 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePivoting Factorization: A Compact Meta Low-Rank Representation of Sparsity for Efficient Inference in Large Language Models
Jan 31, 2025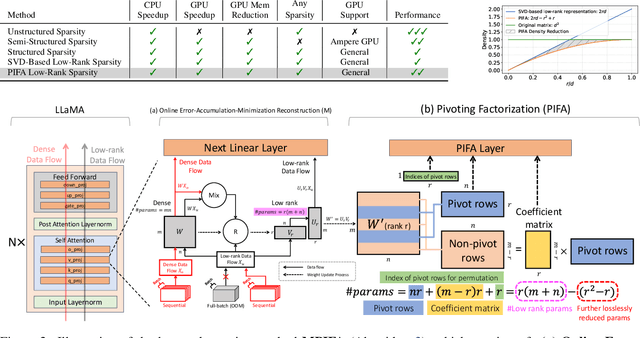
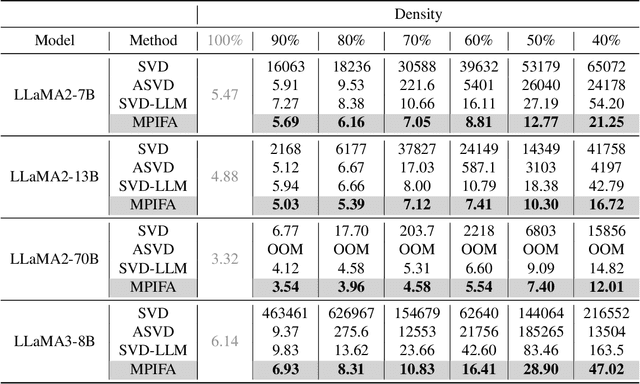
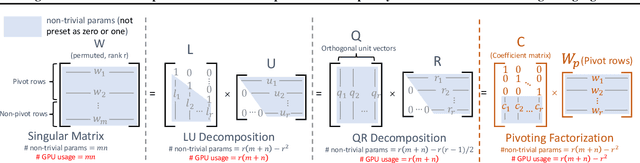
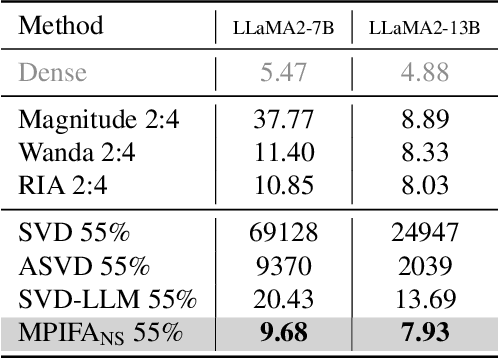
The rapid growth of Large Language Models has driven demand for effective model compression techniques to reduce memory and computation costs. Low-rank pruning has gained attention for its tensor coherence and GPU compatibility across all densities. However, low-rank pruning has struggled to match the performance of semi-structured pruning, often doubling perplexity (PPL) at similar densities. In this paper, we propose Pivoting Factorization (PIFA), a novel lossless meta low-rank representation that unsupervisedly learns a compact form of any low-rank representation, effectively eliminating redundant information. PIFA identifies pivot rows (linearly independent rows) and expresses non-pivot rows as linear combinations, achieving an additional 24.2\% memory savings and 24.6\% faster inference over low-rank layers at r/d = 0.5, thereby significantly enhancing performance at the same density. To mitigate the performance degradation caused by low-rank pruning, we introduce a novel, retraining-free low-rank reconstruction method that minimizes error accumulation (M). MPIFA, combining M and PIFA into an end-to-end framework, significantly outperforms existing low-rank pruning methods and, for the first time, achieves performance comparable to semi-structured pruning, while surpassing it in GPU efficiency and compatibility.
Brain-inspired sparse training enables Transformers and LLMs to perform as fully connected
Jan 31, 2025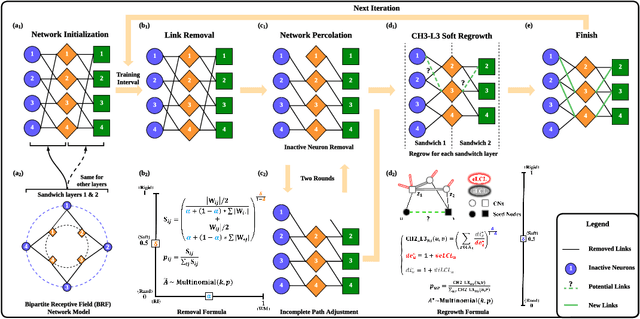
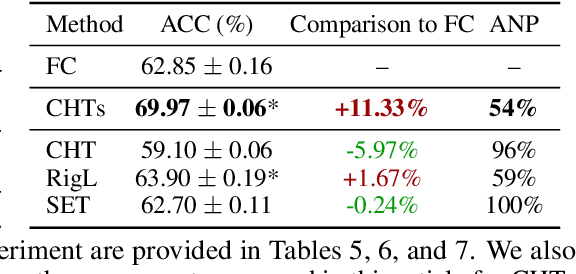
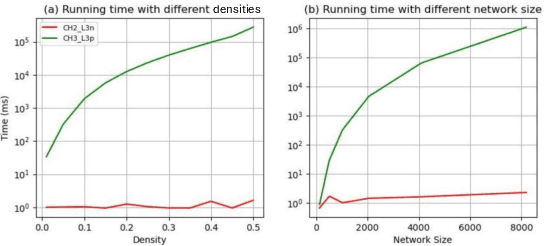
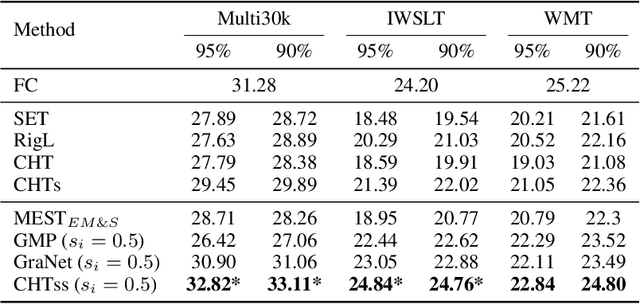
This study aims to enlarge our current knowledge on application of brain-inspired network science principles for training artificial neural networks (ANNs) with sparse connectivity. Dynamic sparse training (DST) can reduce the computational demands in ANNs, but faces difficulties to keep peak performance at high sparsity levels. The Cannistraci-Hebb training (CHT) is a brain-inspired method for growing connectivity in DST. CHT leverages a gradient-free, topology-driven link regrowth, which has shown ultra-sparse (1% connectivity or lower) advantage across various tasks compared to fully connected networks. Yet, CHT suffers two main drawbacks: (i) its time complexity is O(Nd^3) - N node network size, d node degree - hence it can apply only to ultra-sparse networks. (ii) it selects top link prediction scores, which is inappropriate for the early training epochs, when the network presents unreliable connections. We propose a GPU-friendly approximation of the CH link predictor, which reduces the computational complexity to O(N^3), enabling a fast implementation of CHT in large-scale models. We introduce the Cannistraci-Hebb training soft rule (CHTs), which adopts a strategy for sampling connections in both link removal and regrowth, balancing the exploration and exploitation of network topology. To improve performance, we integrate CHTs with a sigmoid gradual density decay (CHTss). Empirical results show that, using 1% of connections, CHTs outperforms fully connected networks in MLP on visual classification tasks, compressing some networks to < 30% nodes. Using 5% of the connections, CHTss outperforms fully connected networks in two Transformer-based machine translation tasks. Using 30% of the connections, CHTss achieves superior performance compared to other dynamic sparse training methods in language modeling, and it surpasses the fully connected counterpart in zero-shot evaluations.
Rotation and Permutation for Advanced Outlier Management and Efficient Quantization of LLMs
Jun 03, 2024



Quantizing large language models (LLMs) presents significant challenges, primarily due to outlier activations that compromise the efficiency of low-bit representation. Traditional approaches mainly focus on solving Normal Outliers-activations with consistently high magnitudes across all tokens. However, these techniques falter when dealing with Massive Outliers, which are significantly higher in value and often cause substantial performance losses during low-bit quantization. In this study, we propose DuQuant, an innovative quantization strategy employing rotation and permutation transformations to more effectively eliminate both types of outliers. Initially, DuQuant constructs rotation matrices informed by specific outlier dimensions, redistributing these outliers across adjacent channels within different rotation blocks. Subsequently, a zigzag permutation is applied to ensure a balanced distribution of outliers among blocks, minimizing block-wise variance. An additional rotation further enhances the smoothness of the activation landscape, thereby improving model performance. DuQuant streamlines the quantization process and demonstrates superior outlier management, achieving top-tier results in multiple tasks with various LLM architectures even under 4-bit weight-activation quantization. Our code is available at https://github.com/Hsu1023/DuQuant.
Sparse Spectral Training and Inference on Euclidean and Hyperbolic Neural Networks
May 24, 2024The growing computational demands posed by increasingly number of neural network's parameters necessitate low-memory-consumption training approaches. Previous memory reduction techniques, such as Low-Rank Adaptation (LoRA) and ReLoRA, suffer from the limitation of low rank and saddle point issues, particularly during intensive tasks like pre-training. In this paper, we propose Sparse Spectral Training (SST), an advanced training methodology that updates all singular values and selectively updates singular vectors of network weights, thereby optimizing resource usage while closely approximating full-rank training. SST refines the training process by employing a targeted updating strategy for singular vectors, which is determined by a multinomial sampling method weighted by the significance of the singular values, ensuring both high performance and memory reduction. Through comprehensive testing on both Euclidean and hyperbolic neural networks across various tasks, including natural language generation, machine translation, node classification and link prediction, SST demonstrates its capability to outperform existing memory reduction training methods and is comparable with full-rank training in some cases. On OPT-125M, with rank equating to 8.3% of embedding dimension, SST reduces the perplexity gap to full-rank training by 67.6%, demonstrating a significant reduction of the performance loss with prevalent low-rank methods. This approach offers a strong alternative to traditional training techniques, paving the way for more efficient and scalable neural network training solutions.
ColoristaNet for Photorealistic Video Style Transfer
Dec 21, 2022



Photorealistic style transfer aims to transfer the artistic style of an image onto an input image or video while keeping photorealism. In this paper, we think it's the summary statistics matching scheme in existing algorithms that leads to unrealistic stylization. To avoid employing the popular Gram loss, we propose a self-supervised style transfer framework, which contains a style removal part and a style restoration part. The style removal network removes the original image styles, and the style restoration network recovers image styles in a supervised manner. Meanwhile, to address the problems in current feature transformation methods, we propose decoupled instance normalization to decompose feature transformation into style whitening and restylization. It works quite well in ColoristaNet and can transfer image styles efficiently while keeping photorealism. To ensure temporal coherency, we also incorporate optical flow methods and ConvLSTM to embed contextual information. Experiments demonstrates that ColoristaNet can achieve better stylization effects when compared with state-of-the-art algorithms.
The HW-TSC's Offline Speech Translation Systems for IWSLT 2021 Evaluation
Aug 09, 2021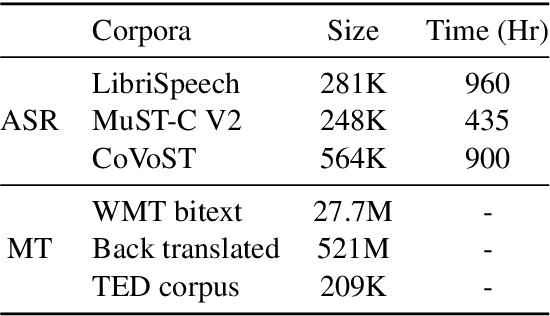
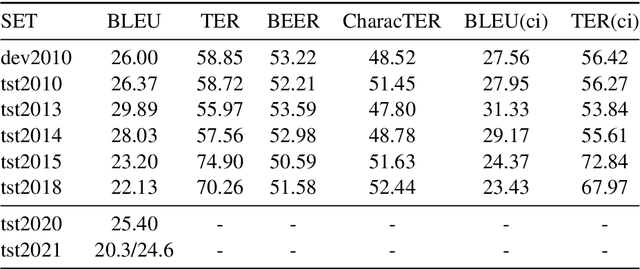
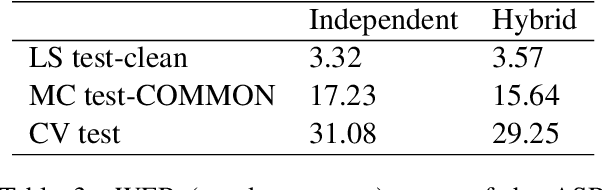
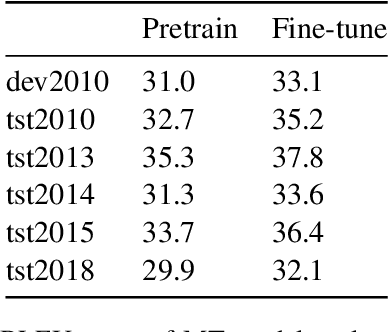
This paper describes our work in participation of the IWSLT-2021 offline speech translation task. Our system was built in a cascade form, including a speaker diarization module, an Automatic Speech Recognition (ASR) module and a Machine Translation (MT) module. We directly use the LIUM SpkDiarization tool as the diarization module. The ASR module is trained with three ASR datasets from different sources, by multi-source training, using a modified Transformer encoder. The MT module is pretrained on the large-scale WMT news translation dataset and fine-tuned on the TED corpus. Our method achieves 24.6 BLEU score on the 2021 test set.
Fuzzy Semantic Segmentation of Breast Ultrasound Image with Breast Anatomy Constraints
Oct 23, 2019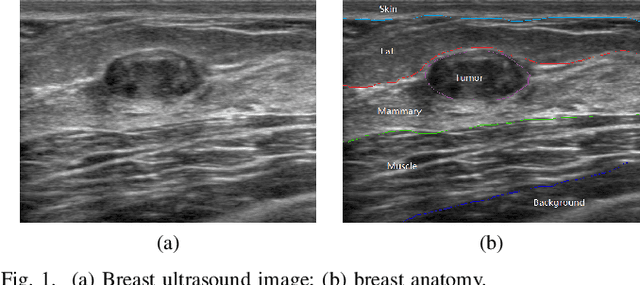


Breast cancer is one of the most serious disease affecting women's health. Due to low cost, portable, no radiation, and high efficiency, breast ultrasound (BUS) imaging is the most popular approach for diagnosing early breast cancer. However, ultrasound images are low resolution and poor quality. Thus, developing accurate detection system is a challenging task. In this paper, we propose a fully automatic segmentation algorithm consisting of two parts: fuzzy fully convolutional network and accurately fine-tuning post-processing based on breast anatomy constraints. In the first part, the image is preprocessed by contrast enhancement, and wavelet features are employed for image augmentation. A fuzzy membership function transforms the augmented BUS images into fuzzy domain. The features from convolutional layers are processed using fuzzy logic as well. The conditional random fields (CRFs) post-process the segmentation result. The location relation among the breast anatomy layers is utilized to improve the performance. The proposed method is applied to the dataset with 325 BUS images, and achieves state-of-art performance compared with that of existing methods with true positive rate 90.33%, false positive rate 9.00%, and intersection over union (IoU) 81.29% on tumor category, and overall intersection over union (mIoU) 80.47% over five categories: fat layer, mammary layer, muscle layer, background, and tumor.
Breast Anatomy Enriched Tumor Saliency Estimation
Oct 23, 2019

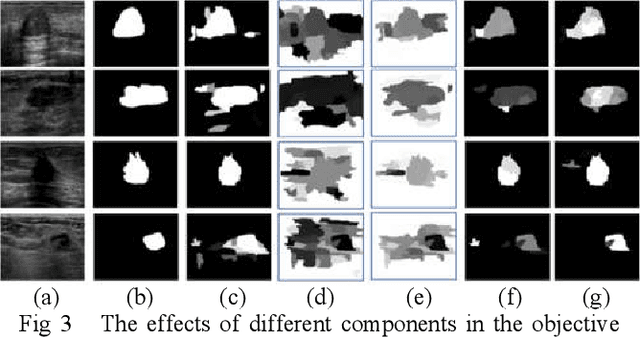
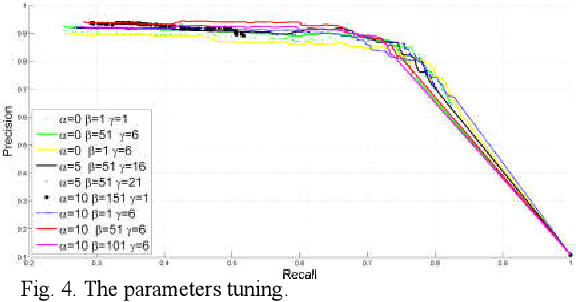
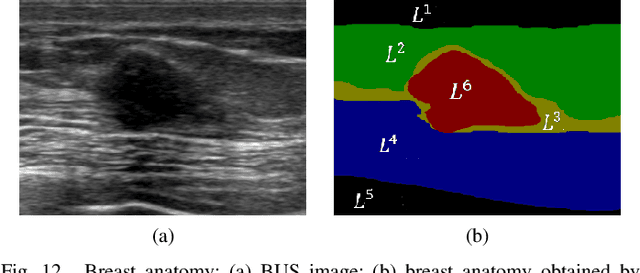
Breast cancer investigation is of great significance, and developing tumor detection methodologies is a critical need. However, it is a challenging task for breast ultrasound due to the complicated breast structure and poor quality of the images. In this paper, we propose a novel tumor saliency estimation model guided by enriched breast anatomy knowledge to localize the tumor. Firstly, the breast anatomy layers are generated by a deep neural network. Then we refine the layers by integrating a non-semantic breast anatomy model to solve the problems of incomplete mammary layers. Meanwhile, a new background map generation method weighted by the semantic probability and spatial distance is proposed to improve the performance. The experiment demonstrates that the proposed method with the new background map outperforms four state-of-the-art TSE models with increasing 10% of F_meansure on the BUS public dataset.
CrackGAN: A Labor-Light Crack Detection Approach Using Industrial Pavement Images Based on Generative Adversarial Learning
Sep 18, 2019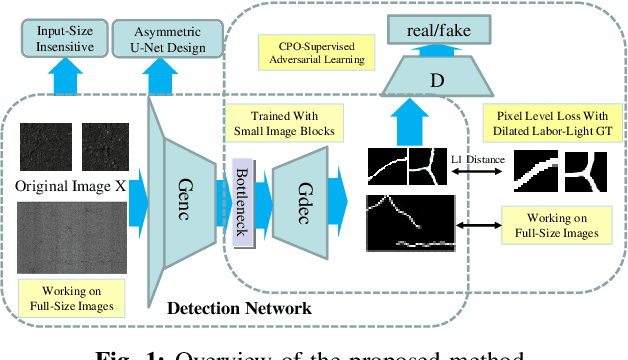
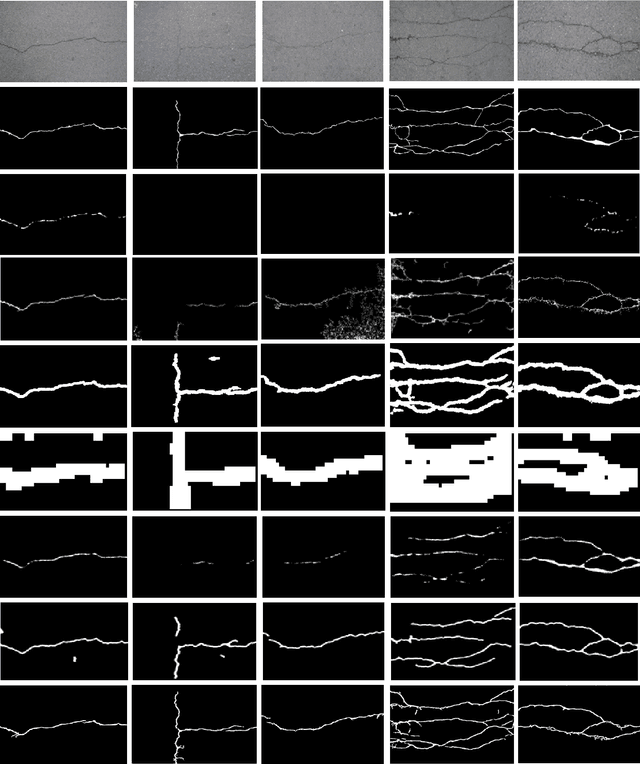
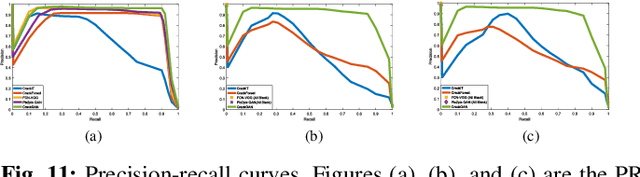

Fully convolutional network is a powerful tool for per-pixel semantic segmentation/detection. However, it is problematic when coping with crack detection using industrial pavement images: the network may easily "converge" to the status that treats all the pixels as background (BG) and still achieves a very good loss, named "All Black" phenomenon, due to the data imbalance and the unavailability of accurate ground truths (GTs). To tackle this problem, we introduce crack-patch-only (CPO) supervision and generative adversarial learning for end-to-end training, which forces the network to always produce crack-GT images while reserves both crack and BG-image translation abilities by feeding a larger-size crack image into an asymmetric U-shape generator to overcome the "All Black" issue. The proposed approach is validated using four crack datasets; and achieves state-of-the-art performance comparing with that of the recently published works in efficiency and accuracy.
Tumor Saliency Estimation for Breast Ultrasound Images via Breast Anatomy Modeling
Jun 18, 2019
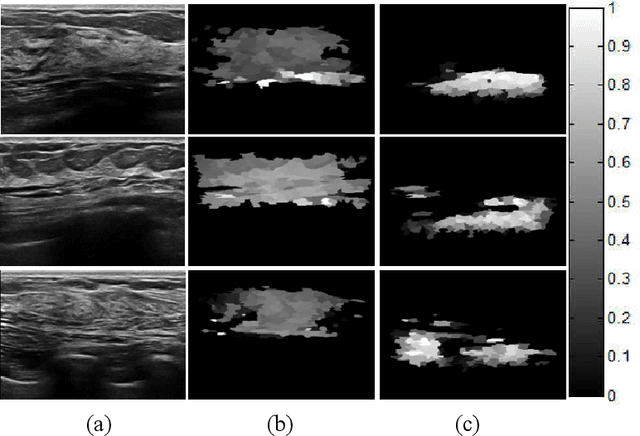

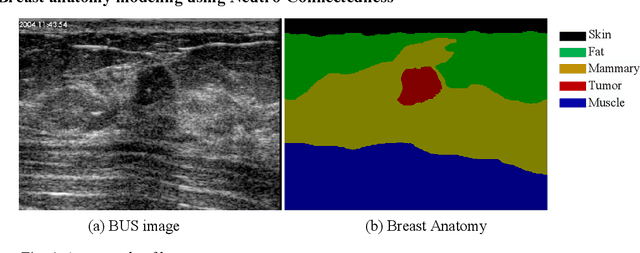
Tumor saliency estimation aims to localize tumors by modeling the visual stimuli in medical images. However, it is a challenging task for breast ultrasound due to the complicated anatomic structure of the breast and poor image quality; and existing saliency estimation approaches only model generic visual stimuli, e.g., local and global contrast, location, and feature correlation, and achieve poor performance for tumor saliency estimation. In this paper, we propose a novel optimization model to estimate tumor saliency by utilizing breast anatomy. First, we model breast anatomy and decompose breast ultrasound image into layers using Neutro-Connectedness; then utilize the layers to generate the foreground and background maps; and finally propose a novel objective function to estimate the tumor saliency by integrating the foreground map, background map, adaptive center bias, and region-based correlation cues. The extensive experiments demonstrate that the proposed approach obtains more accurate foreground and background maps with the assistance of the breast anatomy; especially, for the images having large or small tumors; meanwhile, the new objective function can handle the images without tumors. The newly proposed method achieves state-of-the-art performance when compared to eight tumor saliency estimation approaches using two breast ultrasound datasets.