 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAffinity Contrastive Learning for Skeleton-based Human Activity Understanding
Jan 23, 2026In skeleton-based human activity understanding, existing methods often adopt the contrastive learning paradigm to construct a discriminative feature space. However, many of these approaches fail to exploit the structural inter-class similarities and overlook the impact of anomalous positive samples. In this study, we introduce ACLNet, an Affinity Contrastive Learning Network that explores the intricate clustering relationships among human activity classes to improve feature discrimination. Specifically, we propose an affinity metric to refine similarity measurements, thereby forming activity superclasses that provide more informative contrastive signals. A dynamic temperature schedule is also introduced to adaptively adjust the penalty strength for various superclasses. In addition, we employ a margin-based contrastive strategy to improve the separation of hard positive and negative samples within classes. Extensive experiments on NTU RGB+D 60, NTU RGB+D 120, Kinetics-Skeleton, PKU-MMD, FineGYM, and CASIA-B demonstrate the superiority of our method in skeleton-based action recognition, gait recognition, and person re-identification. The source code is available at https://github.com/firework8/ACLNet.
* Accepted by TBIOM
Dual-Phase LLM Reasoning: Self-Evolved Mathematical Frameworks
Jan 09, 2026In recent years, large language models (LLMs) have demonstrated significant potential in complex reasoning tasks like mathematical problem-solving. However, existing research predominantly relies on reinforcement learning (RL) frameworks while overlooking supervised fine-tuning (SFT) methods. This paper proposes a new two-stage training framework that enhances models' self-correction capabilities through self-generated long chain-of-thought (CoT) data. During the first stage, a multi-turn dialogue strategy guides the model to generate CoT data incorporating verification, backtracking, subgoal decomposition, and backward reasoning, with predefined rules filtering high-quality samples for supervised fine-tuning. The second stage employs a difficulty-aware rejection sampling mechanism to dynamically optimize data distribution, strengthening the model's ability to handle complex problems. The approach generates reasoning chains extended over 4 times longer while maintaining strong scalability, proving that SFT effectively activates models' intrinsic reasoning capabilities and provides a resource-efficient pathway for complex task optimization. Experimental results demonstrate performance improvements on mathematical benchmarks including GSM8K and MATH500, with the fine-tuned model achieving a substantial improvement on competition-level problems like AIME24. Code will be open-sourced.
3SGen: Unified Subject, Style, and Structure-Driven Image Generation with Adaptive Task-specific Memory
Dec 22, 2025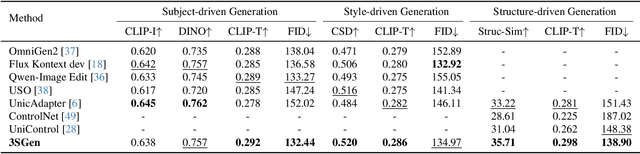
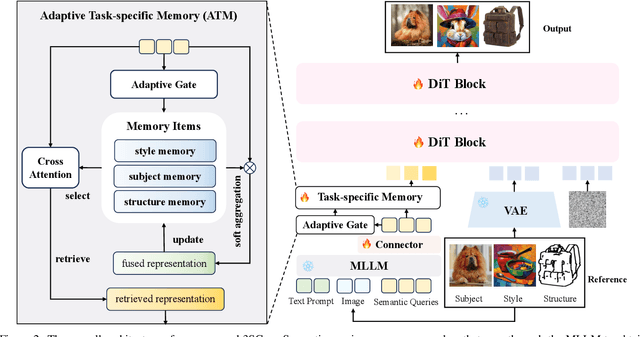
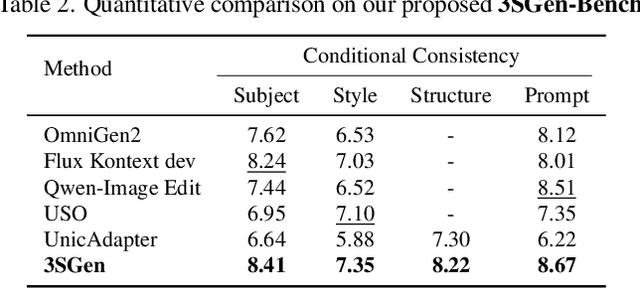
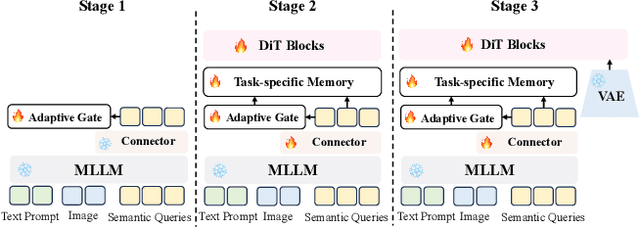
Recent image generation approaches often address subject, style, and structure-driven conditioning in isolation, leading to feature entanglement and limited task transferability. In this paper, we introduce 3SGen, a task-aware unified framework that performs all three conditioning modes within a single model. 3SGen employs an MLLM equipped with learnable semantic queries to align text-image semantics, complemented by a VAE branch that preserves fine-grained visual details. At its core, an Adaptive Task-specific Memory (ATM) module dynamically disentangles, stores, and retrieves condition-specific priors, such as identity for subjects, textures for styles, and spatial layouts for structures, via a lightweight gating mechanism along with several scalable memory items. This design mitigates inter-task interference and naturally scales to compositional inputs. In addition, we propose 3SGen-Bench, a unified image-driven generation benchmark with standardized metrics for evaluating cross-task fidelity and controllability. Extensive experiments on our proposed 3SGen-Bench and other public benchmarks demonstrate our superior performance across diverse image-driven generation tasks.
TTP: Test-Time Padding for Adversarial Detection and Robust Adaptation on Vision-Language Models
Dec 18, 2025



Vision-Language Models (VLMs), such as CLIP, have achieved impressive zero-shot recognition performance but remain highly susceptible to adversarial perturbations, posing significant risks in safety-critical scenarios. Previous training-time defenses rely on adversarial fine-tuning, which requires labeled data and costly retraining, while existing test-time strategies fail to reliably distinguish between clean and adversarial inputs, thereby preventing both adversarial robustness and clean accuracy from reaching their optimum. To address these limitations, we propose Test-Time Padding (TTP), a lightweight defense framework that performs adversarial detection followed by targeted adaptation at inference. TTP identifies adversarial inputs via the cosine similarity shift between CLIP feature embeddings computed before and after spatial padding, yielding a universal threshold for reliable detection across architectures and datasets. For detected adversarial cases, TTP employs trainable padding to restore disrupted attention patterns, coupled with a similarity-aware ensemble strategy for a more robust final prediction. For clean inputs, TTP leaves them unchanged by default or optionally integrates existing test-time adaptation techniques for further accuracy gains. Comprehensive experiments on diverse CLIP backbones and fine-grained benchmarks show that TTP consistently surpasses state-of-the-art test-time defenses, delivering substantial improvements in adversarial robustness without compromising clean accuracy. The code for this paper will be released soon.
Quantization Meets dLLMs: A Systematic Study of Post-training Quantization for Diffusion LLMs
Aug 20, 2025Recent advances in diffusion large language models (dLLMs) have introduced a promising alternative to autoregressive (AR) LLMs for natural language generation tasks, leveraging full attention and denoising-based decoding strategies. However, the deployment of these models on edge devices remains challenging due to their massive parameter scale and high resource demands. While post-training quantization (PTQ) has emerged as a widely adopted technique for compressing AR LLMs, its applicability to dLLMs remains largely unexplored. In this work, we present the first systematic study on quantizing diffusion-based language models. We begin by identifying the presence of activation outliers, characterized by abnormally large activation values that dominate the dynamic range. These outliers pose a key challenge to low-bit quantization, as they make it difficult to preserve precision for the majority of values. More importantly, we implement state-of-the-art PTQ methods and conduct a comprehensive evaluation across multiple task types and model variants. Our analysis is structured along four key dimensions: bit-width, quantization method, task category, and model type. Through this multi-perspective evaluation, we offer practical insights into the quantization behavior of dLLMs under different configurations. We hope our findings provide a foundation for future research in efficient dLLM deployment. All codes and experimental setups will be released to support the community.
ReMeREC: Relation-aware and Multi-entity Referring Expression Comprehension
Jul 22, 2025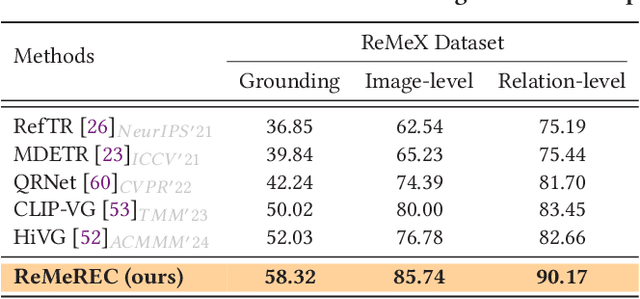

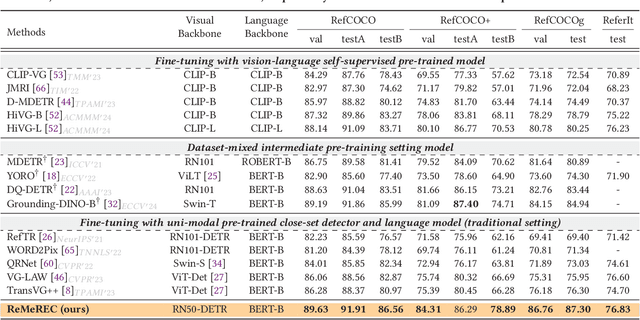
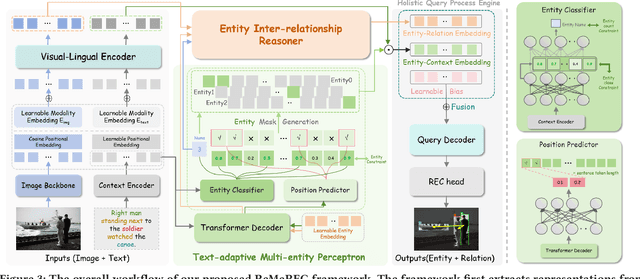
Referring Expression Comprehension (REC) aims to localize specified entities or regions in an image based on natural language descriptions. While existing methods handle single-entity localization, they often ignore complex inter-entity relationships in multi-entity scenes, limiting their accuracy and reliability. Additionally, the lack of high-quality datasets with fine-grained, paired image-text-relation annotations hinders further progress. To address this challenge, we first construct a relation-aware, multi-entity REC dataset called ReMeX, which includes detailed relationship and textual annotations. We then propose ReMeREC, a novel framework that jointly leverages visual and textual cues to localize multiple entities while modeling their inter-relations. To address the semantic ambiguity caused by implicit entity boundaries in language, we introduce the Text-adaptive Multi-entity Perceptron (TMP), which dynamically infers both the quantity and span of entities from fine-grained textual cues, producing distinctive representations. Additionally, our Entity Inter-relationship Reasoner (EIR) enhances relational reasoning and global scene understanding. To further improve language comprehension for fine-grained prompts, we also construct a small-scale auxiliary dataset, EntityText, generated using large language models. Experiments on four benchmark datasets show that ReMeREC achieves state-of-the-art performance in multi-entity grounding and relation prediction, outperforming existing approaches by a large margin.
TokLIP: Marry Visual Tokens to CLIP for Multimodal Comprehension and Generation
May 08, 2025Pioneering token-based works such as Chameleon and Emu3 have established a foundation for multimodal unification but face challenges of high training computational overhead and limited comprehension performance due to a lack of high-level semantics. In this paper, we introduce TokLIP, a visual tokenizer that enhances comprehension by semanticizing vector-quantized (VQ) tokens and incorporating CLIP-level semantics while enabling end-to-end multimodal autoregressive training with standard VQ tokens. TokLIP integrates a low-level discrete VQ tokenizer with a ViT-based token encoder to capture high-level continuous semantics. Unlike previous approaches (e.g., VILA-U) that discretize high-level features, TokLIP disentangles training objectives for comprehension and generation, allowing the direct application of advanced VQ tokenizers without the need for tailored quantization operations. Our empirical results demonstrate that TokLIP achieves exceptional data efficiency, empowering visual tokens with high-level semantic understanding while enhancing low-level generative capacity, making it well-suited for autoregressive Transformers in both comprehension and generation tasks. The code and models are available at https://github.com/TencentARC/TokLIP.
Learning Unknown Spoof Prompts for Generalized Face Anti-Spoofing Using Only Real Face Images
May 06, 2025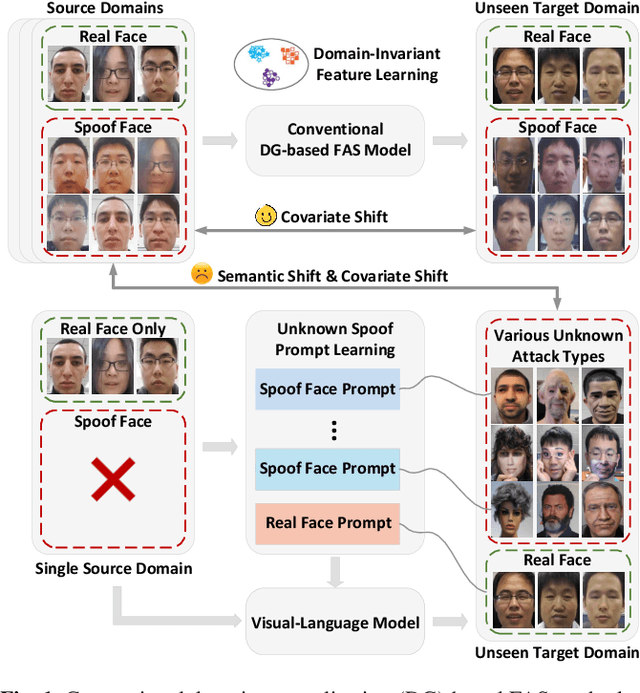

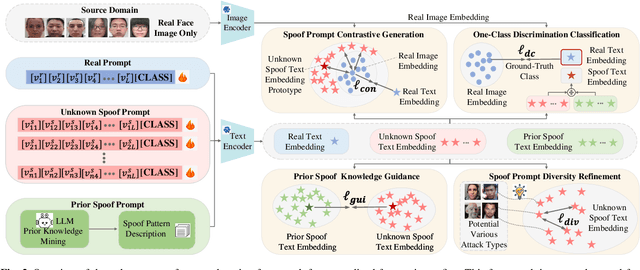
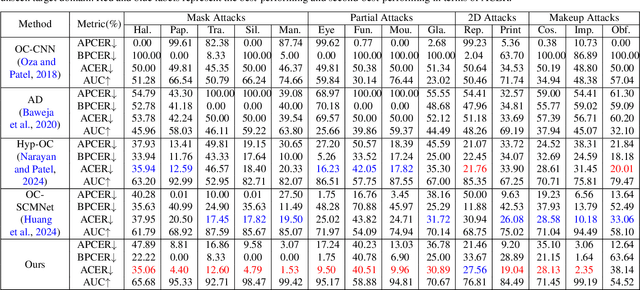
Face anti-spoofing is a critical technology for ensuring the security of face recognition systems. However, its ability to generalize across diverse scenarios remains a significant challenge. In this paper, we attribute the limited generalization ability to two key factors: covariate shift, which arises from external data collection variations, and semantic shift, which results from substantial differences in emerging attack types. To address both challenges, we propose a novel approach for learning unknown spoof prompts, relying solely on real face images from a single source domain. Our method generates textual prompts for real faces and potential unknown spoof attacks by leveraging the general knowledge embedded in vision-language models, thereby enhancing the model's ability to generalize to unseen target domains. Specifically, we introduce a diverse spoof prompt optimization framework to learn effective prompts. This framework constrains unknown spoof prompts within a relaxed prior knowledge space while maximizing their distance from real face images. Moreover, it enforces semantic independence among different spoof prompts to capture a broad range of spoof patterns. Experimental results on nine datasets demonstrate that the learned prompts effectively transfer the knowledge of vision-language models, enabling state-of-the-art generalization ability against diverse unknown attack types across unseen target domains without using any spoof face images.
Learning Knowledge-based Prompts for Robust 3D Mask Presentation Attack Detection
May 06, 20253D mask presentation attack detection is crucial for protecting face recognition systems against the rising threat of 3D mask attacks. While most existing methods utilize multimodal features or remote photoplethysmography (rPPG) signals to distinguish between real faces and 3D masks, they face significant challenges, such as the high costs associated with multimodal sensors and limited generalization ability. Detection-related text descriptions offer concise, universal information and are cost-effective to obtain. However, the potential of vision-language multimodal features for 3D mask presentation attack detection remains unexplored. In this paper, we propose a novel knowledge-based prompt learning framework to explore the strong generalization capability of vision-language models for 3D mask presentation attack detection. Specifically, our approach incorporates entities and triples from knowledge graphs into the prompt learning process, generating fine-grained, task-specific explicit prompts that effectively harness the knowledge embedded in pre-trained vision-language models. Furthermore, considering different input images may emphasize distinct knowledge graph elements, we introduce a visual-specific knowledge filter based on an attention mechanism to refine relevant elements according to the visual context. Additionally, we leverage causal graph theory insights into the prompt learning process to further enhance the generalization ability of our method. During training, a spurious correlation elimination paradigm is employed, which removes category-irrelevant local image patches using guidance from knowledge-based text features, fostering the learning of generalized causal prompts that align with category-relevant local patches. Experimental results demonstrate that the proposed method achieves state-of-the-art intra- and cross-scenario detection performance on benchmark datasets.
VividListener: Expressive and Controllable Listener Dynamics Modeling for Multi-Modal Responsive Interaction
Apr 30, 2025



Generating responsive listener head dynamics with nuanced emotions and expressive reactions is crucial for practical dialogue modeling in various virtual avatar animations. Previous studies mainly focus on the direct short-term production of listener behavior. They overlook the fine-grained control over motion variations and emotional intensity, especially in long-sequence modeling. Moreover, the lack of long-term and large-scale paired speaker-listener corpora including head dynamics and fine-grained multi-modality annotations (e.g., text-based expression descriptions, emotional intensity) also limits the application of dialogue modeling.Therefore, we first newly collect a large-scale multi-turn dataset of 3D dyadic conversation containing more than 1.4M valid frames for multi-modal responsive interaction, dubbed ListenerX. Additionally, we propose VividListener, a novel framework enabling fine-grained, expressive and controllable listener dynamics modeling. This framework leverages multi-modal conditions as guiding principles for fostering coherent interactions between speakers and listeners.Specifically, we design the Responsive Interaction Module (RIM) to adaptively represent the multi-modal interactive embeddings. RIM ensures the listener dynamics achieve fine-grained semantic coordination with textual descriptions and adjustments, while preserving expressive reaction with speaker behavior. Meanwhile, we design the Emotional Intensity Tags (EIT) for emotion intensity editing with multi-modal information integration, applying to both text descriptions and listener motion amplitude.Extensive experiments conducted on our newly collected ListenerX dataset demonstrate that VividListener achieves state-of-the-art performance, realizing expressive and controllable listener dynamics.