 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHysteresis-Aware Neural Network Modeling and Whole-Body Reinforcement Learning Control of Soft Robots
Apr 18, 2025Soft robots exhibit inherent compliance and safety, which makes them particularly suitable for applications requiring direct physical interaction with humans, such as surgical procedures. However, their nonlinear and hysteretic behavior, resulting from the properties of soft materials, presents substantial challenges for accurate modeling and control. In this study, we present a soft robotic system designed for surgical applications and propose a hysteresis-aware whole-body neural network model that accurately captures and predicts the soft robot's whole-body motion, including its hysteretic behavior. Building upon the high-precision dynamic model, we construct a highly parallel simulation environment for soft robot control and apply an on-policy reinforcement learning algorithm to efficiently train whole-body motion control strategies. Based on the trained control policy, we developed a soft robotic system for surgical applications and validated it through phantom-based laser ablation experiments in a physical environment. The results demonstrate that the hysteresis-aware modeling reduces the Mean Squared Error (MSE) by 84.95 percent compared to traditional modeling methods. The deployed control algorithm achieved a trajectory tracking error ranging from 0.126 to 0.250 mm on the real soft robot, highlighting its precision in real-world conditions. The proposed method showed strong performance in phantom-based surgical experiments and demonstrates its potential for complex scenarios, including future real-world clinical applications.
Graph Kolmogorov-Arnold Networks for Multi-Cancer Classification and Biomarker Identification, An Interpretable Multi-Omics Approach
Mar 29, 2025The integration of multi-omics data presents a major challenge in precision medicine, requiring advanced computational methods for accurate disease classification and biological interpretation. This study introduces the Multi-Omics Graph Kolmogorov-Arnold Network (MOGKAN), a deep learning model that integrates messenger RNA, micro RNA sequences, and DNA methylation data with Protein-Protein Interaction (PPI) networks for accurate and interpretable cancer classification across 31 cancer types. MOGKAN employs a hybrid approach combining differential expression with DESeq2, Linear Models for Microarray (LIMMA), and Least Absolute Shrinkage and Selection Operator (LASSO) regression to reduce multi-omics data dimensionality while preserving relevant biological features. The model architecture is based on the Kolmogorov-Arnold theorem principle, using trainable univariate functions to enhance interpretability and feature analysis. MOGKAN achieves classification accuracy of 96.28 percent and demonstrates low experimental variability with a standard deviation that is reduced by 1.58 to 7.30 percents compared to Convolutional Neural Networks (CNNs) and Graph Neural Networks (GNNs). The biomarkers identified by MOGKAN have been validated as cancer-related markers through Gene Ontology (GO) and Kyoto Encyclopedia of Genes and Genomes (KEGG) enrichment analysis. The proposed model presents an ability to uncover molecular oncogenesis mechanisms by detecting phosphoinositide-binding substances and regulating sphingolipid cellular processes. By integrating multi-omics data with graph-based deep learning, our proposed approach demonstrates superior predictive performance and interpretability that has the potential to enhance the translation of complex multi-omics data into clinically actionable cancer diagnostics.
GCSAM: Gradient Centralized Sharpness Aware Minimization
Jan 20, 2025The generalization performance of deep neural networks (DNNs) is a critical factor in achieving robust model behavior on unseen data. Recent studies have highlighted the importance of sharpness-based measures in promoting generalization by encouraging convergence to flatter minima. Among these approaches, Sharpness-Aware Minimization (SAM) has emerged as an effective optimization technique for reducing the sharpness of the loss landscape, thereby improving generalization. However, SAM's computational overhead and sensitivity to noisy gradients limit its scalability and efficiency. To address these challenges, we propose Gradient-Centralized Sharpness-Aware Minimization (GCSAM), which incorporates Gradient Centralization (GC) to stabilize gradients and accelerate convergence. GCSAM normalizes gradients before the ascent step, reducing noise and variance, and improving stability during training. Our evaluations indicate that GCSAM consistently outperforms SAM and the Adam optimizer in terms of generalization and computational efficiency. These findings demonstrate GCSAM's effectiveness across diverse domains, including general and medical imaging tasks.
FinGPT: Enhancing Sentiment-Based Stock Movement Prediction with Dissemination-Aware and Context-Enriched LLMs
Dec 14, 2024



Financial sentiment analysis is crucial for understanding the influence of news on stock prices. Recently, large language models (LLMs) have been widely adopted for this purpose due to their advanced text analysis capabilities. However, these models often only consider the news content itself, ignoring its dissemination, which hampers accurate prediction of short-term stock movements. Additionally, current methods often lack sufficient contextual data and explicit instructions in their prompts, limiting LLMs' ability to interpret news. In this paper, we propose a data-driven approach that enhances LLM-powered sentiment-based stock movement predictions by incorporating news dissemination breadth, contextual data, and explicit instructions. We cluster recent company-related news to assess its reach and influence, enriching prompts with more specific data and precise instructions. This data is used to construct an instruction tuning dataset to fine-tune an LLM for predicting short-term stock price movements. Our experimental results show that our approach improves prediction accuracy by 8\% compared to existing methods.
MVD: A Multi-Lingual Software Vulnerability Detection Framework
Dec 09, 2024Software vulnerabilities can result in catastrophic cyberattacks that increasingly threaten business operations. Consequently, ensuring the safety of software systems has become a paramount concern for both private and public sectors. Recent literature has witnessed increasing exploration of learning-based approaches for software vulnerability detection. However, a key limitation of these techniques is their primary focus on a single programming language, such as C/C++, which poses constraints considering the polyglot nature of modern software projects. Further, there appears to be an oversight in harnessing the synergies of vulnerability knowledge across varied languages, potentially underutilizing the full capabilities of these methods. To address the aforementioned issues, we introduce MVD - an innovative multi-lingual vulnerability detection framework. This framework acquires the ability to detect vulnerabilities across multiple languages by concurrently learning from vulnerability data of various languages, which are curated by our specialized pipeline. We also incorporate incremental learning to enable the detection capability of MVD to be extended to new languages, thus augmenting its practical utility. Extensive experiments on our curated dataset of more than 11K real-world multi-lingual vulnerabilities substantiate that our framework significantly surpasses state-of-the-art methods in multi-lingual vulnerability detection by 83.7% to 193.6% in PR-AUC. The results also demonstrate that MVD detects vulnerabilities well for new languages without compromising the detection performance of previously trained languages, even when training data for the older languages is unavailable. Overall, our findings motivate and pave the way for the prediction of multi-lingual vulnerabilities in modern software systems.
Comparative Analysis of Multi-Omics Integration Using Advanced Graph Neural Networks for Cancer Classification
Oct 05, 2024



Multi-omics data is increasingly being utilized to advance computational methods for cancer classification. However, multi-omics data integration poses significant challenges due to the high dimensionality, data complexity, and distinct characteristics of various omics types. This study addresses these challenges and evaluates three graph neural network architectures for multi-omics (MO) integration based on graph-convolutional networks (GCN), graph-attention networks (GAT), and graph-transformer networks (GTN) for classifying 31 cancer types and normal tissues. To address the high-dimensionality of multi-omics data, we employed LASSO (Least Absolute Shrinkage and Selection Operator) regression for feature selection, leading to the creation of LASSO-MOGCN, LASSO-MOGAT, and LASSO-MOTGN models. Graph structures for the networks were constructed using gene correlation matrices and protein-protein interaction networks for multi-omics integration of messenger-RNA, micro-RNA, and DNA methylation data. Such data integration enables the networks to dynamically focus on important relationships between biological entities, improving both model performance and interpretability. Among the models, LASSO-MOGAT with a correlation-based graph structure achieved state-of-the-art accuracy (95.9%) and outperformed the LASSO-MOGCN and LASSO-MOTGN models in terms of precision, recall, and F1-score. Our findings demonstrate that integrating multi-omics data in graph-based architectures enhances cancer classification performance by uncovering distinct molecular patterns that contribute to a better understanding of cancer biology and potential biomarkers for disease progression.
FinRobot: An Open-Source AI Agent Platform for Financial Applications using Large Language Models
May 23, 2024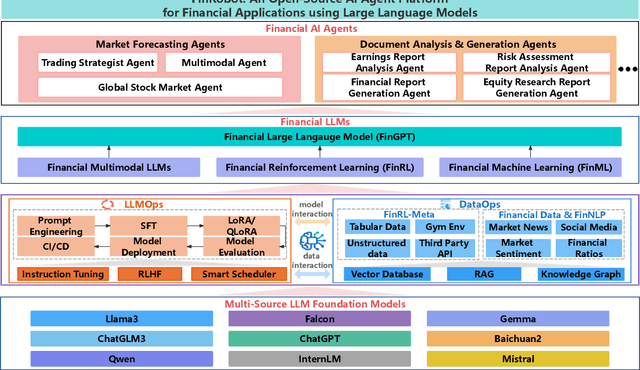
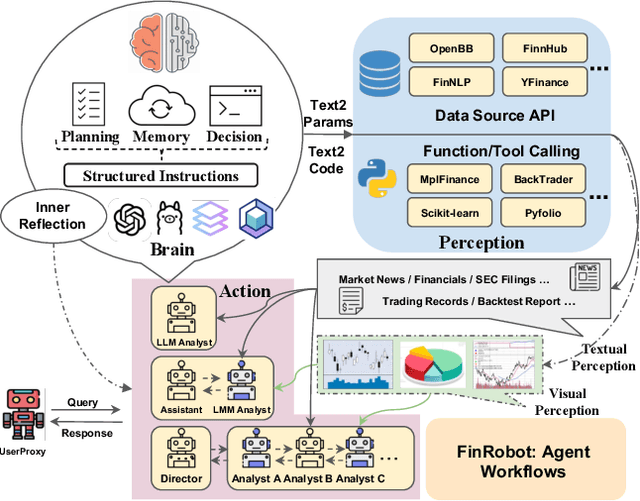
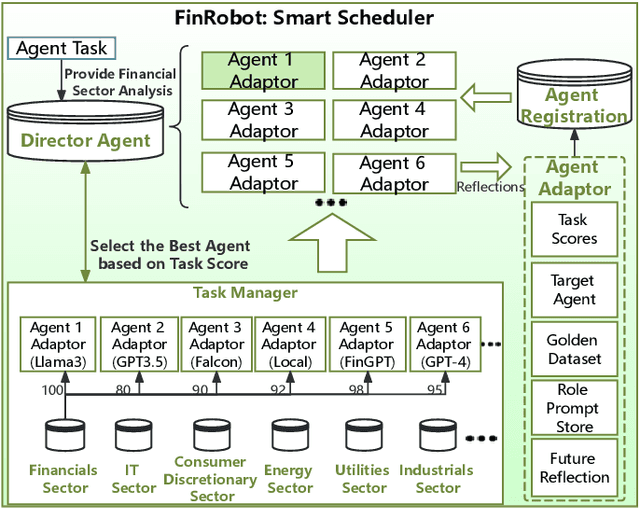

As financial institutions and professionals increasingly incorporate Large Language Models (LLMs) into their workflows, substantial barriers, including proprietary data and specialized knowledge, persist between the finance sector and the AI community. These challenges impede the AI community's ability to enhance financial tasks effectively. Acknowledging financial analysis's critical role, we aim to devise financial-specialized LLM-based toolchains and democratize access to them through open-source initiatives, promoting wider AI adoption in financial decision-making. In this paper, we introduce FinRobot, a novel open-source AI agent platform supporting multiple financially specialized AI agents, each powered by LLM. Specifically, the platform consists of four major layers: 1) the Financial AI Agents layer that formulates Financial Chain-of-Thought (CoT) by breaking sophisticated financial problems down into logical sequences; 2) the Financial LLM Algorithms layer dynamically configures appropriate model application strategies for specific tasks; 3) the LLMOps and DataOps layer produces accurate models by applying training/fine-tuning techniques and using task-relevant data; 4) the Multi-source LLM Foundation Models layer that integrates various LLMs and enables the above layers to access them directly. Finally, FinRobot provides hands-on for both professional-grade analysts and laypersons to utilize powerful AI techniques for advanced financial analysis. We open-source FinRobot at \url{https://github.com/AI4Finance-Foundation/FinRobot}.
Hunting imaging biomarkers in pulmonary fibrosis: Benchmarks of the AIIB23 challenge
Dec 21, 2023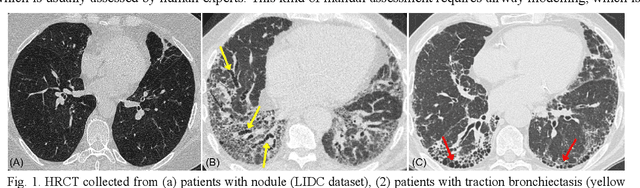
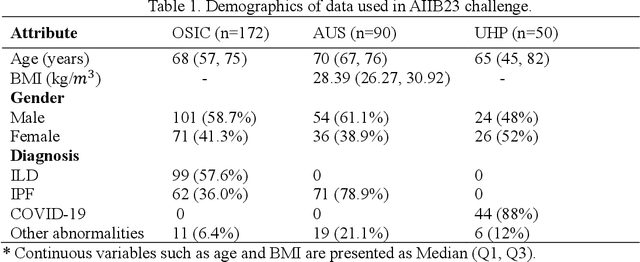
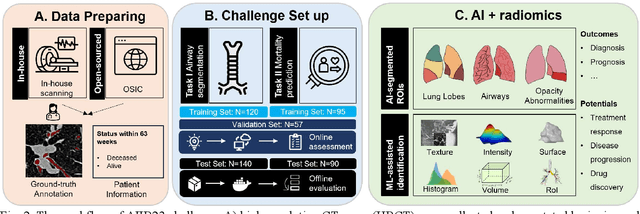
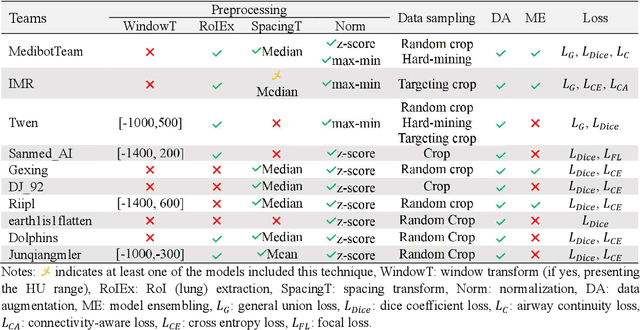
Airway-related quantitative imaging biomarkers are crucial for examination, diagnosis, and prognosis in pulmonary diseases. However, the manual delineation of airway trees remains prohibitively time-consuming. While significant efforts have been made towards enhancing airway modelling, current public-available datasets concentrate on lung diseases with moderate morphological variations. The intricate honeycombing patterns present in the lung tissues of fibrotic lung disease patients exacerbate the challenges, often leading to various prediction errors. To address this issue, the 'Airway-Informed Quantitative CT Imaging Biomarker for Fibrotic Lung Disease 2023' (AIIB23) competition was organized in conjunction with the official 2023 International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI). The airway structures were meticulously annotated by three experienced radiologists. Competitors were encouraged to develop automatic airway segmentation models with high robustness and generalization abilities, followed by exploring the most correlated QIB of mortality prediction. A training set of 120 high-resolution computerised tomography (HRCT) scans were publicly released with expert annotations and mortality status. The online validation set incorporated 52 HRCT scans from patients with fibrotic lung disease and the offline test set included 140 cases from fibrosis and COVID-19 patients. The results have shown that the capacity of extracting airway trees from patients with fibrotic lung disease could be enhanced by introducing voxel-wise weighted general union loss and continuity loss. In addition to the competitive image biomarkers for prognosis, a strong airway-derived biomarker (Hazard ratio>1.5, p<0.0001) was revealed for survival prognostication compared with existing clinical measurements, clinician assessment and AI-based biomarkers.
Mechanical Characterization and Inverse Design of Stochastic Architected Metamaterials Using Neural Operators
Nov 23, 2023Machine learning (ML) is emerging as a transformative tool for the design of architected materials, offering properties that far surpass those achievable through lab-based trial-and-error methods. However, a major challenge in current inverse design strategies is their reliance on extensive computational and/or experimental datasets, which becomes particularly problematic for designing micro-scale stochastic architected materials that exhibit nonlinear mechanical behaviors. Here, we introduce a new end-to-end scientific ML framework, leveraging deep neural operators (DeepONet), to directly learn the relationship between the complete microstructure and mechanical response of architected metamaterials from sparse but high-quality in situ experimental data. The approach facilitates the inverse design of structures tailored to specific nonlinear mechanical behaviors. Results obtained from spinodal microstructures, printed using two-photon lithography, reveal that the prediction error for mechanical responses is within a range of 5 - 10%. Our work underscores that by employing neural operators with advanced micro-mechanics experimental techniques, the design of complex micro-architected materials with desired properties becomes feasible, even in scenarios constrained by data scarcity. Our work marks a significant advancement in the field of materials-by-design, potentially heralding a new era in the discovery and development of next-generation metamaterials with unparalleled mechanical characteristics derived directly from experimental insights.
Enhancing Financial Sentiment Analysis via Retrieval Augmented Large Language Models
Oct 06, 2023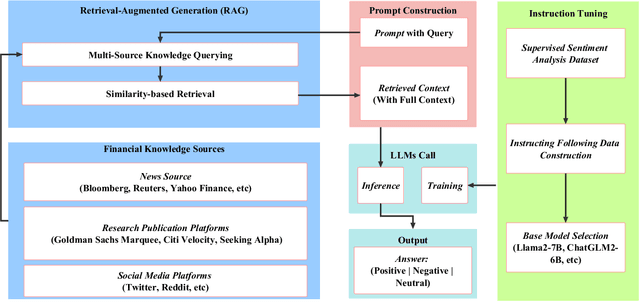

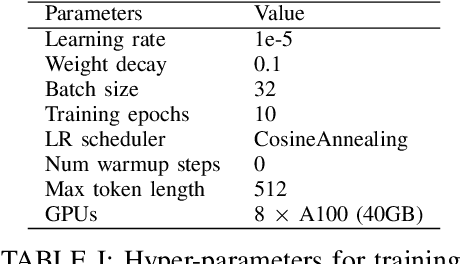
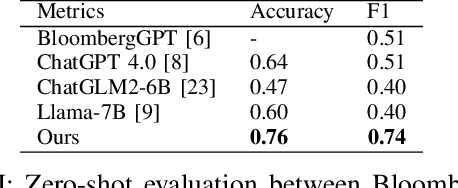
Financial sentiment analysis is critical for valuation and investment decision-making. Traditional NLP models, however, are limited by their parameter size and the scope of their training datasets, which hampers their generalization capabilities and effectiveness in this field. Recently, Large Language Models (LLMs) pre-trained on extensive corpora have demonstrated superior performance across various NLP tasks due to their commendable zero-shot abilities. Yet, directly applying LLMs to financial sentiment analysis presents challenges: The discrepancy between the pre-training objective of LLMs and predicting the sentiment label can compromise their predictive performance. Furthermore, the succinct nature of financial news, often devoid of sufficient context, can significantly diminish the reliability of LLMs' sentiment analysis. To address these challenges, we introduce a retrieval-augmented LLMs framework for financial sentiment analysis. This framework includes an instruction-tuned LLMs module, which ensures LLMs behave as predictors of sentiment labels, and a retrieval-augmentation module which retrieves additional context from reliable external sources. Benchmarked against traditional models and LLMs like ChatGPT and LLaMA, our approach achieves 15\% to 48\% performance gain in accuracy and F1 score.