 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlug-and-play Class-aware Knowledge Injection for Prompt Learning with Visual-Language Model
May 07, 2026Prompt learning has become an effective and widely used technique in enhancing vision-language models (VLMs) such as CLIP for various downstream tasks, particularly in zero-shot classification within specific domains. Existing methods typically focus on either learning class-shared prompts for a given domain or generating instance-specific prompts through conditional prompt learning. While these methods have achieved promising performance, they often overlook class-specific knowledge in prompt design, leading to suboptimal outcomes. The underlying reasons are: 1) class-specific prompts offer more fine-grained supervision compared to coarse class-shared prompts, which helps prevent misclassification of data from different classes into a single class; 2) compared to class-specific prompts, instance-specific prompts neglect the richer class-level information across multiple instances, potentially causing data from the same class to be divided into multiple classes. To effectively supplement the class-specific knowledge into existing methods, we propose a plug-and-play Class-Aware Knowledge Injection (CAKI) framework. CAKI comprises two key components, i.e., class-specific prompt generation and query-key prompt matching. The former encodes class-specific knowledge into prompts from few-shot samples that belong to the same class and stores the learned prompts in a class-level knowledge bank. The latter provides a plug-and-play mechanism for each test instance to retrieve relevant class-level knowledge from the knowledge bank and inject such knowledge to refine model predictions. Extensive experiments demonstrate that our CAKI effectively improves the performance of existing methods on base and novel classes. Code is publicly available at \href{https://github.com/yjh576/CAKI}{this https URL}.
ReMeREC: Relation-aware and Multi-entity Referring Expression Comprehension
Jul 22, 2025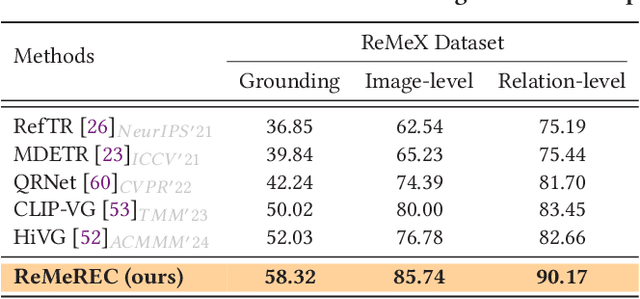

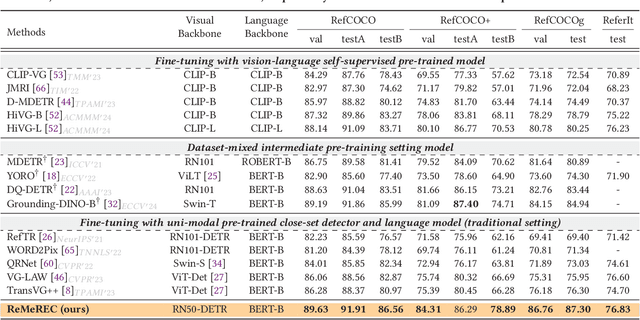
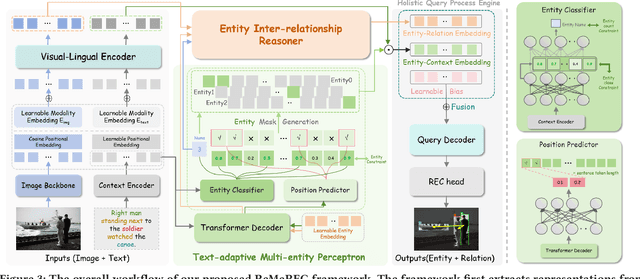
Referring Expression Comprehension (REC) aims to localize specified entities or regions in an image based on natural language descriptions. While existing methods handle single-entity localization, they often ignore complex inter-entity relationships in multi-entity scenes, limiting their accuracy and reliability. Additionally, the lack of high-quality datasets with fine-grained, paired image-text-relation annotations hinders further progress. To address this challenge, we first construct a relation-aware, multi-entity REC dataset called ReMeX, which includes detailed relationship and textual annotations. We then propose ReMeREC, a novel framework that jointly leverages visual and textual cues to localize multiple entities while modeling their inter-relations. To address the semantic ambiguity caused by implicit entity boundaries in language, we introduce the Text-adaptive Multi-entity Perceptron (TMP), which dynamically infers both the quantity and span of entities from fine-grained textual cues, producing distinctive representations. Additionally, our Entity Inter-relationship Reasoner (EIR) enhances relational reasoning and global scene understanding. To further improve language comprehension for fine-grained prompts, we also construct a small-scale auxiliary dataset, EntityText, generated using large language models. Experiments on four benchmark datasets show that ReMeREC achieves state-of-the-art performance in multi-entity grounding and relation prediction, outperforming existing approaches by a large margin.
DeCo: Task Decomposition and Skill Composition for Zero-Shot Generalization in Long-Horizon 3D Manipulation
May 01, 2025Generalizing language-conditioned multi-task imitation learning (IL) models to novel long-horizon 3D manipulation tasks remains a significant challenge. To address this, we propose DeCo (Task Decomposition and Skill Composition), a model-agnostic framework compatible with various multi-task IL models, designed to enhance their zero-shot generalization to novel, compositional, long-horizon 3D manipulation tasks. DeCo first decomposes IL demonstrations into a set of modular atomic tasks based on the physical interaction between the gripper and objects, and constructs an atomic training dataset that enables models to learn a diverse set of reusable atomic skills during imitation learning. At inference time, DeCo leverages a vision-language model (VLM) to parse high-level instructions for novel long-horizon tasks, retrieve the relevant atomic skills, and dynamically schedule their execution; a spatially-aware skill-chaining module then ensures smooth, collision-free transitions between sequential skills. We evaluate DeCo in simulation using DeCoBench, a benchmark specifically designed to assess zero-shot generalization of multi-task IL models in compositional long-horizon 3D manipulation. Across three representative multi-task IL models (RVT-2, 3DDA, and ARP), DeCo achieves success rate improvements of 66.67%, 21.53%, and 57.92%, respectively, on 12 novel compositional tasks. Moreover, in real-world experiments, a DeCo-enhanced model trained on only 6 atomic tasks successfully completes 9 novel long-horizon tasks, yielding an average success rate improvement of 53.33% over the base multi-task IL model. Video demonstrations are available at: https://deco226.github.io.
GravMAD: Grounded Spatial Value Maps Guided Action Diffusion for Generalized 3D Manipulation
Sep 30, 2024Robots' ability to follow language instructions and execute diverse 3D tasks is vital in robot learning. Traditional imitation learning-based methods perform well on seen tasks but struggle with novel, unseen ones due to variability. Recent approaches leverage large foundation models to assist in understanding novel tasks, thereby mitigating this issue. However, these methods lack a task-specific learning process, which is essential for an accurate understanding of 3D environments, often leading to execution failures. In this paper, we introduce GravMAD, a sub-goal-driven, language-conditioned action diffusion framework that combines the strengths of imitation learning and foundation models. Our approach breaks tasks into sub-goals based on language instructions, allowing auxiliary guidance during both training and inference. During training, we introduce Sub-goal Keypose Discovery to identify key sub-goals from demonstrations. Inference differs from training, as there are no demonstrations available, so we use pre-trained foundation models to bridge the gap and identify sub-goals for the current task. In both phases, GravMaps are generated from sub-goals, providing flexible 3D spatial guidance compared to fixed 3D positions. Empirical evaluations on RLBench show that GravMAD significantly outperforms state-of-the-art methods, with a 28.63% improvement on novel tasks and a 13.36% gain on tasks encountered during training. These results demonstrate GravMAD's strong multi-task learning and generalization in 3D manipulation. Video demonstrations are available at: https://gravmad.github.io.
In-context Prompt Learning for Test-time Vision Recognition with Frozen Vision-language Model
Mar 10, 2024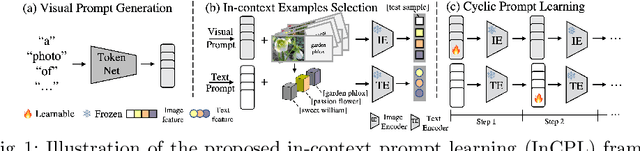

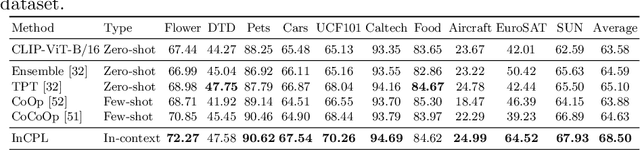
Existing pre-trained vision-language models, e.g., CLIP, have demonstrated impressive zero-shot generalization capabilities in various downstream tasks. However, the performance of these models will degrade significantly when test inputs present different distributions. To this end, we explore the concept of test-time prompt tuning (TTPT), which enables the adaptation of the CLIP model to novel downstream tasks through only one step of optimization on an unsupervised objective that involves the test sample. Motivated by in-context learning within field of natural language processing (NLP), we propose In-Context Prompt Learning (InCPL) for test-time visual recognition task. InCPL involves associating a new test sample with very few or even just one labeled example as its in-context prompt. As a result, it can reliably estimate a label for the test sample, thereby facilitating the model adaptation process. InCPL first employs a token net to represent language descriptions as visual prompts that the vision encoder of a CLIP model can comprehend. Paired with in-context examples, we further propose a context-aware unsupervised loss to optimize test sample-aware visual prompts. This optimization allows a pre-trained, frozen CLIP model to be adapted to a test sample from any task using its learned adaptive prompt. Our method has demonstrated superior performance and achieved state-of-the-art results across various downstream datasets.
HumanRecon: Neural Reconstruction of Dynamic Human Using Geometric Cues and Physical Priors
Nov 26, 2023Recent methods for dynamic human reconstruction have attained promising reconstruction results. Most of these methods rely only on RGB color supervision without considering explicit geometric constraints. This leads to existing human reconstruction techniques being more prone to overfitting to color and causes geometrically inherent ambiguities, especially in the sparse multi-view setup. Motivated by recent advances in the field of monocular geometry prediction, we consider the geometric constraints of estimated depth and normals in the learning of neural implicit representation for dynamic human reconstruction. As a geometric regularization, this provides reliable yet explicit supervision information, and improves reconstruction quality. We also exploit several beneficial physical priors, such as adding noise into view direction and maximizing the density on the human surface. These priors ensure the color rendered along rays to be robust to view direction and reduce the inherent ambiguities of density estimated along rays. Experimental results demonstrate that depth and normal cues, predicted by human-specific monocular estimators, can provide effective supervision signals and render more accurate images. Finally, we also show that the proposed physical priors significantly reduce overfitting and improve the overall quality of novel view synthesis. Our code is available at:~\href{https://github.com/PRIS-CV/HumanRecon}{https://github.com/PRIS-CV/HumanRecon}.
DF^2AM: Dual-level Feature Fusion and Affinity Modeling for RGB-Infrared Cross-modality Person Re-identification
Apr 01, 2021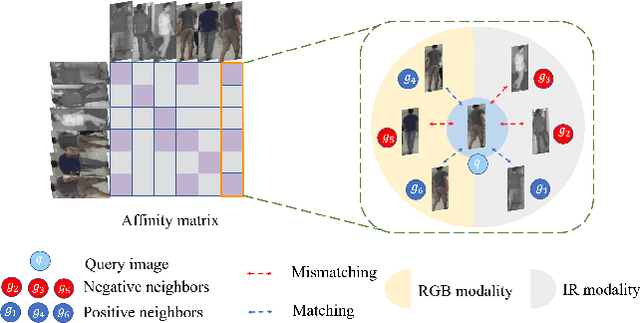
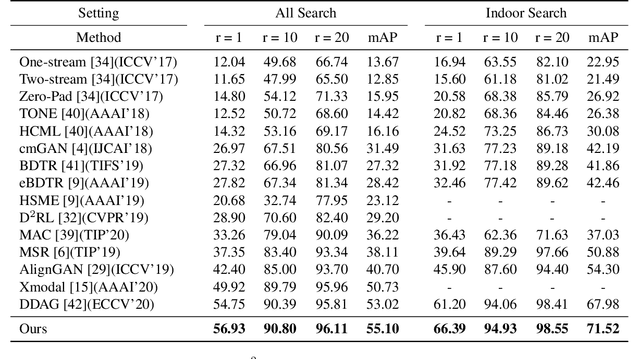
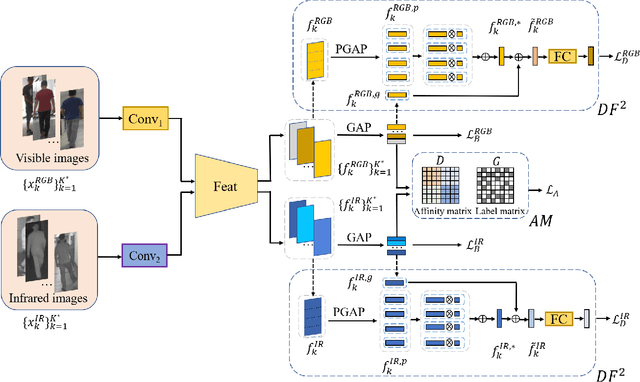
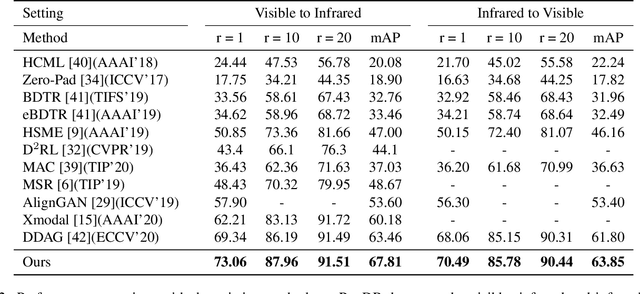
RGB-infrared person re-identification is a challenging task due to the intra-class variations and cross-modality discrepancy. Existing works mainly focus on learning modality-shared global representations by aligning image styles or feature distributions across modalities, while local feature from body part and relationships between person images are largely neglected. In this paper, we propose a Dual-level (i.e., local and global) Feature Fusion (DF^2) module by learning attention for discriminative feature from local to global manner. In particular, the attention for a local feature is determined locally, i.e., applying a learned transformation function on itself. Meanwhile, to further mining the relationships between global features from person images, we propose an Affinities Modeling (AM) module to obtain the optimal intra- and inter-modality image matching. Specifically, AM employes intra-class compactness and inter-class separability in the sample similarities as supervised information to model the affinities between intra- and inter-modality samples. Experimental results show that our proposed method outperforms state-of-the-arts by large margins on two widely used cross-modality re-ID datasets SYSU-MM01 and RegDB, respectively.
Unsupervised Person Re-identification via Simultaneous Clustering and Consistency Learning
Apr 01, 2021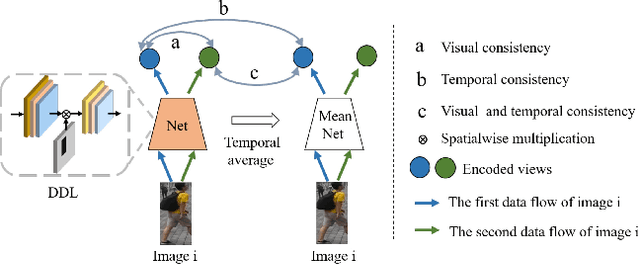
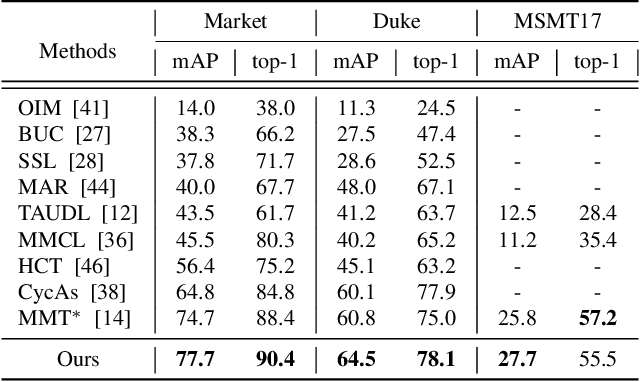
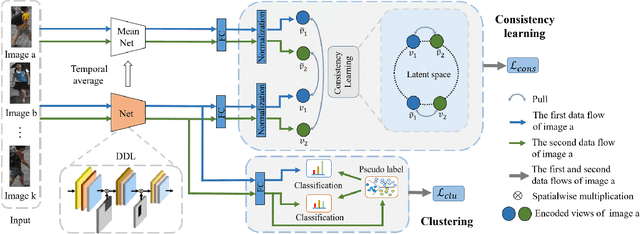
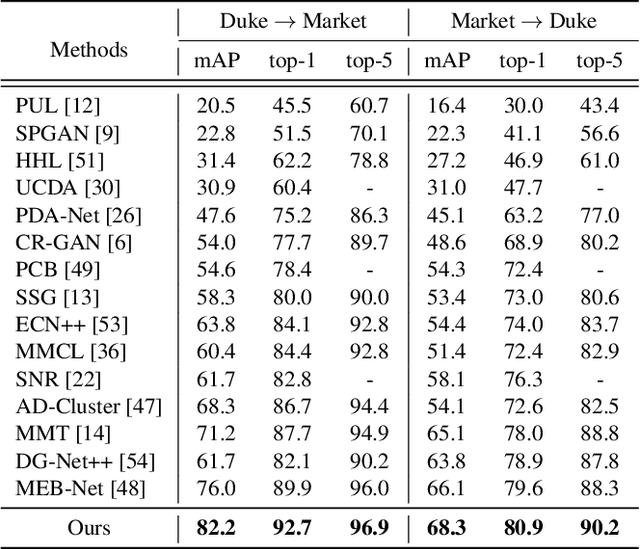
Unsupervised person re-identification (re-ID) has become an important topic due to its potential to resolve the scalability problem of supervised re-ID models. However, existing methods simply utilize pseudo labels from clustering for supervision and thus have not yet fully explored the semantic information in data itself, which limits representation capabilities of learned models. To address this problem, we design a pretext task for unsupervised re-ID by learning visual consistency from still images and temporal consistency during training process, such that the clustering network can separate the images into semantic clusters automatically. Specifically, the pretext task learns semantically meaningful representations by maximizing the agreement between two encoded views of the same image via a consistency loss in latent space. Meanwhile, we optimize the model by grouping the two encoded views into same cluster, thus enhancing the visual consistency between views. Experiments on Market-1501, DukeMTMC-reID and MSMT17 datasets demonstrate that our proposed approach outperforms the state-of-the-art methods by large margins.
SSKD: Self-Supervised Knowledge Distillation for Cross Domain Adaptive Person Re-Identification
Sep 13, 2020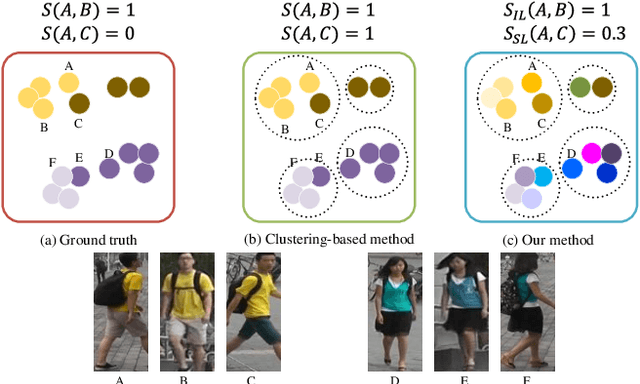
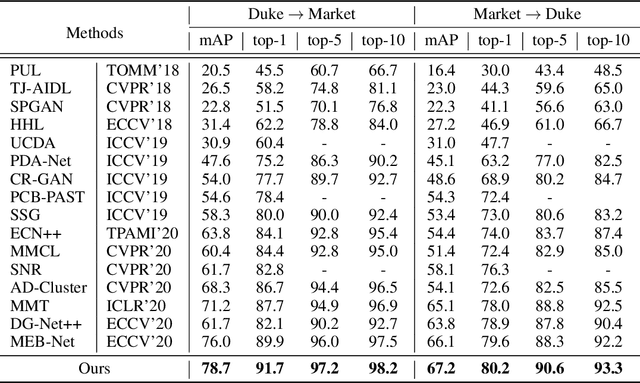
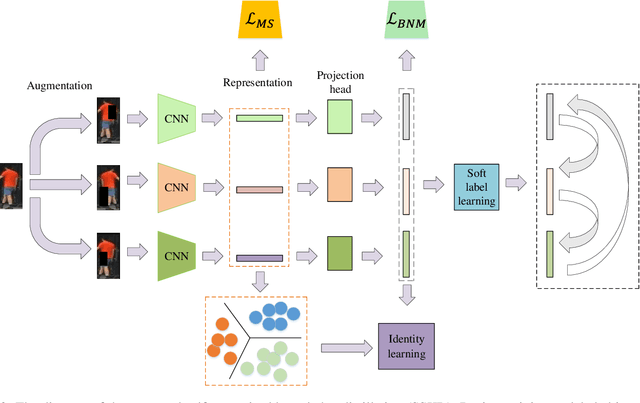
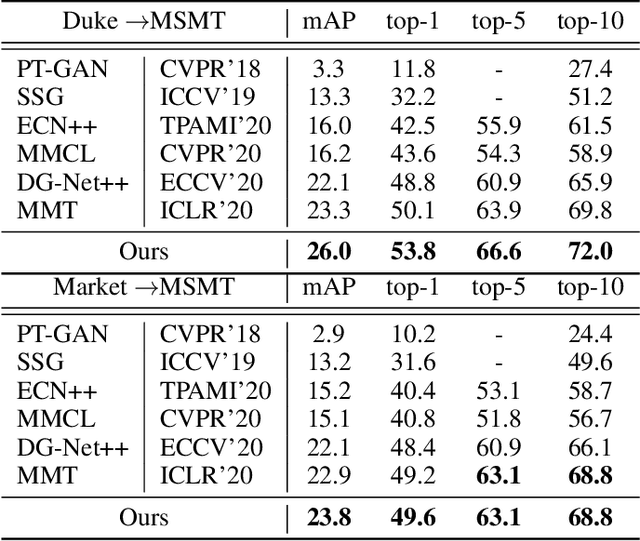
Domain adaptive person re-identification (re-ID) is a challenging task due to the large discrepancy between the source domain and the target domain. To reduce the domain discrepancy, existing methods mainly attempt to generate pseudo labels for unlabeled target images by clustering algorithms. However, clustering methods tend to bring noisy labels and the rich fine-grained details in unlabeled images are not sufficiently exploited. In this paper, we seek to improve the quality of labels by capturing feature representation from multiple augmented views of unlabeled images. To this end, we propose a Self-Supervised Knowledge Distillation (SSKD) technique containing two modules, the identity learning and the soft label learning. Identity learning explores the relationship between unlabeled samples and predicts their one-hot labels by clustering to give exact information for confidently distinguished images. Soft label learning regards labels as a distribution and induces an image to be associated with several related classes for training peer network in a self-supervised manner, where the slowly evolving network is a core to obtain soft labels as a gentle constraint for reliable images. Finally, the two modules can resist label noise for re-ID by enhancing each other and systematically integrating label information from unlabeled images. Extensive experiments on several adaptation tasks demonstrate that the proposed method outperforms the current state-of-the-art approaches by large margins.
Dual-attention Guided Dropblock Module for Weakly Supervised Object Localization
Mar 19, 2020
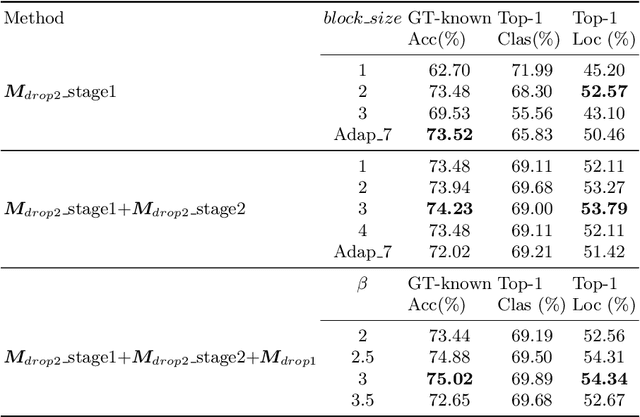
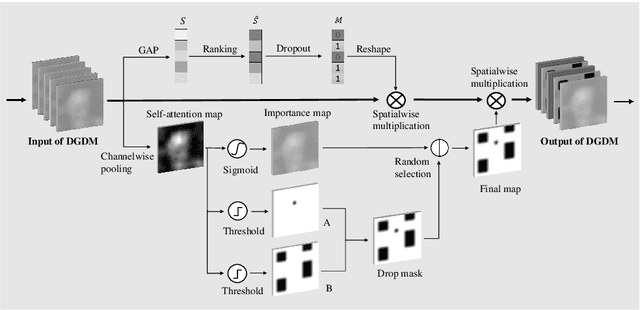
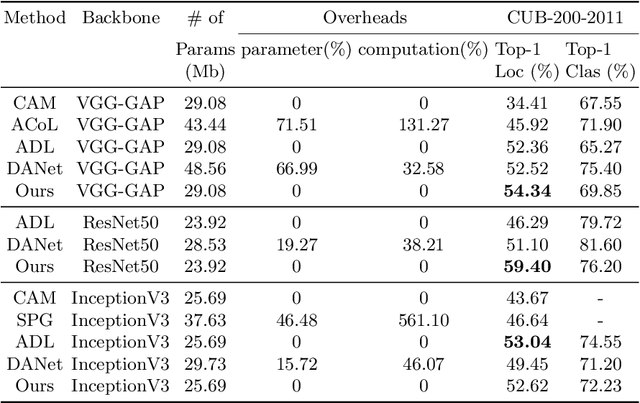
In this paper, we present a dual-attention guided dropblock module, and aim at learning the informative and complementary visual features for weakly supervised object localization (WSOL). The attention mechanism is extended to the task of WSOL, and design two types of attention modules to learn the discriminative features for better feature representations. Based on two types of attention mechanism, we propose a channel attention guided dropout (CAGD) and a spatial attention guided dropblock (SAGD). The CAGD ranks channel attention by a measure of importance and consider the top-k largest magnitude attentions as important ones. The SAGD can not only completely remove the information by erasing the contiguous regions of feature maps rather than individual pixels, but also simply distinguish the foreground objects and background regions to alleviate the attention misdirection. Extensive experiments demonstrate that the proposed method achieves new state-of-the-art localization accuracy on a challenging dataset.