 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsymmetric Temperature Scaling Makes Larger Networks Teach Well Again
Paper and Code
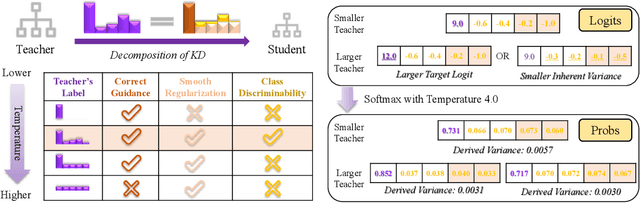

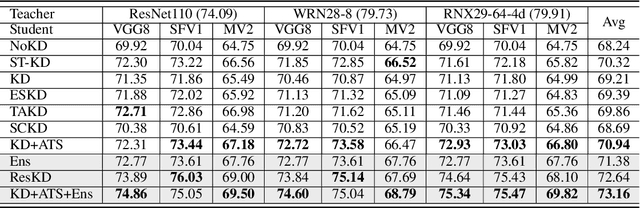

Knowledge Distillation (KD) aims at transferring the knowledge of a well-performed neural network (the {\it teacher}) to a weaker one (the {\it student}). A peculiar phenomenon is that a more accurate model doesn't necessarily teach better, and temperature adjustment can neither alleviate the mismatched capacity. To explain this, we decompose the efficacy of KD into three parts: {\it correct guidance}, {\it smooth regularization}, and {\it class discriminability}. The last term describes the distinctness of {\it wrong class probabilities} that the teacher provides in KD. Complex teachers tend to be over-confident and traditional temperature scaling limits the efficacy of {\it class discriminability}, resulting in less discriminative wrong class probabilities. Therefore, we propose {\it Asymmetric Temperature Scaling (ATS)}, which separately applies a higher/lower temperature to the correct/wrong class. ATS enlarges the variance of wrong class probabilities in the teacher's label and makes the students grasp the absolute affinities of wrong classes to the target class as discriminative as possible. Both theoretical analysis and extensive experimental results demonstrate the effectiveness of ATS. The demo developed in Mindspore is available at \url{https://gitee.com/lxcnju/ats-mindspore} and will be available at \url{https://gitee.com/mindspore/models/tree/master/research/cv/ats}.