 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-attention Guided Dropblock Module for Weakly Supervised Object Localization
Paper and Code

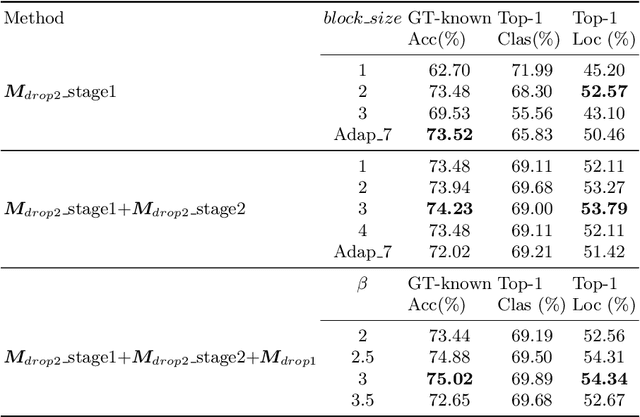
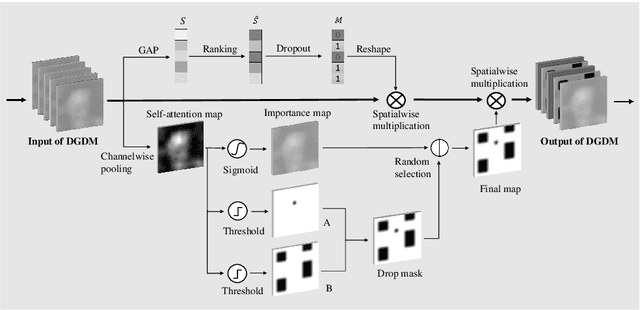
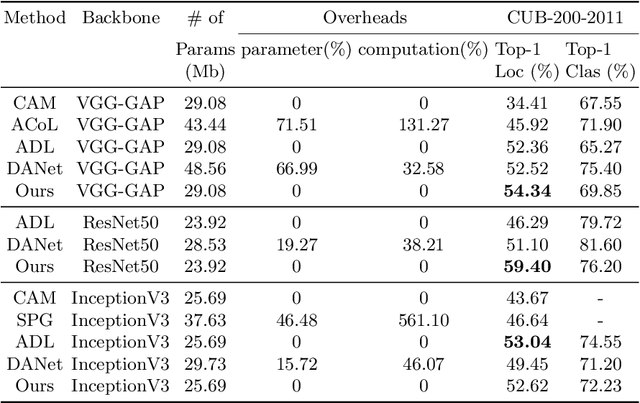
In this paper, we present a dual-attention guided dropblock module, and aim at learning the informative and complementary visual features for weakly supervised object localization (WSOL). The attention mechanism is extended to the task of WSOL, and design two types of attention modules to learn the discriminative features for better feature representations. Based on two types of attention mechanism, we propose a channel attention guided dropout (CAGD) and a spatial attention guided dropblock (SAGD). The CAGD ranks channel attention by a measure of importance and consider the top-k largest magnitude attentions as important ones. The SAGD can not only completely remove the information by erasing the contiguous regions of feature maps rather than individual pixels, but also simply distinguish the foreground objects and background regions to alleviate the attention misdirection. Extensive experiments demonstrate that the proposed method achieves new state-of-the-art localization accuracy on a challenging dataset.