 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAffordanceVLA: A Vision-Language-Action Model Empowering Action Generation through Affordance-Aware Understanding
Jun 04, 2026Vision-Language-Action (VLA) models leverage the rich world knowledge of pretrained vision-language models (VLMs) to enable instruction-following robotic manipulation. However, the structural mismatch between VLM semantic spaces and embodied control policies often hinders the learning of precise perception--action mappings. To address this challenge, we propose \textbf{AffordanceVLA}, a unified framework that introduces structured affordance forecasting as a task-oriented intermediate representation to establish a more precise and robust perception--action mapping. Specifically, we progressively model manipulation priors through three complementary components: 1) \textbf{Which2Act} for object-centric grounding via visual latent prediction to suppress distractions; 2) \textbf{Where2Act} for 2D interaction localization via affordance map estimation; and 3) \textbf{How2Act} for 3D geometric reasoning to guide manipulation policies. These affordance cues provide spatially grounded, semantically conditioned, and action-coupled intermediate representations, thereby naturally bridging vision, language and action. We integrate these modules into a Mixture-of-Transformer (MoT) architecture with specialized experts and train the model using a three-stage training strategy with a progressive data curriculum. To overcome the scarcity of dense affordance labels in robotic datasets, we also develop a robust automated data augmentation pipeline. Extensive experiments on simulation and real-world demonstrate that AffordanceVLA achieves strong performance across diverse manipulation scenarios.
RoboStressBench: Benchmarking VLM Robustness to Physical Visual Stress in Embodied Scenes
May 30, 2026Vision-Language Models (VLMs) have shown strong visual understanding and are increasingly deployed in embodied AI systems, where reliable perception under real conditions is essential. However, existing benchmarks assess VLMs using clean images or isolated perturbations rather than stresses caused by physical scene formation. This design has two limitations: it covers only a narrow subset of everyday visual stresses, and some perturbations rarely appear in realistic embodied scenes. This gap raises a fundamental question: how can we define visual stress in a principled way that captures the diverse factors encountered in physical environments? To address this question, we formulate visual perception from an inverse graphics perspective and introduce RoboStressBench, a benchmark for evaluating VLM robustness to physical visual stress in embodied scenes. Inspired by the physical rendering equation, RoboStressBench decomposes visual stress into four physically grounded dimensions: Material (M), Viewpoint (V), Lighting (L), and Geometry (G). This design enables RoboStressBench to cover a broad range of visual stresses in real-world environments, while allowing controlled analysis of their effects on VLM capabilities such as visual recognition, reasoning, and planning. Through comprehensive evaluations of state-of-the-art VLMs, we identify stress-specific failure modes and reveal that different physical factors degrade different embodied capabilities, which are often obscured by aggregate accuracy. We further introduce a stress-aware agentic solver that detects visual stressors and invokes visual-editing skills before reasoning, improving robustness in high-stress scenarios. Overall, RoboStressBench provides a principled evaluation framework for diagnosing and improving VLM perception under real-world physical stress, supporting the development of more reliable embodied AI systems.
The Right Inference Strategy Is All You Need: Nearly Training-Free Domain-Wise Inference for EgoCross Challenge
May 30, 2026EgoCross evaluates multimodal large language models on egocentric video question answering under substantial domain shift, where test videos come from surgery, industrial assembly, extreme sports, and animal-mounted cameras rather than ordinary daily-life scenes. In the source-limited track, the base model is fixed to Qwen3-VL-4B, while the official task-specific support set contains only 20 training samples. This setting makes the challenge less about model scaling and more about exposing the right visual, temporal, and answer-selection cues to a constrained model. Our key observation is that the frozen baseline model is not simply incapable of these rare scenarios; rather, it often fails to transfer its existing visual-language knowledge to the new task format without an appropriate interface. We therefore use a domain-wise inference strategy that treats the four target domains separately and designs different input, prompting, and answer-mapping procedures according to each domain's task characteristics. These strategies make the rare egocentric scenes more interpretable to the VLM by emphasizing the cues that matter for each domain. The resulting system is nearly training-free: surgery, and animal questions are answered with the base Qwen3-VL-4B model, while XSports and industry use only the official SFT checkpoint trained for two epochs on the provided 20 training samples. On the final evaluation, this simple strategy reaches 66.98\% overall accuracy, suggesting that careful domain-aware inference can compensate for limited base-model strength and recover much of the ability already present in the baseline model.
Panoramic Affordance Prediction
Mar 16, 2026Affordance prediction serves as a critical bridge between perception and action in embodied AI. However, existing research is confined to pinhole camera models, which suffer from narrow Fields of View (FoV) and fragmented observations, often missing critical holistic environmental context. In this paper, we present the first exploration into Panoramic Affordance Prediction, utilizing 360-degree imagery to capture global spatial relationships and holistic scene understanding. To facilitate this novel task, we first introduce PAP-12K, a large-scale benchmark dataset containing over 1,000 ultra-high-resolution (12k, 11904 x 5952) panoramic images with over 12k carefully annotated QA pairs and affordance masks. Furthermore, we propose PAP, a training-free, coarse-to-fine pipeline inspired by the human foveal visual system to tackle the ultra-high resolution and severe distortion inherent in panoramic images. PAP employs recursive visual routing via grid prompting to progressively locate targets, applies an adaptive gaze mechanism to rectify local geometric distortions, and utilizes a cascaded grounding pipeline to extract precise instance-level masks. Experimental results on PAP-12K reveal that existing affordance prediction methods designed for standard perspective images suffer severe performance degradation and fail due to the unique challenges of panoramic vision. In contrast, PAP framework effectively overcomes these obstacles, significantly outperforming state-of-the-art baselines and highlighting the immense potential of panoramic perception for robust embodied intelligence.
DVD: Deterministic Video Depth Estimation with Generative Priors
Mar 12, 2026Existing video depth estimation faces a fundamental trade-off: generative models suffer from stochastic geometric hallucinations and scale drift, while discriminative models demand massive labeled datasets to resolve semantic ambiguities. To break this impasse, we present DVD, the first framework to deterministically adapt pre-trained video diffusion models into single-pass depth regressors. Specifically, DVD features three core designs: (i) repurposing the diffusion timestep as a structural anchor to balance global stability with high-frequency details; (ii) latent manifold rectification (LMR) to mitigate regression-induced over-smoothing, enforcing differential constraints to restore sharp boundaries and coherent motion; and (iii) global affine coherence, an inherent property bounding inter-window divergence, which enables seamless long-video inference without requiring complex temporal alignment. Extensive experiments demonstrate that DVD achieves state-of-the-art zero-shot performance across benchmarks. Furthermore, DVD successfully unlocks the profound geometric priors implicit in video foundation models using 163x less task-specific data than leading baselines. Notably, we fully release our pipeline, providing the whole training suite for SOTA video depth estimation to benefit the open-source community.
ActionCodec: What Makes for Good Action Tokenizers
Feb 17, 2026Vision-Language-Action (VLA) models leveraging the native autoregressive paradigm of Vision-Language Models (VLMs) have demonstrated superior instruction-following and training efficiency. Central to this paradigm is action tokenization, yet its design has primarily focused on reconstruction fidelity, failing to address its direct impact on VLA optimization. Consequently, the fundamental question of \textit{what makes for good action tokenizers} remains unanswered. In this paper, we bridge this gap by establishing design principles specifically from the perspective of VLA optimization. We identify a set of best practices based on information-theoretic insights, including maximized temporal token overlap, minimized vocabulary redundancy, enhanced multimodal mutual information, and token independence. Guided by these principles, we introduce \textbf{ActionCodec}, a high-performance action tokenizer that significantly enhances both training efficiency and VLA performance across diverse simulation and real-world benchmarks. Notably, on LIBERO, a SmolVLM2-2.2B fine-tuned with ActionCodec achieves a 95.5\% success rate without any robotics pre-training. With advanced architectural enhancements, this reaches 97.4\%, representing a new SOTA for VLA models without robotics pre-training. We believe our established design principles, alongside the released model, will provide a clear roadmap for the community to develop more effective action tokenizers.
PhysToolBench: Benchmarking Physical Tool Understanding for MLLMs
Oct 10, 2025The ability to use, understand, and create tools is a hallmark of human intelligence, enabling sophisticated interaction with the physical world. For any general-purpose intelligent agent to achieve true versatility, it must also master these fundamental skills. While modern Multimodal Large Language Models (MLLMs) leverage their extensive common knowledge for high-level planning in embodied AI and in downstream Vision-Language-Action (VLA) models, the extent of their true understanding of physical tools remains unquantified. To bridge this gap, we present PhysToolBench, the first benchmark dedicated to evaluating the comprehension of physical tools by MLLMs. Our benchmark is structured as a Visual Question Answering (VQA) dataset comprising over 1,000 image-text pairs. It assesses capabilities across three distinct difficulty levels: (1) Tool Recognition: Requiring the recognition of a tool's primary function. (2) Tool Understanding: Testing the ability to grasp the underlying principles of a tool's operation. (3) Tool Creation: Challenging the model to fashion a new tool from surrounding objects when conventional options are unavailable. Our comprehensive evaluation of 32 MLLMs-spanning proprietary, open-source, specialized embodied, and backbones in VLAs-reveals a significant deficiency in tool understanding. Furthermore, we provide an in-depth analysis and propose preliminary solutions. Code and dataset are publicly available.
Mirage-1: Augmenting and Updating GUI Agent with Hierarchical Multimodal Skills
Jun 12, 2025



Recent efforts to leverage the Multi-modal Large Language Model (MLLM) as GUI agents have yielded promising outcomes. However, these agents still struggle with long-horizon tasks in online environments, primarily due to insufficient knowledge and the inherent gap between offline and online domains. In this paper, inspired by how humans generalize knowledge in open-ended environments, we propose a Hierarchical Multimodal Skills (HMS) module to tackle the issue of insufficient knowledge. It progressively abstracts trajectories into execution skills, core skills, and ultimately meta-skills, providing a hierarchical knowledge structure for long-horizon task planning. To bridge the domain gap, we propose the Skill-Augmented Monte Carlo Tree Search (SA-MCTS) algorithm, which efficiently leverages skills acquired in offline environments to reduce the action search space during online tree exploration. Building on HMS, we propose Mirage-1, a multimodal, cross-platform, plug-and-play GUI agent. To validate the performance of Mirage-1 in real-world long-horizon scenarios, we constructed a new benchmark, AndroidLH. Experimental results show that Mirage-1 outperforms previous agents by 32\%, 19\%, 15\%, and 79\% on AndroidWorld, MobileMiniWob++, Mind2Web-Live, and AndroidLH, respectively. Project page: https://cybertronagent.github.io/Mirage-1.github.io/
STAR: Learning Diverse Robot Skill Abstractions through Rotation-Augmented Vector Quantization
Jun 04, 2025



Transforming complex actions into discrete skill abstractions has demonstrated strong potential for robotic manipulation. Existing approaches mainly leverage latent variable models, e.g., VQ-VAE, to learn skill abstractions through learned vectors (codebooks), while they suffer from codebook collapse and modeling the causal relationship between learned skills. To address these limitations, we present \textbf{S}kill \textbf{T}raining with \textbf{A}ugmented \textbf{R}otation (\textbf{STAR}), a framework that advances both skill learning and composition to complete complex behaviors. Specifically, to prevent codebook collapse, we devise rotation-augmented residual skill quantization (RaRSQ). It encodes relative angles between encoder outputs into the gradient flow by rotation-based gradient mechanism. Points within the same skill code are forced to be either pushed apart or pulled closer together depending on gradient directions. Further, to capture the causal relationship between skills, we present causal skill transformer (CST) which explicitly models dependencies between skill representations through an autoregressive mechanism for coherent action generation. Extensive experiments demonstrate the superiority of STAR on both LIBERO benchmark and realworld tasks, with around 12\% improvement over the baselines.
* Accepted by ICML 2025 Spotlight
Proximalized Preference Optimization for Diverse Feedback Types: A Decomposed Perspective on DPO
May 29, 2025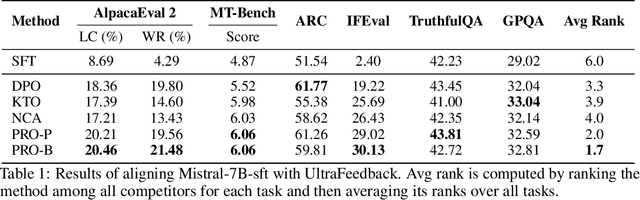


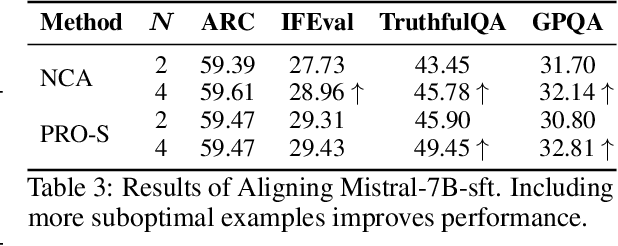
Direct alignment methods typically optimize large language models (LLMs) by contrasting the likelihoods of preferred versus dispreferred responses. While effective in steering LLMs to match relative preference, these methods are frequently noted for decreasing the absolute likelihoods of example responses. As a result, aligned models tend to generate outputs that deviate from the expected patterns, exhibiting reward-hacking effect even without a reward model. This undesired consequence exposes a fundamental limitation in contrastive alignment, which we characterize as likelihood underdetermination. In this work, we revisit direct preference optimization (DPO) -- the seminal direct alignment method -- and demonstrate that its loss theoretically admits a decomposed reformulation. The reformulated loss not only broadens applicability to a wider range of feedback types, but also provides novel insights into the underlying cause of likelihood underdetermination. Specifically, the standard DPO implementation implicitly oversimplifies a regularizer in the reformulated loss, and reinstating its complete version effectively resolves the underdetermination issue. Leveraging these findings, we introduce PRoximalized PReference Optimization (PRO), a unified method to align with diverse feeback types, eliminating likelihood underdetermination through an efficient approximation of the complete regularizer. Comprehensive experiments show the superiority of PRO over existing methods in scenarios involving pairwise, binary and scalar feedback.