-based CIL, the model performs classification by comparing similarity between visual and textual embeddings obtained from template prompts, e.g., ``a photo of a [CLASS]''. This seemingly monolithic matching process can be decomposed into two conceptually distinct stages: attribute extraction and attribute aggregation. For example, a model may recognize cat using attributes such as fur texture and whiskers. When learning a new class like car, the model must extract additional attributes like wheels and adjust how they are aggregated in the shared representation space. However, since only data from the current task is available, incremental updates can bias both attribute extraction and aggregation toward new classes, leading to catastrophic forgetting. Therefore, we propose AREA for attribute extraction and aggregation in CLIP-based CIL. To stabilize extraction, we anchor class-level visual and textual attributes on the hyperspherical embedding space via principal geodesic analysis. To stabilize aggregation, we learn lightweight task-specific experts with scoring and residual refinement, regularized by a variational information bottleneck objective. During inference, we perform routing over task attribute manifolds via optimal transport for more concise prediction. Experiments show that AREA consistently outperforms SOTA methods. Code is available at https://github.com/LAMDA-CL/ICML2026-AREA.
Prism: A Plug-in Reproducible Infrastructure for Scalable Multimodal Continual Instruction Tuning
May 25, 2026Multimodal Large Language Models (MLLMs) achieve versatility by reformulating diverse tasks into a unified instruction-following framework via instruction tuning. However, real-world deployment requires continuous adaptation to emerging tasks, motivating Multimodal Continual Instruction Tuning (MCIT). Despite its growing importance, current MCIT research is hindered by severe engineering bottlenecks. Existing methods are typically implemented by directly modifying the base MLLM codebase, which imposes substantial implementation overhead and yields method-specific architectures that severely limit code reuse and fair comparison. To address this, we introduce Prism, a plug-in reproducible codebase specifically designed for scalable MCIT research. It separates algorithmic development from the backbone implementation via a lightweight plugin registration mechanism, enabling new strategies to be integrated as independent plugins without modifying the underlying MLLM codebase, thereby eliminating structural fragmentation and accelerating method development. Prism natively supports widely used large-scale training pipeline, thereby enabling reproducible and scalable MCIT experimentation. Code is available at https://github.com/LAMDA-CL/Prism.
Unlocking Patch-Level Features for CLIP-Based Class-Incremental Learning
May 13, 2026Class-Incremental Learning (CIL) enables models to continuously integrate new knowledge while mitigating catastrophic forgetting. Driven by the remarkable generalization of CLIP, leveraging pre-trained vision-language models has become a dominant paradigm in CIL. However, current work primarily focuses on aligning global image embeddings (i.e., [CLS] token) with their corresponding text prompts (i.e., [EOS] token). Despite their good performance, we find that they discard the rich patch-level semantic information inherent in CLIP's encoders. For instance, when recognizing a rabbit, local patches may encode its distinctive cues, such as long ears and a fluffy tail, which can provide complementary evidence for recognition. Based on the above observation, we propose SPA (Semantic-guided Patch-level Alignment) for CLIP-based CIL, which aims to awaken long-neglected local representations within CLIP. Specifically, for each class, we first construct representative and diverse visual samples and feed them to GPT-5 as visual guidance to generate class-wise semantic descriptions. These descriptions are used to guide the selection of discriminative patch-level visual features. Building upon these selected patches, we further employ optimal transport to align selected patch tokens with semantic tokens from class-wise descriptions, yielding a structured cross-modal alignment that improves recognition. Furthermore, we introduce task-specific projectors for effective adaptation to downstream incremental tasks, and sample pseudo-features from stored class-wise Gaussian statistics to calibrate old-class representations, thereby mitigating catastrophic forgetting. Extensive experiments demonstrate that SPA achieves state-of-the-art performance.
Dynamic Cross-Modal Prompt Generation for Multimodal Continual Instruction Tuning
May 11, 2026Multimodal Large Language Models (MLLMs) achieve strong performance through instruction tuning, yet real-world deployment often requires continual capability expansion across sequential tasks. In such scenarios, Multimodal Continual Instruction Tuning (MCIT) aims to acquire new capabilities while limiting catastrophic forgetting. Existing methods mainly follow a module-composition paradigm: they maintain task-level prompts or LoRA experts and dynamically route or aggregate a subset of them at inference. However, samples within the same task can still differ substantially in visual scenes, question intents, and reasoning demands. This motivates instance-level adaptation to individual query-image pairs rather than only selecting or combining task-level modules. To this end, we propose DRAPE (Dynamic Cross-Modal Prompt Generation), a prompt-learning framework that synthesizes continuous instance-specific soft prompts for MCIT. Instead of selecting prompts from a fixed pool, DRAPE derives prompt queries from the textual instruction and cross-attends to visual patch features, producing query-image conditioned prompts that are prepended to the frozen LLM. To mitigate forgetting during sequential updates, DRAPE applies null-space gradient projection to the shared projector and uses CLIP-based prototype routing for task-label-free generator selection at inference. Extensive experiments on MCIT benchmarks show that DRAPE achieves state-of-the-art performance among representative prompt-based and LoRA-based continual-learning baselines.
The Golden Subspace: Where Efficiency Meets Generalization in Continual Test-Time Adaptation
Mar 23, 2026Continual Test-Time Adaptation (CTTA) aims to enable models to adapt online to unlabeled data streams under distribution shift without accessing source data. Existing CTTA methods face an efficiency-generalization trade-off: updating more parameters improves adaptation but severely reduces online inference efficiency. An ideal solution is to achieve comparable adaptation with minimal feature updates; we call this minimal subspace the golden subspace. We prove its existence in a single-step adaptation setting and show that it coincides with the row space of the pretrained classifier. To enable online maintenance of this subspace, we introduce the sample-wise Average Gradient Outer Product (AGOP) as an efficient proxy for estimating the classifier weights without retraining. Building on these insights, we propose Guided Online Low-rank Directional adaptation (GOLD), which uses a lightweight adapter to project features onto the golden subspace and learns a compact scaling vector while the subspace is dynamically updated via AGOP. Extensive experiments on classification and segmentation benchmarks, including autonomous-driving scenarios, demonstrate that GOLD attains superior efficiency, stability, and overall performance. Our code is available at https://github.com/AIGNLAI/GOLD.
SAME: Stabilized Mixture-of-Experts for Multimodal Continual Instruction Tuning
Feb 02, 2026Multimodal Large Language Models (MLLMs) achieve strong performance through instruction tuning, but real-world deployment requires them to continually expand their capabilities, making Multimodal Continual Instruction Tuning (MCIT) essential. Recent methods leverage sparse expert routing to promote task specialization, but we find that the expert routing process suffers from drift as the data distribution evolves. For example, a grounding query that previously activated localization experts may instead be routed to irrelevant experts after learning OCR tasks. Meanwhile, the grounding-related experts can be overwritten by new tasks and lose their original functionality. Such failure reflects two problems: router drift, where expert selection becomes inconsistent over time, and expert drift, where shared experts are overwritten across tasks. Therefore, we propose StAbilized Mixture-of-Experts (SAME) for MCIT. To address router drift, SAME stabilizes expert selection by decomposing routing dynamics into orthogonal subspaces and updating only task-relevant directions. To mitigate expert drift, we regulate expert updates via curvature-aware scaling using historical input covariance in a rehearsal-free manner. SAME also introduces adaptive expert activation to freeze selected experts during training, reducing redundant computation and cross-task interference. Extensive experiments demonstrate its SOTA performance.
C3Box: A CLIP-based Class-Incremental Learning Toolbox
Jan 28, 2026Traditional machine learning systems are typically designed for static data distributions, which suffer from catastrophic forgetting when learning from evolving data streams. Class-Incremental Learning (CIL) addresses this challenge by enabling learning systems to continuously learn new classes while preserving prior knowledge. With the rise of pre-trained models (PTMs) such as CLIP, leveraging their strong generalization and semantic alignment capabilities has become a promising direction in CIL. However, existing CLIP-based CIL methods are often scattered across disparate codebases, rely on inconsistent configurations, hindering fair comparisons, reproducibility, and practical adoption. Therefore, we propose C3Box (CLIP-based Class-inCremental learning toolBOX), a modular and comprehensive Python toolbox. C3Box integrates representative traditional CIL methods, ViT-based CIL methods, and state-of-the-art CLIP-based CIL methods into a unified CLIP-based framework. By inheriting the streamlined design of PyCIL, C3Box provides a JSON-based configuration and standardized execution pipeline. This design enables reproducible experimentation with low engineering overhead and makes C3Box a reliable benchmark platform for continual learning research. Designed to be user-friendly, C3Box relies only on widely used open-source libraries and supports major operating systems. The code is available at https://github.com/LAMDA-CL/C3Box.
Hierarchical Semantic Tree Anchoring for CLIP-Based Class-Incremental Learning
Nov 19, 2025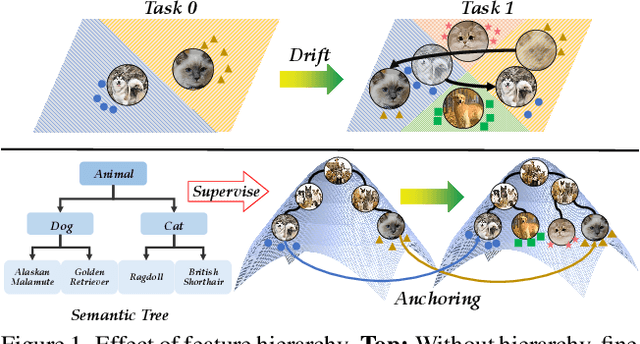
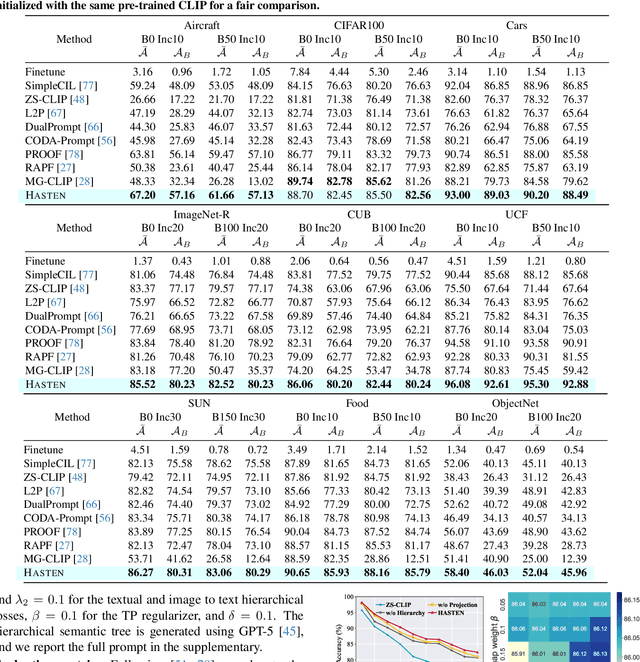
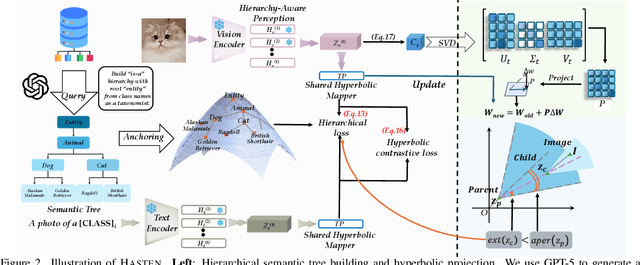
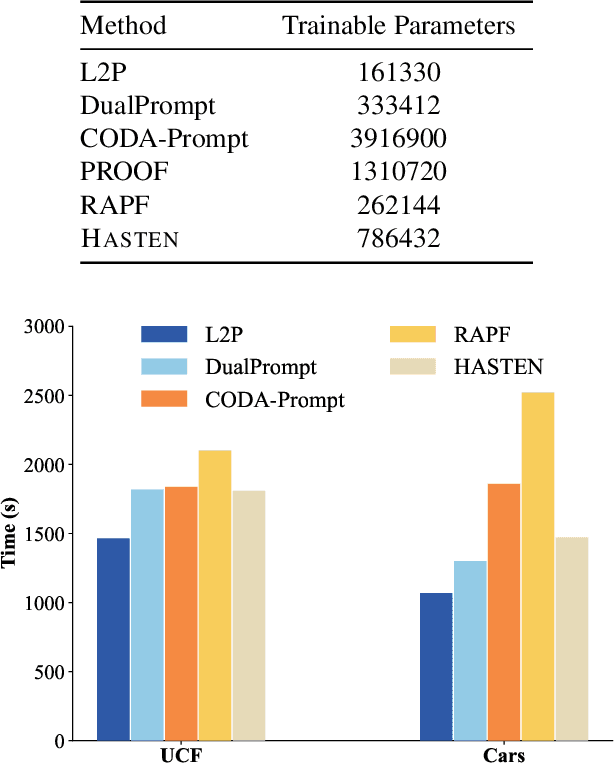
Class-Incremental Learning (CIL) enables models to learn new classes continually while preserving past knowledge. Recently, vision-language models like CLIP offer transferable features via multi-modal pre-training, making them well-suited for CIL. However, real-world visual and linguistic concepts are inherently hierarchical: a textual concept like "dog" subsumes fine-grained categories such as "Labrador" and "Golden Retriever," and each category entails its images. But existing CLIP-based CIL methods fail to explicitly capture this inherent hierarchy, leading to fine-grained class features drift during incremental updates and ultimately to catastrophic forgetting. To address this challenge, we propose HASTEN (Hierarchical Semantic Tree Anchoring) that anchors hierarchical information into CIL to reduce catastrophic forgetting. First, we employ an external knowledge graph as supervision to embed visual and textual features in hyperbolic space, effectively preserving hierarchical structure as data evolves. Second, to mitigate catastrophic forgetting, we project gradients onto the null space of the shared hyperbolic mapper, preventing interference with prior tasks. These two steps work synergistically to enable the model to resist forgetting by maintaining hierarchical relationships. Extensive experiments show that HASTEN consistently outperforms existing methods while providing a unified structured representation.