 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParaRNN: An Interpretable and Parallelizable Recurrent Neural Network for Time-Dependent Data
May 04, 2026The proliferation of large-scale and structurally complex data has spurred the integration of machine learning methods into statistical modeling. Recurrent neural networks (RNNs), a foundational class of models for time-dependent data, can be viewed as nonlinear extensions of classical autoregressive moving average models. Despite their flexibility and empirical success in machine learning, RNNs often suffer from limited interpretability and slow training, which hinders their use in statistics. This paper proposes the Parallelized RNN (ParaRNN), a novel model composed of multiple small recurrent units. ParaRNN admits an additive representation that decouples recurrent dynamics into interpretable components, whose behavior can be characterized through recurrence features. This interpretability enables its applications in nonparametric regression for time-dependent data, while the design also allows efficient parallelization. The approximation capacity and non-asymptotic prediction error bounds in a nonparametric regression setting are established for ParaRNN. Empirical results on three sequential modeling tasks further demonstrate that ParaRNN achieves performance comparable to vanilla RNNs while offering improved interpretability and efficiency.
Hierarchical Semantic Tree Anchoring for CLIP-Based Class-Incremental Learning
Nov 19, 2025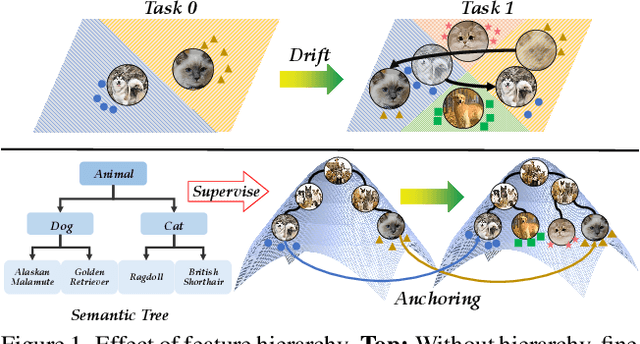
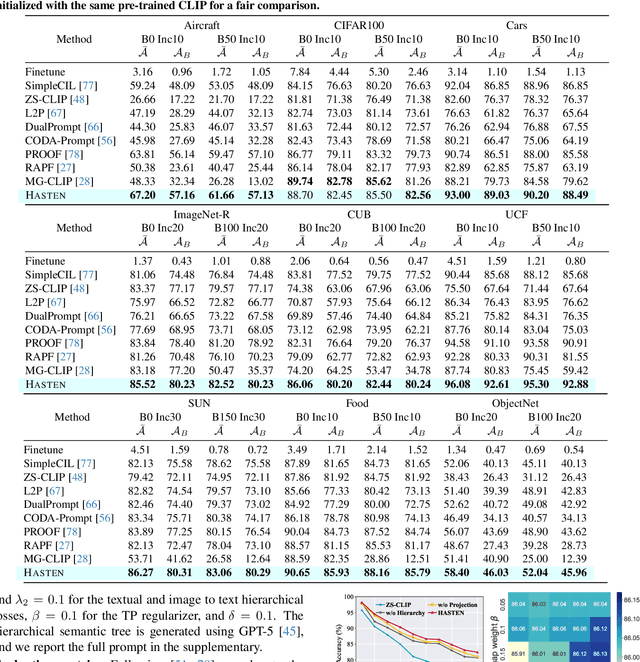
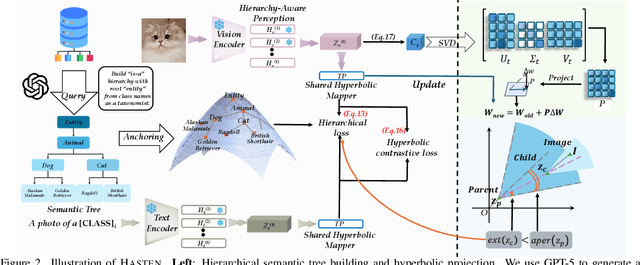
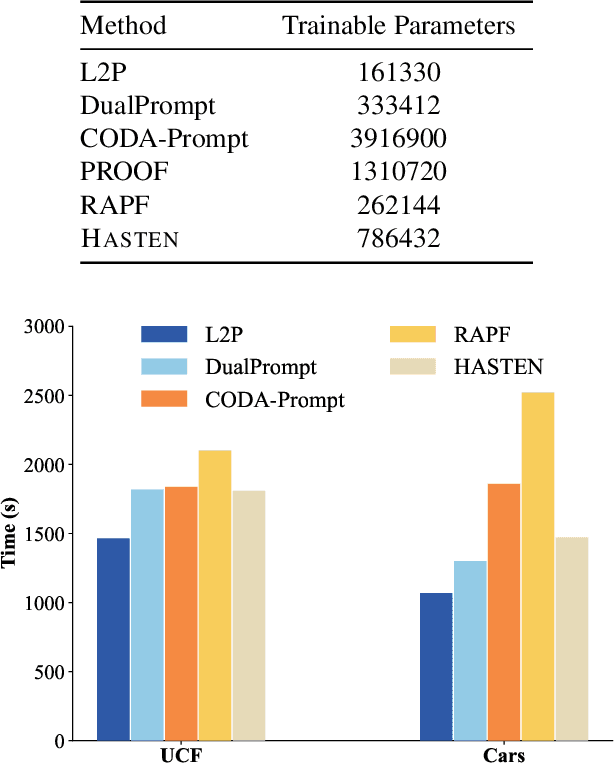
Class-Incremental Learning (CIL) enables models to learn new classes continually while preserving past knowledge. Recently, vision-language models like CLIP offer transferable features via multi-modal pre-training, making them well-suited for CIL. However, real-world visual and linguistic concepts are inherently hierarchical: a textual concept like "dog" subsumes fine-grained categories such as "Labrador" and "Golden Retriever," and each category entails its images. But existing CLIP-based CIL methods fail to explicitly capture this inherent hierarchy, leading to fine-grained class features drift during incremental updates and ultimately to catastrophic forgetting. To address this challenge, we propose HASTEN (Hierarchical Semantic Tree Anchoring) that anchors hierarchical information into CIL to reduce catastrophic forgetting. First, we employ an external knowledge graph as supervision to embed visual and textual features in hyperbolic space, effectively preserving hierarchical structure as data evolves. Second, to mitigate catastrophic forgetting, we project gradients onto the null space of the shared hyperbolic mapper, preventing interference with prior tasks. These two steps work synergistically to enable the model to resist forgetting by maintaining hierarchical relationships. Extensive experiments show that HASTEN consistently outperforms existing methods while providing a unified structured representation.
BOFA: Bridge-Layer Orthogonal Low-Rank Fusion for CLIP-Based Class-Incremental Learning
Nov 14, 2025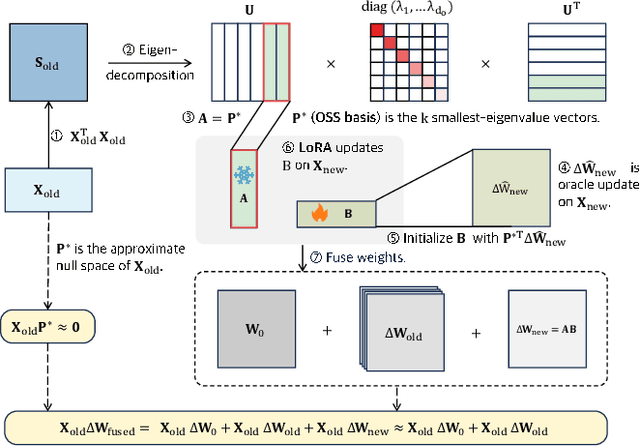
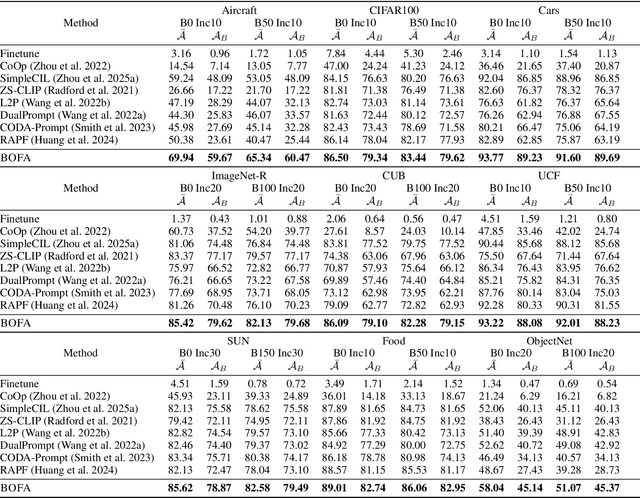
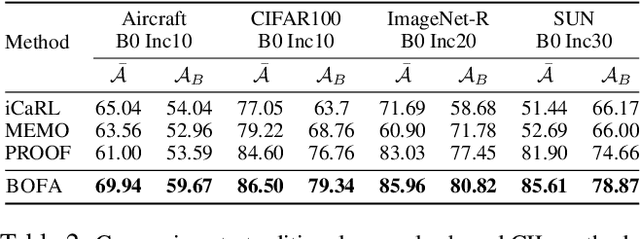
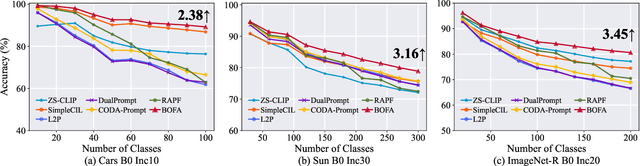
Class-Incremental Learning (CIL) aims to continually learn new categories without forgetting previously acquired knowledge. Vision-language models such as CLIP offer strong transferable representations via multi-modal supervision, making them promising for CIL. However, applying CLIP to CIL poses two major challenges: (1) adapting to downstream tasks often requires additional learnable modules, increasing model complexity and susceptibility to forgetting; and (2) while multi-modal representations offer complementary strengths, existing methods have yet to fully realize their potential in effectively integrating visual and textual modalities. To address these issues, we propose BOFA (Bridge-layer Orthogonal Fusion for Adaptation), a novel framework for CIL. BOFA confines all model adaptation exclusively to CLIP's existing cross-modal bridge-layer, thereby adding no extra parameters or inference cost. To prevent forgetting within this layer, it leverages Orthogonal Low-Rank Fusion, a mechanism that constrains parameter updates to a low-rank ``safe subspace" mathematically constructed to be orthogonal to past task features. This ensures stable knowledge accumulation without data replay. Furthermore, BOFA employs a cross-modal hybrid prototype that synergizes stable textual prototypes with visual counterparts derived from our stably adapted bridge-layer, enhancing classification performance. Extensive experiments on standard benchmarks show that BOFA achieves superior accuracy and efficiency compared to existing methods.
Addressing Imbalanced Domain-Incremental Learning through Dual-Balance Collaborative Experts
Jul 09, 2025Domain-Incremental Learning (DIL) focuses on continual learning in non-stationary environments, requiring models to adjust to evolving domains while preserving historical knowledge. DIL faces two critical challenges in the context of imbalanced data: intra-domain class imbalance and cross-domain class distribution shifts. These challenges significantly hinder model performance, as intra-domain imbalance leads to underfitting of few-shot classes, while cross-domain shifts require maintaining well-learned many-shot classes and transferring knowledge to improve few-shot class performance in old domains. To overcome these challenges, we introduce the Dual-Balance Collaborative Experts (DCE) framework. DCE employs a frequency-aware expert group, where each expert is guided by specialized loss functions to learn features for specific frequency groups, effectively addressing intra-domain class imbalance. Subsequently, a dynamic expert selector is learned by synthesizing pseudo-features through balanced Gaussian sampling from historical class statistics. This mechanism navigates the trade-off between preserving many-shot knowledge of previous domains and leveraging new data to improve few-shot class performance in earlier tasks. Extensive experimental results on four benchmark datasets demonstrate DCE's state-of-the-art performance.
Inaccuracy of an E-Dictionary and Its Influence on Chinese Language Users
Apr 01, 2025Electronic dictionaries have largely replaced paper dictionaries and become central tools for L2 learners seeking to expand their vocabulary. Users often assume these resources are reliable and rarely question the validity of the definitions provided. The accuracy of major E-dictionaries is seldom scrutinized, and little attention has been paid to how their corpora are constructed. Research on dictionary use, particularly the limitations of electronic dictionaries, remains scarce. This study adopts a combined method of experimentation, user survey, and dictionary critique to examine Youdao, one of the most widely used E-dictionaries in China. The experiment involved a translation task paired with retrospective reflection. Participants were asked to translate sentences containing words that are insufficiently or inaccurately defined in Youdao. Their consultation behavior was recorded to analyze how faulty definitions influenced comprehension. Results show that incomplete or misleading definitions can cause serious misunderstandings. Additionally, students exhibited problematic consultation habits. The study further explores how such flawed definitions originate, highlighting issues in data processing and the integration of AI and machine learning technologies in dictionary construction. The findings suggest a need for better training in dictionary literacy for users, as well as improvements in the underlying AI models used to build E-dictionaries.
AutoDCWorkflow: LLM-based Data Cleaning Workflow Auto-Generation and Benchmark
Dec 09, 2024



We investigate the reasoning capabilities of large language models (LLMs) for automatically generating data-cleaning workflows. To evaluate LLMs' ability to complete data-cleaning tasks, we implemented a pipeline for LLM-based Auto Data Cleaning Workflow (AutoDCWorkflow), prompting LLMs on data cleaning operations to repair three types of data quality issues: duplicates, missing values, and inconsistent data formats. Given a dirty table and a purpose (expressed as a query), this pipeline generates a minimal, clean table sufficient to address the purpose and the data cleaning workflow used to produce the table. The planning process involves three main LLM-driven components: (1) Select Target Columns: Identifies a set of target columns related to the purpose. (2) Inspect Column Quality: Assesses the data quality for each target column and generates a Data Quality Report as operation objectives. (3) Generate Operation & Arguments: Predicts the next operation and arguments based on the data quality report results. Additionally, we propose a data cleaning benchmark to evaluate the capability of LLM agents to automatically generate workflows that address data cleaning purposes of varying difficulty levels. The benchmark comprises the annotated datasets as a collection of purpose, raw table, clean table, data cleaning workflow, and answer set. In our experiments, we evaluated three LLMs that auto-generate purpose-driven data cleaning workflows. The results indicate that LLMs perform well in planning and generating data-cleaning workflows without the need for fine-tuning.
Visualizing, Rethinking, and Mining the Loss Landscape of Deep Neural Networks
May 21, 2024



The loss landscape of deep neural networks (DNNs) is commonly considered complex and wildly fluctuated. However, an interesting observation is that the loss surfaces plotted along Gaussian noise directions are almost v-basin ones with the perturbed model lying on the basin. This motivates us to rethink whether the 1D or 2D subspace could cover more complex local geometry structures, and how to mine the corresponding perturbation directions. This paper systematically and gradually categorizes the 1D curves from simple to complex, including v-basin, v-side, w-basin, w-peak, and vvv-basin curves. Notably, the latter two types are already hard to obtain via the intuitive construction of specific perturbation directions, and we need to propose proper mining algorithms to plot the corresponding 1D curves. Combining these 1D directions, various types of 2D surfaces are visualized such as the saddle surfaces and the bottom of a bottle of wine that are only shown by demo functions in previous works. Finally, we propose theoretical insights from the lens of the Hessian matrix to explain the observed several interesting phenomena.
Exploring and Exploiting the Asymmetric Valley of Deep Neural Networks
May 21, 2024
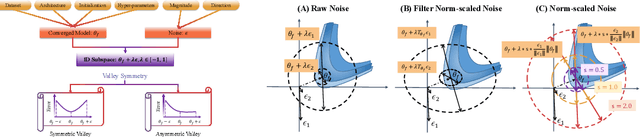
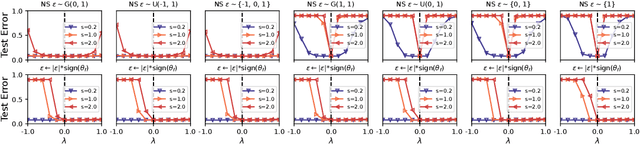
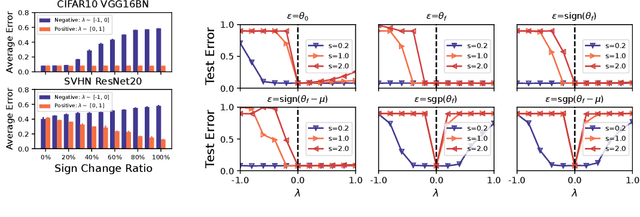
Exploring the loss landscape offers insights into the inherent principles of deep neural networks (DNNs). Recent work suggests an additional asymmetry of the valley beyond the flat and sharp ones, yet without thoroughly examining its causes or implications. Our study methodically explores the factors affecting the symmetry of DNN valleys, encompassing (1) the dataset, network architecture, initialization, and hyperparameters that influence the convergence point; and (2) the magnitude and direction of the noise for 1D visualization. Our major observation shows that the {\it degree of sign consistency} between the noise and the convergence point is a critical indicator of valley symmetry. Theoretical insights from the aspects of ReLU activation and softmax function could explain the interesting phenomenon. Our discovery propels novel understanding and applications in the scenario of Model Fusion: (1) the efficacy of interpolating separate models significantly correlates with their sign consistency ratio, and (2) imposing sign alignment during federated learning emerges as an innovative approach for model parameter alignment.
Unlocking Insights: Semantic Search in Jupyter Notebooks
Feb 20, 2024



Semantic search, a process aimed at delivering highly relevant search results by comprehending the searcher's intent and the contextual meaning of terms within a searchable dataspace, plays a pivotal role in information retrieval. In this paper, we investigate the application of large language models to enhance semantic search capabilities, specifically tailored for the domain of Jupyter Notebooks. Our objective is to retrieve generated outputs, such as figures or tables, associated functions and methods, and other pertinent information. We demonstrate a semantic search framework that achieves a comprehensive semantic understanding of the entire notebook's contents, enabling it to effectively handle various types of user queries. Key components of this framework include: 1). A data preprocessor is designed to handle diverse types of cells within Jupyter Notebooks, encompassing both markdown and code cells. 2). An innovative methodology is devised to address token size limitations that arise with code-type cells. We implement a finer-grained approach to data input, transitioning from the cell level to the function level, effectively resolving these issues.
An objective comparison of methods for augmented reality in laparoscopic liver resection by preoperative-to-intraoperative image fusion
Feb 07, 2024



Augmented reality for laparoscopic liver resection is a visualisation mode that allows a surgeon to localise tumours and vessels embedded within the liver by projecting them on top of a laparoscopic image. Preoperative 3D models extracted from CT or MRI data are registered to the intraoperative laparoscopic images during this process. In terms of 3D-2D fusion, most of the algorithms make use of anatomical landmarks to guide registration. These landmarks include the liver's inferior ridge, the falciform ligament, and the occluding contours. They are usually marked by hand in both the laparoscopic image and the 3D model, which is time-consuming and may contain errors if done by a non-experienced user. Therefore, there is a need to automate this process so that augmented reality can be used effectively in the operating room. We present the Preoperative-to-Intraoperative Laparoscopic Fusion Challenge (P2ILF), held during the Medical Imaging and Computer Assisted Interventions (MICCAI 2022) conference, which investigates the possibilities of detecting these landmarks automatically and using them in registration. The challenge was divided into two tasks: 1) A 2D and 3D landmark detection task and 2) a 3D-2D registration task. The teams were provided with training data consisting of 167 laparoscopic images and 9 preoperative 3D models from 9 patients, with the corresponding 2D and 3D landmark annotations. A total of 6 teams from 4 countries participated, whose proposed methods were evaluated on 16 images and two preoperative 3D models from two patients. All the teams proposed deep learning-based methods for the 2D and 3D landmark segmentation tasks and differentiable rendering-based methods for the registration task. Based on the experimental outcomes, we propose three key hypotheses that determine current limitations and future directions for research in this domain.