 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Tokens Are What You Need In Thinking
May 23, 2025Modern reasoning models, such as OpenAI's o1 and DeepSeek-R1, exhibit impressive problem-solving capabilities but suffer from critical inefficiencies: high inference latency, excessive computational resource consumption, and a tendency toward overthinking -- generating verbose chains of thought (CoT) laden with redundant tokens that contribute minimally to the final answer. To address these issues, we propose Conditional Token Selection (CTS), a token-level compression framework with a flexible and variable compression ratio that identifies and preserves only the most essential tokens in CoT. CTS evaluates each token's contribution to deriving correct answers using conditional importance scoring, then trains models on compressed CoT. Extensive experiments demonstrate that CTS effectively compresses long CoT while maintaining strong reasoning performance. Notably, on the GPQA benchmark, Qwen2.5-14B-Instruct trained with CTS achieves a 9.1% accuracy improvement with 13.2% fewer reasoning tokens (13% training token reduction). Further reducing training tokens by 42% incurs only a marginal 5% accuracy drop while yielding a 75.8% reduction in reasoning tokens, highlighting the prevalence of redundancy in existing CoT.
NewsNet-SDF: Stochastic Discount Factor Estimation with Pretrained Language Model News Embeddings via Adversarial Networks
May 11, 2025Stochastic Discount Factor (SDF) models provide a unified framework for asset pricing and risk assessment, yet traditional formulations struggle to incorporate unstructured textual information. We introduce NewsNet-SDF, a novel deep learning framework that seamlessly integrates pretrained language model embeddings with financial time series through adversarial networks. Our multimodal architecture processes financial news using GTE-multilingual models, extracts temporal patterns from macroeconomic data via LSTM networks, and normalizes firm characteristics, fusing these heterogeneous information sources through an innovative adversarial training mechanism. Our dataset encompasses approximately 2.5 million news articles and 10,000 unique securities, addressing the computational challenges of processing and aligning text data with financial time series. Empirical evaluations on U.S. equity data (1980-2022) demonstrate NewsNet-SDF substantially outperforms alternatives with a Sharpe ratio of 2.80. The model shows a 471% improvement over CAPM, over 200% improvement versus traditional SDF implementations, and a 74% reduction in pricing errors compared to the Fama-French five-factor model. In comprehensive comparisons, our deep learning approach consistently outperforms traditional, modern, and other neural asset pricing models across all key metrics. Ablation studies confirm that text embeddings contribute significantly more to model performance than macroeconomic features, with news-derived principal components ranking among the most influential determinants of SDF dynamics. These results validate the effectiveness of our multimodal deep learning approach in integrating unstructured text with traditional financial data for more accurate asset pricing, providing new insights for digital intelligent decision-making in financial technology.
Fréchet Cumulative Covariance Net for Deep Nonlinear Sufficient Dimension Reduction with Random Objects
Feb 21, 2025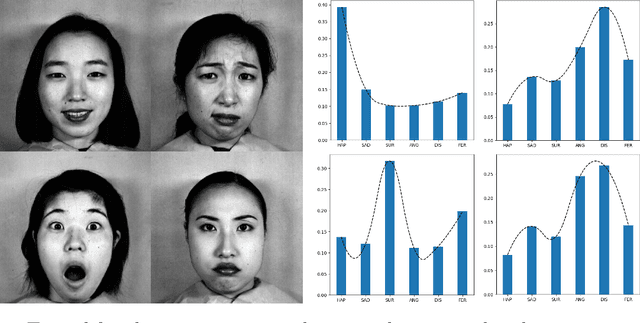
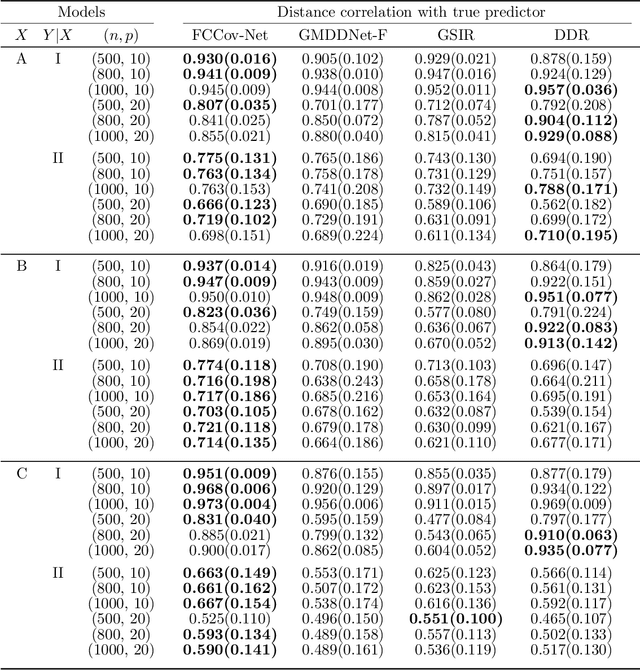
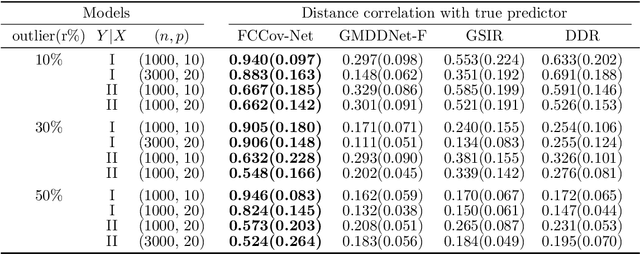
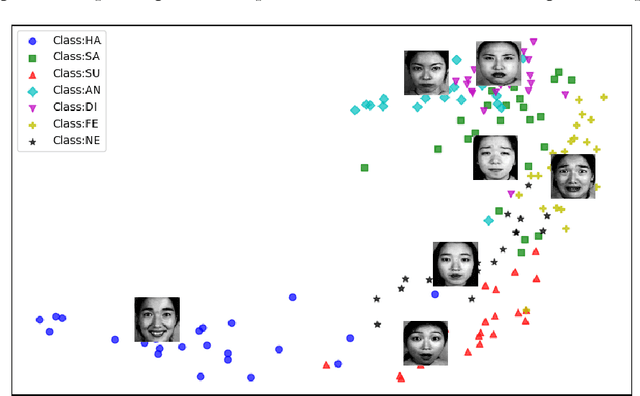
Nonlinear sufficient dimension reduction\citep{libing_generalSDR}, which constructs nonlinear low-dimensional representations to summarize essential features of high-dimensional data, is an important branch of representation learning. However, most existing methods are not applicable when the response variables are complex non-Euclidean random objects, which are frequently encountered in many recent statistical applications. In this paper, we introduce a new statistical dependence measure termed Fr\'echet Cumulative Covariance (FCCov) and develop a novel nonlinear SDR framework based on FCCov. Our approach is not only applicable to complex non-Euclidean data, but also exhibits robustness against outliers. We further incorporate Feedforward Neural Networks (FNNs) and Convolutional Neural Networks (CNNs) to estimate nonlinear sufficient directions in the sample level. Theoretically, we prove that our method with squared Frobenius norm regularization achieves unbiasedness at the $\sigma$-field level. Furthermore, we establish non-asymptotic convergence rates for our estimators based on FNNs and ResNet-type CNNs, which match the minimax rate of nonparametric regression up to logarithmic factors. Intensive simulation studies verify the performance of our methods in both Euclidean and non-Euclidean settings. We apply our method to facial expression recognition datasets and the results underscore more realistic and broader applicability of our proposal.
FinGPT: Enhancing Sentiment-Based Stock Movement Prediction with Dissemination-Aware and Context-Enriched LLMs
Dec 14, 2024



Financial sentiment analysis is crucial for understanding the influence of news on stock prices. Recently, large language models (LLMs) have been widely adopted for this purpose due to their advanced text analysis capabilities. However, these models often only consider the news content itself, ignoring its dissemination, which hampers accurate prediction of short-term stock movements. Additionally, current methods often lack sufficient contextual data and explicit instructions in their prompts, limiting LLMs' ability to interpret news. In this paper, we propose a data-driven approach that enhances LLM-powered sentiment-based stock movement predictions by incorporating news dissemination breadth, contextual data, and explicit instructions. We cluster recent company-related news to assess its reach and influence, enriching prompts with more specific data and precise instructions. This data is used to construct an instruction tuning dataset to fine-tune an LLM for predicting short-term stock price movements. Our experimental results show that our approach improves prediction accuracy by 8\% compared to existing methods.
FinRobot: An Open-Source AI Agent Platform for Financial Applications using Large Language Models
May 23, 2024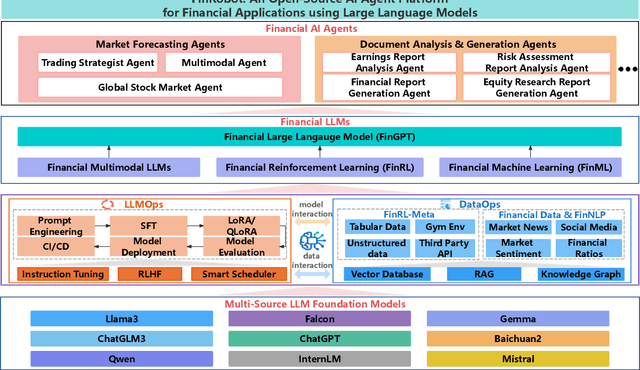
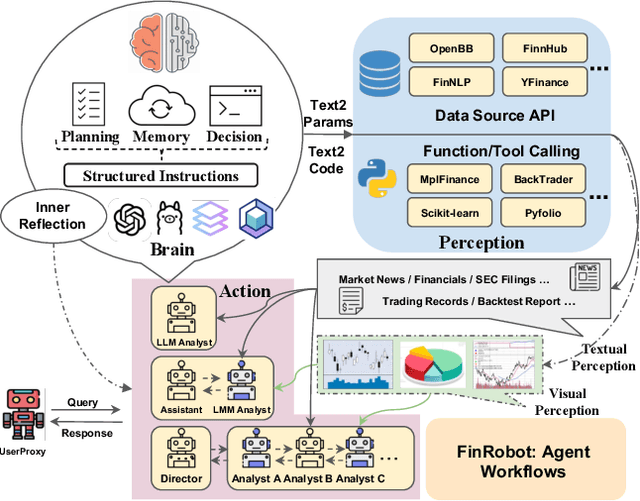
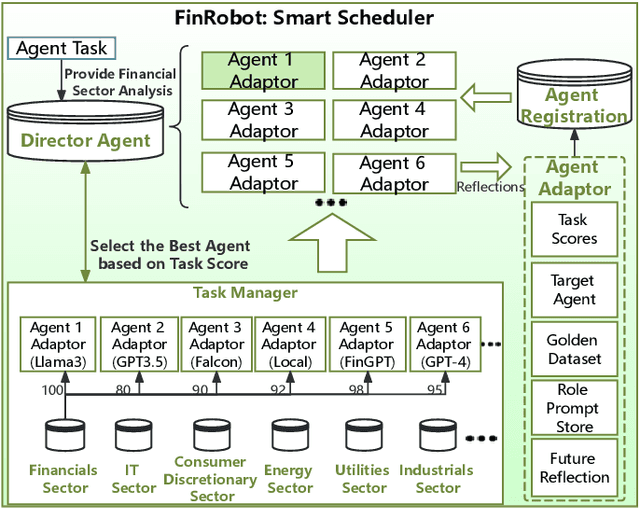

As financial institutions and professionals increasingly incorporate Large Language Models (LLMs) into their workflows, substantial barriers, including proprietary data and specialized knowledge, persist between the finance sector and the AI community. These challenges impede the AI community's ability to enhance financial tasks effectively. Acknowledging financial analysis's critical role, we aim to devise financial-specialized LLM-based toolchains and democratize access to them through open-source initiatives, promoting wider AI adoption in financial decision-making. In this paper, we introduce FinRobot, a novel open-source AI agent platform supporting multiple financially specialized AI agents, each powered by LLM. Specifically, the platform consists of four major layers: 1) the Financial AI Agents layer that formulates Financial Chain-of-Thought (CoT) by breaking sophisticated financial problems down into logical sequences; 2) the Financial LLM Algorithms layer dynamically configures appropriate model application strategies for specific tasks; 3) the LLMOps and DataOps layer produces accurate models by applying training/fine-tuning techniques and using task-relevant data; 4) the Multi-source LLM Foundation Models layer that integrates various LLMs and enables the above layers to access them directly. Finally, FinRobot provides hands-on for both professional-grade analysts and laypersons to utilize powerful AI techniques for advanced financial analysis. We open-source FinRobot at \url{https://github.com/AI4Finance-Foundation/FinRobot}.
FinGPT: Instruction Tuning Benchmark for Open-Source Large Language Models in Financial Datasets
Oct 07, 2023



In the swiftly expanding domain of Natural Language Processing (NLP), the potential of GPT-based models for the financial sector is increasingly evident. However, the integration of these models with financial datasets presents challenges, notably in determining their adeptness and relevance. This paper introduces a distinctive approach anchored in the Instruction Tuning paradigm for open-source large language models, specifically adapted for financial contexts. Through this methodology, we capitalize on the interoperability of open-source models, ensuring a seamless and transparent integration. We begin by explaining the Instruction Tuning paradigm, highlighting its effectiveness for immediate integration. The paper presents a benchmarking scheme designed for end-to-end training and testing, employing a cost-effective progression. Firstly, we assess basic competencies and fundamental tasks, such as Named Entity Recognition (NER) and sentiment analysis to enhance specialization. Next, we delve into a comprehensive model, executing multi-task operations by amalgamating all instructional tunings to examine versatility. Finally, we explore the zero-shot capabilities by earmarking unseen tasks and incorporating novel datasets to understand adaptability in uncharted terrains. Such a paradigm fortifies the principles of openness and reproducibility, laying a robust foundation for future investigations in open-source financial large language models (FinLLMs).
FinGPT: Open-Source Financial Large Language Models
Jun 09, 2023
Large language models (LLMs) have shown the potential of revolutionizing natural language processing tasks in diverse domains, sparking great interest in finance. Accessing high-quality financial data is the first challenge for financial LLMs (FinLLMs). While proprietary models like BloombergGPT have taken advantage of their unique data accumulation, such privileged access calls for an open-source alternative to democratize Internet-scale financial data. In this paper, we present an open-source large language model, FinGPT, for the finance sector. Unlike proprietary models, FinGPT takes a data-centric approach, providing researchers and practitioners with accessible and transparent resources to develop their FinLLMs. We highlight the importance of an automatic data curation pipeline and the lightweight low-rank adaptation technique in building FinGPT. Furthermore, we showcase several potential applications as stepping stones for users, such as robo-advising, algorithmic trading, and low-code development. Through collaborative efforts within the open-source AI4Finance community, FinGPT aims to stimulate innovation, democratize FinLLMs, and unlock new opportunities in open finance. Two associated code repos are \url{https://github.com/AI4Finance-Foundation/FinGPT} and \url{https://github.com/AI4Finance-Foundation/FinNLP}
Dynamic Datasets and Market Environments for Financial Reinforcement Learning
Apr 25, 2023



The financial market is a particularly challenging playground for deep reinforcement learning due to its unique feature of dynamic datasets. Building high-quality market environments for training financial reinforcement learning (FinRL) agents is difficult due to major factors such as the low signal-to-noise ratio of financial data, survivorship bias of historical data, and model overfitting. In this paper, we present FinRL-Meta, a data-centric and openly accessible library that processes dynamic datasets from real-world markets into gym-style market environments and has been actively maintained by the AI4Finance community. First, following a DataOps paradigm, we provide hundreds of market environments through an automatic data curation pipeline. Second, we provide homegrown examples and reproduce popular research papers as stepping stones for users to design new trading strategies. We also deploy the library on cloud platforms so that users can visualize their own results and assess the relative performance via community-wise competitions. Third, we provide dozens of Jupyter/Python demos organized into a curriculum and a documentation website to serve the rapidly growing community. The open-source codes for the data curation pipeline are available at https://github.com/AI4Finance-Foundation/FinRL-Meta
Nearest-Neighbor Sampling Based Conditional Independence Testing
Apr 09, 2023The conditional randomization test (CRT) was recently proposed to test whether two random variables X and Y are conditionally independent given random variables Z. The CRT assumes that the conditional distribution of X given Z is known under the null hypothesis and then it is compared to the distribution of the observed samples of the original data. The aim of this paper is to develop a novel alternative of CRT by using nearest-neighbor sampling without assuming the exact form of the distribution of X given Z. Specifically, we utilize the computationally efficient 1-nearest-neighbor to approximate the conditional distribution that encodes the null hypothesis. Then, theoretically, we show that the distribution of the generated samples is very close to the true conditional distribution in terms of total variation distance. Furthermore, we take the classifier-based conditional mutual information estimator as our test statistic. The test statistic as an empirical fundamental information theoretic quantity is able to well capture the conditional-dependence feature. We show that our proposed test is computationally very fast, while controlling type I and II errors quite well. Finally, we demonstrate the efficiency of our proposed test in both synthetic and real data analyses.
Deep Reinforcement Learning for Cryptocurrency Trading: Practical Approach to Address Backtest Overfitting
Sep 14, 2022
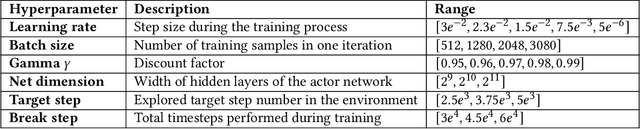
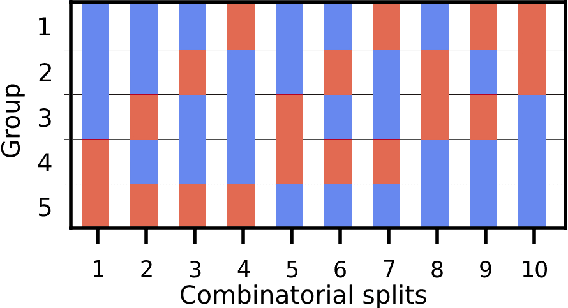
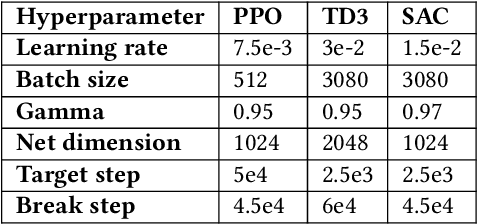
Designing profitable and reliable trading strategies is challenging in the highly volatile cryptocurrency market. Existing works applied deep reinforcement learning methods and optimistically reported increased profits in backtesting, which may suffer from the false positive issue due to overfitting. In this paper, we propose a practical approach to address backtest overfitting for cryptocurrency trading using deep reinforcement learning. First, we formulate the detection of backtest overfitting as a hypothesis test. Then, we train the DRL agents, estimate the probability of overfitting, and reject the overfitted agents, increasing the chance of good trading performance. Finally, on 10 cryptocurrencies over a testing period from 05/01/2022 to 06/27/2022 (during which the crypto market crashed two times), we show that the less overfitted deep reinforcement learning agents have a higher Sharpe ratio than that of more over-fitted agents, an equal weight strategy, and the S&P DBM Index (market benchmark), offering confidence in possible deployment to a real market.