 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeight Scope Alignment: A Frustratingly Easy Method for Model Merging
Aug 22, 2024



Merging models becomes a fundamental procedure in some applications that consider model efficiency and robustness. The training randomness or Non-I.I.D. data poses a huge challenge for averaging-based model fusion. Previous research efforts focus on element-wise regularization or neural permutations to enhance model averaging while overlooking weight scope variations among models, which can significantly affect merging effectiveness. In this paper, we reveal variations in weight scope under different training conditions, shedding light on its influence on model merging. Fortunately, the parameters in each layer basically follow the Gaussian distribution, which inspires a novel and simple regularization approach named Weight Scope Alignment (WSA). It contains two key components: 1) leveraging a target weight scope to guide the model training process for ensuring weight scope matching in the subsequent model merging. 2) fusing the weight scope of two or more models into a unified one for multi-stage model fusion. We extend the WSA regularization to two different scenarios, including Mode Connectivity and Federated Learning. Abundant experimental studies validate the effectiveness of our approach.
Exploring and Exploiting the Asymmetric Valley of Deep Neural Networks
May 21, 2024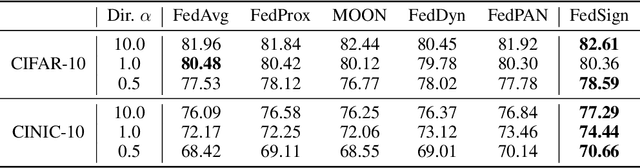
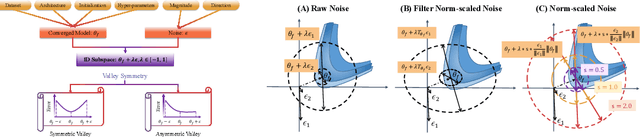
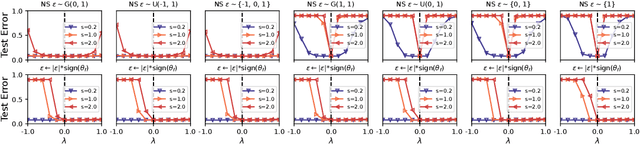
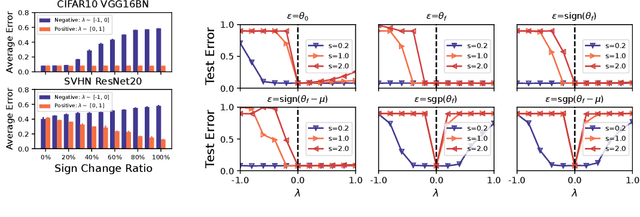
Exploring the loss landscape offers insights into the inherent principles of deep neural networks (DNNs). Recent work suggests an additional asymmetry of the valley beyond the flat and sharp ones, yet without thoroughly examining its causes or implications. Our study methodically explores the factors affecting the symmetry of DNN valleys, encompassing (1) the dataset, network architecture, initialization, and hyperparameters that influence the convergence point; and (2) the magnitude and direction of the noise for 1D visualization. Our major observation shows that the {\it degree of sign consistency} between the noise and the convergence point is a critical indicator of valley symmetry. Theoretical insights from the aspects of ReLU activation and softmax function could explain the interesting phenomenon. Our discovery propels novel understanding and applications in the scenario of Model Fusion: (1) the efficacy of interpolating separate models significantly correlates with their sign consistency ratio, and (2) imposing sign alignment during federated learning emerges as an innovative approach for model parameter alignment.
Visualizing, Rethinking, and Mining the Loss Landscape of Deep Neural Networks
May 21, 2024



The loss landscape of deep neural networks (DNNs) is commonly considered complex and wildly fluctuated. However, an interesting observation is that the loss surfaces plotted along Gaussian noise directions are almost v-basin ones with the perturbed model lying on the basin. This motivates us to rethink whether the 1D or 2D subspace could cover more complex local geometry structures, and how to mine the corresponding perturbation directions. This paper systematically and gradually categorizes the 1D curves from simple to complex, including v-basin, v-side, w-basin, w-peak, and vvv-basin curves. Notably, the latter two types are already hard to obtain via the intuitive construction of specific perturbation directions, and we need to propose proper mining algorithms to plot the corresponding 1D curves. Combining these 1D directions, various types of 2D surfaces are visualized such as the saddle surfaces and the bottom of a bottle of wine that are only shown by demo functions in previous works. Finally, we propose theoretical insights from the lens of the Hessian matrix to explain the observed several interesting phenomena.
Exploring Dark Knowledge under Various Teacher Capacities and Addressing Capacity Mismatch
May 21, 2024Knowledge Distillation (KD) could transfer the ``dark knowledge" of a well-performed yet large neural network to a weaker but lightweight one. From the view of output logits and softened probabilities, this paper goes deeper into the dark knowledge provided by teachers with different capacities. Two fundamental observations are: (1) a larger teacher tends to produce probability vectors that are less distinct between non-ground-truth classes; (2) teachers with different capacities are basically consistent in their cognition of relative class affinity. Abundant experimental studies verify these observations and in-depth empirical explanations are provided. The difference in dark knowledge leads to the peculiar phenomenon named ``capacity mismatch" that a more accurate teacher does not necessarily perform as well as a smaller teacher when teaching the same student network. Enlarging the distinctness between non-ground-truth class probabilities for larger teachers could address the capacity mismatch problem. This paper explores multiple simple yet effective ways to achieve this goal and verify their success by comparing them with popular KD methods that solve the capacity mismatch.
MAP: Model Aggregation and Personalization in Federated Learning with Incomplete Classes
Apr 14, 2024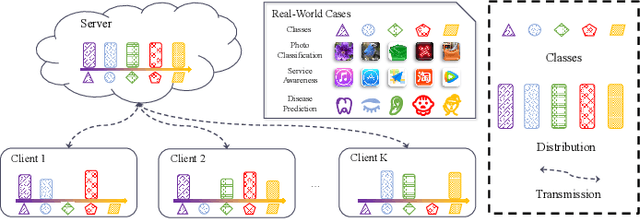
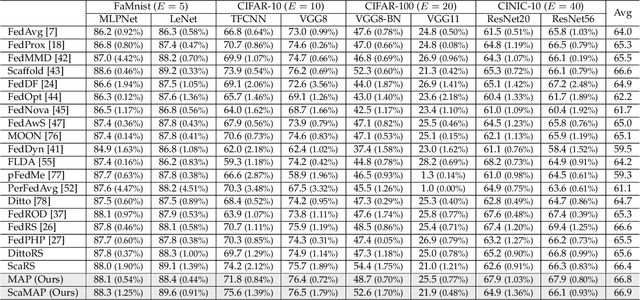
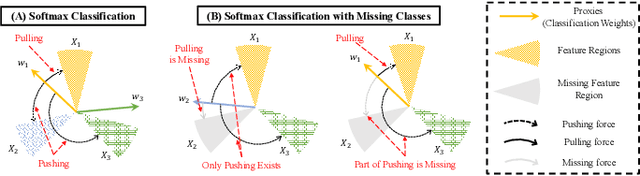
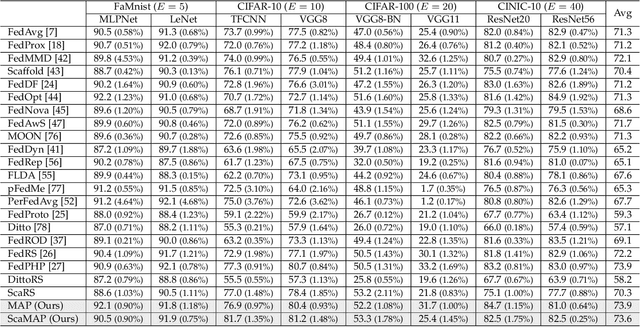
In some real-world applications, data samples are usually distributed on local devices, where federated learning (FL) techniques are proposed to coordinate decentralized clients without directly sharing users' private data. FL commonly follows the parameter server architecture and contains multiple personalization and aggregation procedures. The natural data heterogeneity across clients, i.e., Non-I.I.D. data, challenges both the aggregation and personalization goals in FL. In this paper, we focus on a special kind of Non-I.I.D. scene where clients own incomplete classes, i.e., each client can only access a partial set of the whole class set. The server aims to aggregate a complete classification model that could generalize to all classes, while the clients are inclined to improve the performance of distinguishing their observed classes. For better model aggregation, we point out that the standard softmax will encounter several problems caused by missing classes and propose "restricted softmax" as an alternative. For better model personalization, we point out that the hard-won personalized models are not well exploited and propose "inherited private model" to store the personalization experience. Our proposed algorithm named MAP could simultaneously achieve the aggregation and personalization goals in FL. Abundant experimental studies verify the superiorities of our algorithm.
CLAF: Contrastive Learning with Augmented Features for Imbalanced Semi-Supervised Learning
Dec 24, 2023



Due to the advantages of leveraging unlabeled data and learning meaningful representations, semi-supervised learning and contrastive learning have been progressively combined to achieve better performances in popular applications with few labeled data and abundant unlabeled data. One common manner is assigning pseudo-labels to unlabeled samples and selecting positive and negative samples from pseudo-labeled samples to apply contrastive learning. However, the real-world data may be imbalanced, causing pseudo-labels to be biased toward the majority classes and further undermining the effectiveness of contrastive learning. To address the challenge, we propose Contrastive Learning with Augmented Features (CLAF). We design a class-dependent feature augmentation module to alleviate the scarcity of minority class samples in contrastive learning. For each pseudo-labeled sample, we select positive and negative samples from labeled data instead of unlabeled data to compute contrastive loss. Comprehensive experiments on imbalanced image classification datasets demonstrate the effectiveness of CLAF in the context of imbalanced semi-supervised learning.
MrTF: Model Refinery for Transductive Federated Learning
May 07, 2023We consider a real-world scenario in which a newly-established pilot project needs to make inferences for newly-collected data with the help of other parties under privacy protection policies. Current federated learning (FL) paradigms are devoted to solving the data heterogeneity problem without considering the to-be-inferred data. We propose a novel learning paradigm named transductive federated learning (TFL) to simultaneously consider the structural information of the to-be-inferred data. On the one hand, the server could use the pre-available test samples to refine the aggregated models for robust model fusion, which tackles the data heterogeneity problem in FL. On the other hand, the refinery process incorporates test samples into training and could generate better predictions in a transductive manner. We propose several techniques including stabilized teachers, rectified distillation, and clustered label refinery to facilitate the model refinery process. Abundant experimental studies verify the superiorities of the proposed \underline{M}odel \underline{r}efinery framework for \underline{T}ransductive \underline{F}ederated learning (MrTF). The source code is available at \url{https://github.com/lxcnju/MrTF}.
Asymmetric Temperature Scaling Makes Larger Networks Teach Well Again
Oct 11, 2022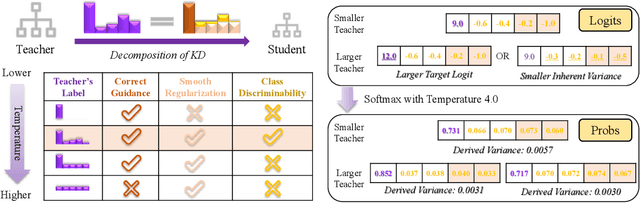

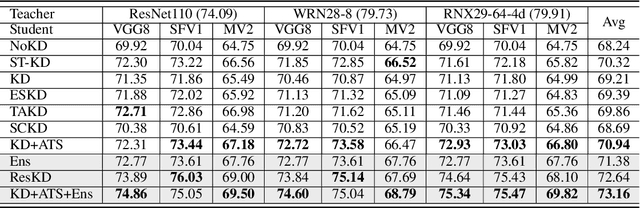

Knowledge Distillation (KD) aims at transferring the knowledge of a well-performed neural network (the {\it teacher}) to a weaker one (the {\it student}). A peculiar phenomenon is that a more accurate model doesn't necessarily teach better, and temperature adjustment can neither alleviate the mismatched capacity. To explain this, we decompose the efficacy of KD into three parts: {\it correct guidance}, {\it smooth regularization}, and {\it class discriminability}. The last term describes the distinctness of {\it wrong class probabilities} that the teacher provides in KD. Complex teachers tend to be over-confident and traditional temperature scaling limits the efficacy of {\it class discriminability}, resulting in less discriminative wrong class probabilities. Therefore, we propose {\it Asymmetric Temperature Scaling (ATS)}, which separately applies a higher/lower temperature to the correct/wrong class. ATS enlarges the variance of wrong class probabilities in the teacher's label and makes the students grasp the absolute affinities of wrong classes to the target class as discriminative as possible. Both theoretical analysis and extensive experimental results demonstrate the effectiveness of ATS. The demo developed in Mindspore is available at \url{https://gitee.com/lxcnju/ats-mindspore} and will be available at \url{https://gitee.com/mindspore/models/tree/master/research/cv/ats}.
Avoid Overfitting User Specific Information in Federated Keyword Spotting
Jun 17, 2022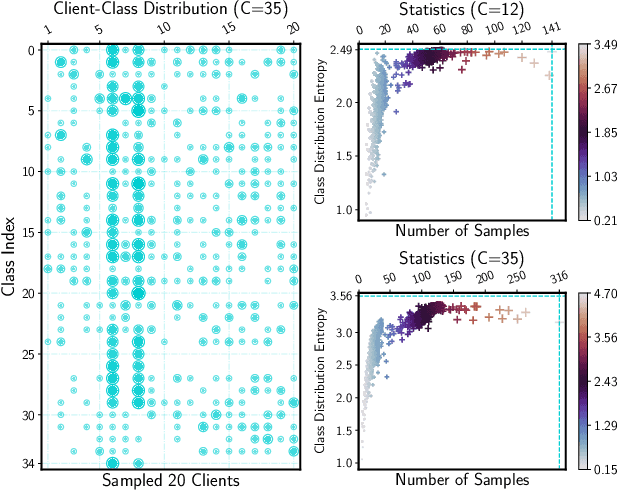
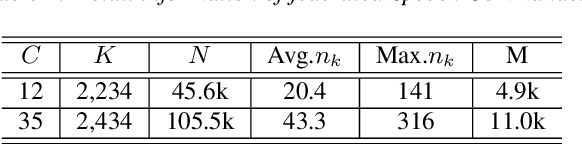
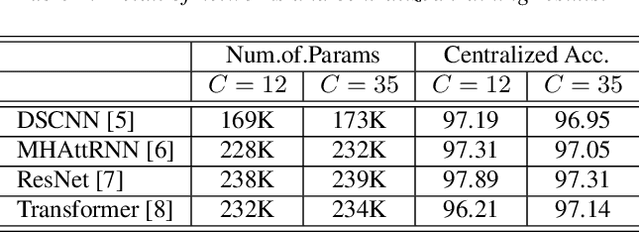
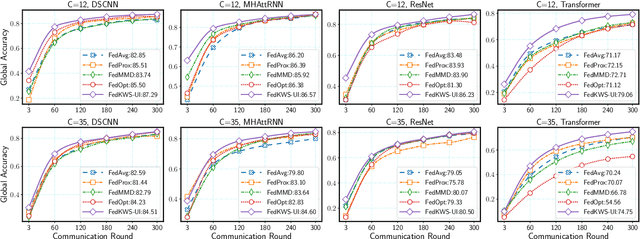
Keyword spotting (KWS) aims to discriminate a specific wake-up word from other signals precisely and efficiently for different users. Recent works utilize various deep networks to train KWS models with all users' speech data centralized without considering data privacy. Federated KWS (FedKWS) could serve as a solution without directly sharing users' data. However, the small amount of data, different user habits, and various accents could lead to fatal problems, e.g., overfitting or weight divergence. Hence, we propose several strategies to encourage the model not to overfit user-specific information in FedKWS. Specifically, we first propose an adversarial learning strategy, which updates the downloaded global model against an overfitted local model and explicitly encourages the global model to capture user-invariant information. Furthermore, we propose an adaptive local training strategy, letting clients with more training data and more uniform class distributions undertake more local update steps. Equivalently, this strategy could weaken the negative impacts of those users whose data is less qualified. Our proposed FedKWS-UI could explicitly and implicitly learn user-invariant information in FedKWS. Abundant experimental results on federated Google Speech Commands verify the effectiveness of FedKWS-UI.
Federated Learning with Position-Aware Neurons
Apr 02, 2022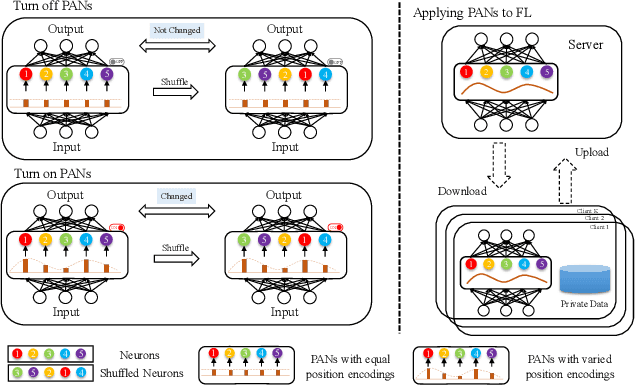

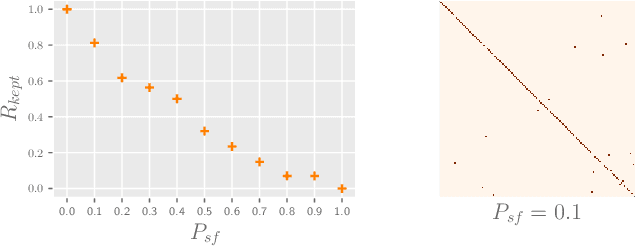
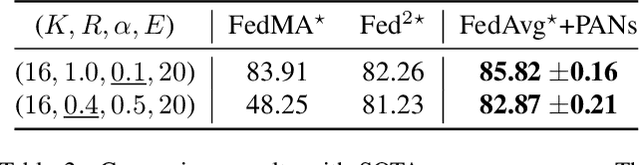
Federated Learning (FL) fuses collaborative models from local nodes without centralizing users' data. The permutation invariance property of neural networks and the non-i.i.d. data across clients make the locally updated parameters imprecisely aligned, disabling the coordinate-based parameter averaging. Traditional neurons do not explicitly consider position information. Hence, we propose Position-Aware Neurons (PANs) as an alternative, fusing position-related values (i.e., position encodings) into neuron outputs. PANs couple themselves to their positions and minimize the possibility of dislocation, even updating on heterogeneous data. We turn on/off PANs to disable/enable the permutation invariance property of neural networks. PANs are tightly coupled with positions when applied to FL, making parameters across clients pre-aligned and facilitating coordinate-based parameter averaging. PANs are algorithm-agnostic and could universally improve existing FL algorithms. Furthermore, "FL with PANs" is simple to implement and computationally friendly.