 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYunjue Agent Tech Report: A Fully Reproducible, Zero-Start In-Situ Self-Evolving Agent System for Open-Ended Tasks
Jan 26, 2026Conventional agent systems often struggle in open-ended environments where task distributions continuously drift and external supervision is scarce. Their reliance on static toolsets or offline training lags behind these dynamics, leaving the system's capability boundaries rigid and unknown. To address this, we propose the In-Situ Self-Evolving paradigm. This approach treats sequential task interactions as a continuous stream of experience, enabling the system to distill short-term execution feedback into long-term, reusable capabilities without access to ground-truth labels. Within this framework, we identify tool evolution as the critical pathway for capability expansion, which provides verifiable, binary feedback signals. Within this framework, we develop Yunjue Agent, a system that iteratively synthesizes, optimizes, and reuses tools to navigate emerging challenges. To optimize evolutionary efficiency, we further introduce a Parallel Batch Evolution strategy. Empirical evaluations across five diverse benchmarks under a zero-start setting demonstrate significant performance gains over proprietary baselines. Additionally, complementary warm-start evaluations confirm that the accumulated general knowledge can be seamlessly transferred to novel domains. Finally, we propose a novel metric to monitor evolution convergence, serving as a function analogous to training loss in conventional optimization. We open-source our codebase, system traces, and evolved tools to facilitate future research in resilient, self-evolving intelligence.
Not All Tokens Are What You Need In Thinking
May 23, 2025Modern reasoning models, such as OpenAI's o1 and DeepSeek-R1, exhibit impressive problem-solving capabilities but suffer from critical inefficiencies: high inference latency, excessive computational resource consumption, and a tendency toward overthinking -- generating verbose chains of thought (CoT) laden with redundant tokens that contribute minimally to the final answer. To address these issues, we propose Conditional Token Selection (CTS), a token-level compression framework with a flexible and variable compression ratio that identifies and preserves only the most essential tokens in CoT. CTS evaluates each token's contribution to deriving correct answers using conditional importance scoring, then trains models on compressed CoT. Extensive experiments demonstrate that CTS effectively compresses long CoT while maintaining strong reasoning performance. Notably, on the GPQA benchmark, Qwen2.5-14B-Instruct trained with CTS achieves a 9.1% accuracy improvement with 13.2% fewer reasoning tokens (13% training token reduction). Further reducing training tokens by 42% incurs only a marginal 5% accuracy drop while yielding a 75.8% reduction in reasoning tokens, highlighting the prevalence of redundancy in existing CoT.
Long-Short Chain-of-Thought Mixture Supervised Fine-Tuning Eliciting Efficient Reasoning in Large Language Models
May 06, 2025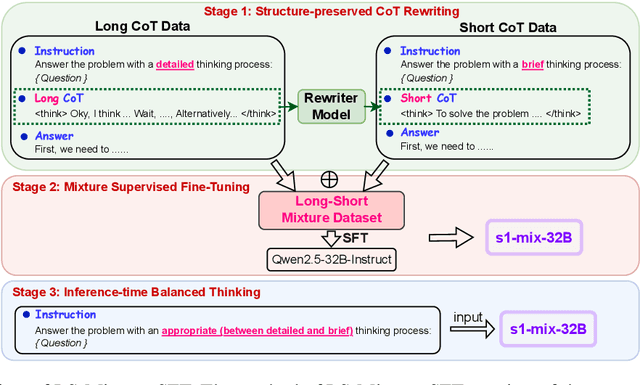
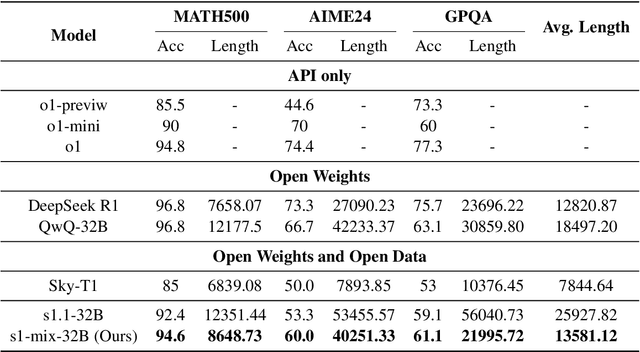
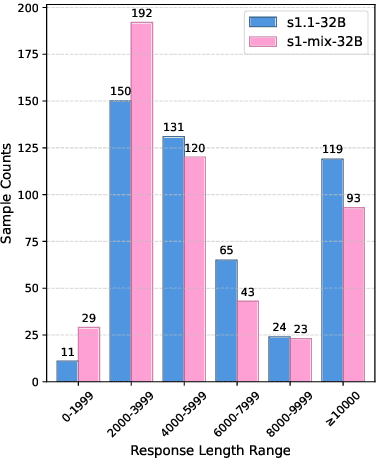
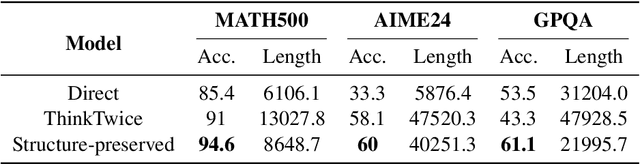
Recent advances in large language models have demonstrated that Supervised Fine-Tuning (SFT) with Chain-of-Thought (CoT) reasoning data distilled from large reasoning models (e.g., DeepSeek R1) can effectively transfer reasoning capabilities to non-reasoning models. However, models fine-tuned with this approach inherit the "overthinking" problem from teacher models, producing verbose and redundant reasoning chains during inference. To address this challenge, we propose \textbf{L}ong-\textbf{S}hort Chain-of-Thought \textbf{Mixture} \textbf{S}upervised \textbf{F}ine-\textbf{T}uning (\textbf{LS-Mixture SFT}), which combines long CoT reasoning dataset with their short counterparts obtained through structure-preserved rewriting. Our experiments demonstrate that models trained using the LS-Mixture SFT method, compared to those trained with direct SFT, achieved an average accuracy improvement of 2.3\% across various benchmarks while substantially reducing model response length by approximately 47.61\%. This work offers an approach to endow non-reasoning models with reasoning capabilities through supervised fine-tuning while avoiding the inherent overthinking problems inherited from teacher models, thereby enabling efficient reasoning in the fine-tuned models.
Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
Mar 08, 2023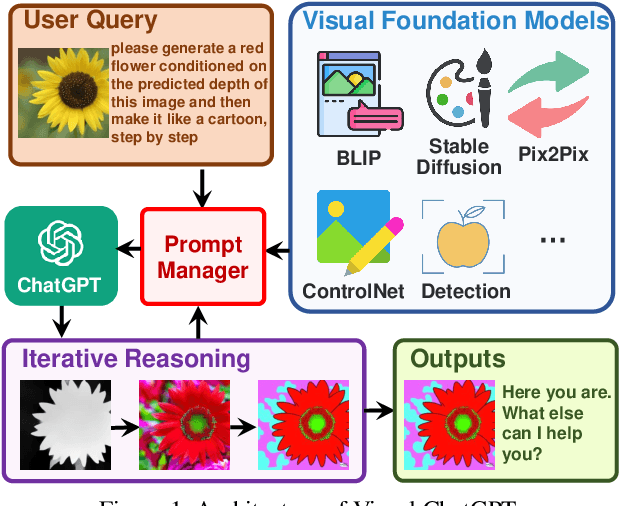
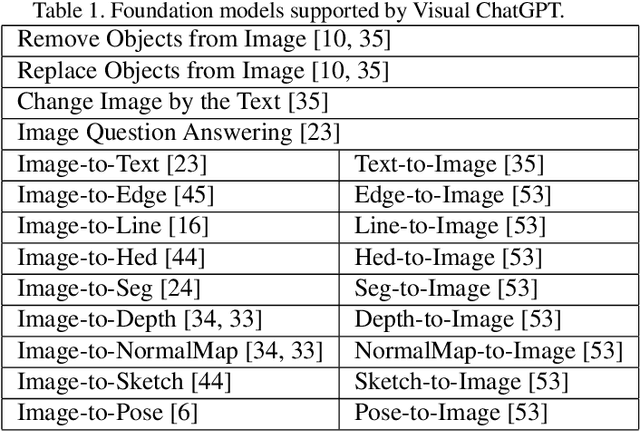
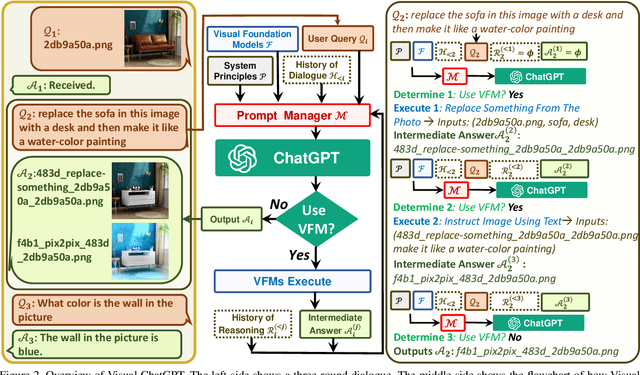
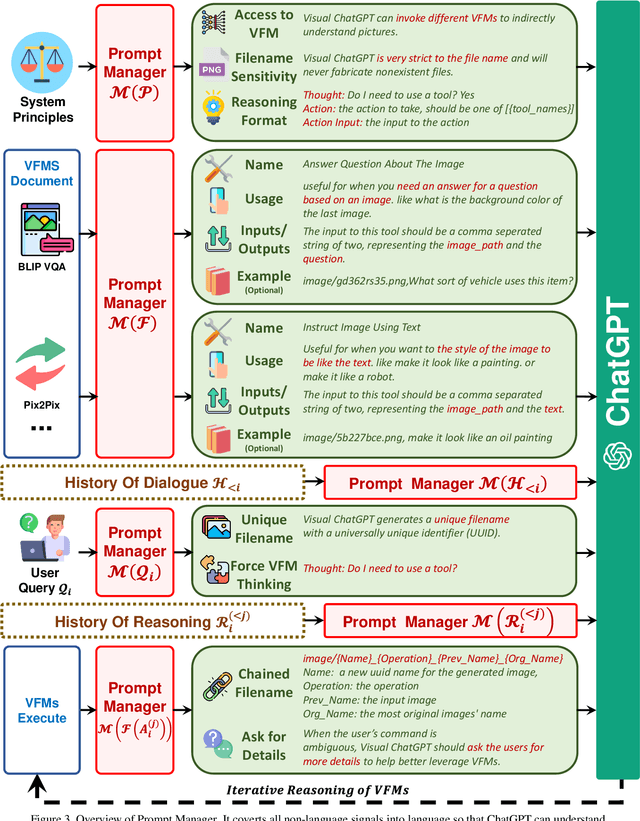
ChatGPT is attracting a cross-field interest as it provides a language interface with remarkable conversational competency and reasoning capabilities across many domains. However, since ChatGPT is trained with languages, it is currently not capable of processing or generating images from the visual world. At the same time, Visual Foundation Models, such as Visual Transformers or Stable Diffusion, although showing great visual understanding and generation capabilities, they are only experts on specific tasks with one-round fixed inputs and outputs. To this end, We build a system called \textbf{Visual ChatGPT}, incorporating different Visual Foundation Models, to enable the user to interact with ChatGPT by 1) sending and receiving not only languages but also images 2) providing complex visual questions or visual editing instructions that require the collaboration of multiple AI models with multi-steps. 3) providing feedback and asking for corrected results. We design a series of prompts to inject the visual model information into ChatGPT, considering models of multiple inputs/outputs and models that require visual feedback. Experiments show that Visual ChatGPT opens the door to investigating the visual roles of ChatGPT with the help of Visual Foundation Models. Our system is publicly available at \url{https://github.com/microsoft/visual-chatgpt}.
A Self-Paced Mixed Distillation Method for Non-Autoregressive Generation
May 23, 2022


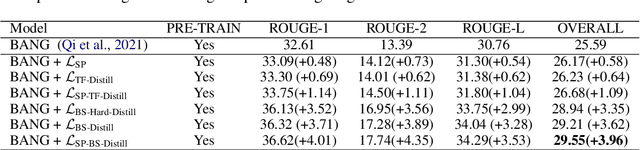
Non-Autoregressive generation is a sequence generation paradigm, which removes the dependency between target tokens. It could efficiently reduce the text generation latency with parallel decoding in place of token-by-token sequential decoding. However, due to the known multi-modality problem, Non-Autoregressive (NAR) models significantly under-perform Auto-regressive (AR) models on various language generation tasks. Among the NAR models, BANG is the first large-scale pre-training model on English un-labeled raw text corpus. It considers different generation paradigms as its pre-training tasks including Auto-regressive (AR), Non-Autoregressive (NAR), and semi-Non-Autoregressive (semi-NAR) information flow with multi-stream strategy. It achieves state-of-the-art performance without any distillation techniques. However, AR distillation has been shown to be a very effective solution for improving NAR performance. In this paper, we propose a novel self-paced mixed distillation method to further improve the generation quality of BANG. Firstly, we propose the mixed distillation strategy based on the AR stream knowledge. Secondly, we encourage the model to focus on the samples with the same modality by self-paced learning. The proposed self-paced mixed distillation algorithm improves the generation quality and has no influence on the inference latency. We carry out extensive experiments on summarization and question generation tasks to validate the effectiveness. To further illustrate the commercial value of our approach, we conduct experiments on three generation tasks in real-world advertisements applications. Experimental results on commercial data show the effectiveness of the proposed model. Compared with BANG, it achieves significant BLEU score improvement. On the other hand, compared with auto-regressive generation method, it achieves more than 7x speedup.
DialogVED: A Pre-trained Latent Variable Encoder-Decoder Model for Dialog Response Generation
Apr 27, 2022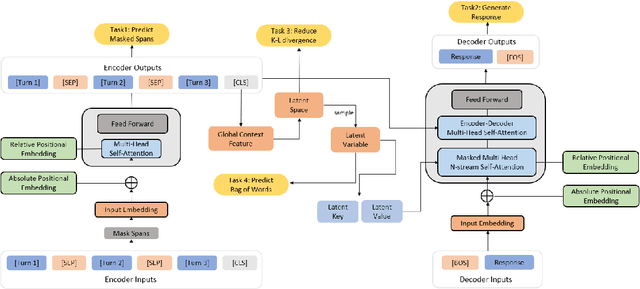
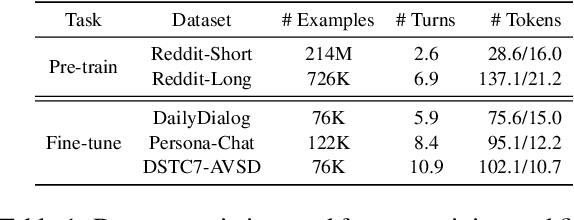
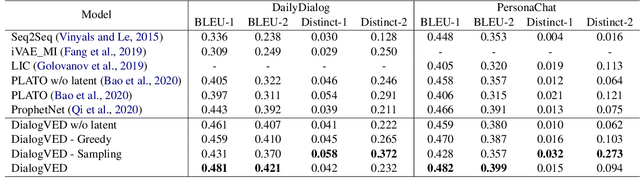
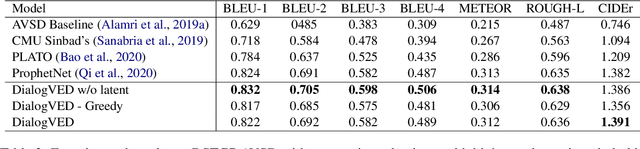
Dialog response generation in open domain is an important research topic where the main challenge is to generate relevant and diverse responses. In this paper, we propose a new dialog pre-training framework called DialogVED, which introduces continuous latent variables into the enhanced encoder-decoder pre-training framework to increase the relevance and diversity of responses. With the help of a large dialog corpus (Reddit), we pre-train the model using the following 4 tasks, used in training language models (LMs) and Variational Autoencoders (VAEs) literature: 1) masked language model; 2) response generation; 3) bag-of-words prediction; and 4) KL divergence reduction. We also add additional parameters to model the turn structure in dialogs to improve the performance of the pre-trained model. We conduct experiments on PersonaChat, DailyDialog, and DSTC7-AVSD benchmarks for response generation. Experimental results show that our model achieves the new state-of-the-art results on all these datasets.
CodeRetriever: Unimodal and Bimodal Contrastive Learning
Jan 26, 2022
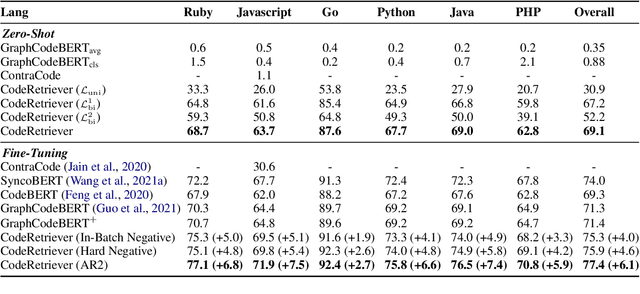
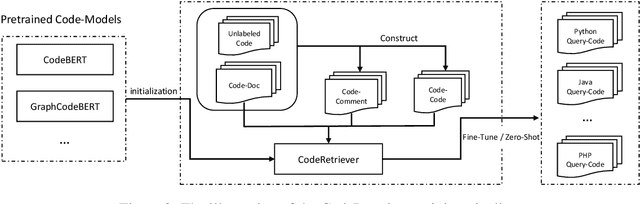
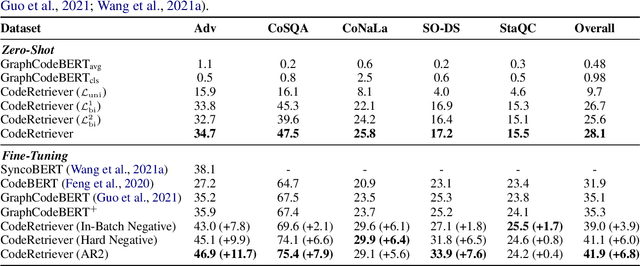
In this paper, we propose the CodeRetriever model, which combines the unimodal and bimodal contrastive learning to train function-level code semantic representations, specifically for the code search task. For unimodal contrastive learning, we design a semantic-guided method to build positive code pairs based on the documentation and function name. For bimodal contrastive learning, we leverage the documentation and in-line comments of code to build text-code pairs. Both contrastive objectives can fully leverage the large-scale code corpus for pre-training. Experimental results on several public benchmarks, (i.e., CodeSearch, CoSQA, etc.) demonstrate the effectiveness of CodeRetriever in the zero-shot setting. By fine-tuning with domain/language specified downstream data, CodeRetriever achieves the new state-of-the-art performance with significant improvement over existing code pre-trained models. We will make the code, model checkpoint, and constructed datasets publicly available.
Improving Sign Language Translation with Monolingual Data by Sign Back-Translation
May 26, 2021
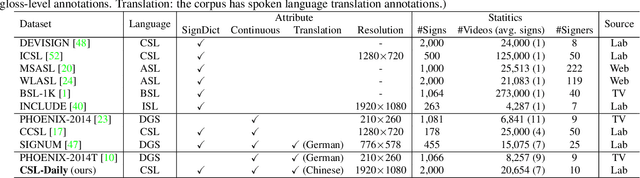
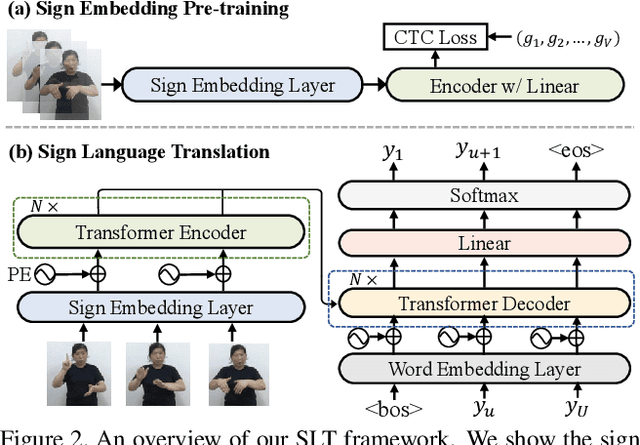
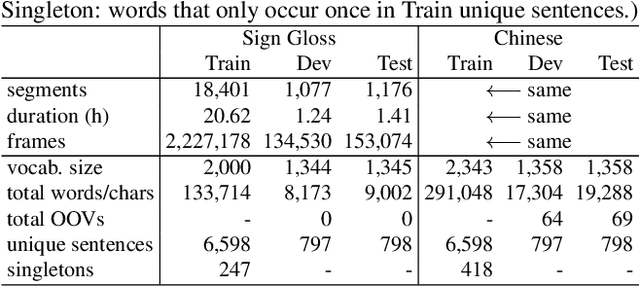
Despite existing pioneering works on sign language translation (SLT), there is a non-trivial obstacle, i.e., the limited quantity of parallel sign-text data. To tackle this parallel data bottleneck, we propose a sign back-translation (SignBT) approach, which incorporates massive spoken language texts into SLT training. With a text-to-gloss translation model, we first back-translate the monolingual text to its gloss sequence. Then, the paired sign sequence is generated by splicing pieces from an estimated gloss-to-sign bank at the feature level. Finally, the synthetic parallel data serves as a strong supplement for the end-to-end training of the encoder-decoder SLT framework. To promote the SLT research, we further contribute CSL-Daily, a large-scale continuous SLT dataset. It provides both spoken language translations and gloss-level annotations. The topic revolves around people's daily lives (e.g., travel, shopping, medical care), the most likely SLT application scenario. Extensive experimental results and analysis of SLT methods are reported on CSL-Daily. With the proposed sign back-translation method, we obtain a substantial improvement over previous state-of-the-art SLT methods.
EL-Attention: Memory Efficient Lossless Attention for Generation
May 11, 2021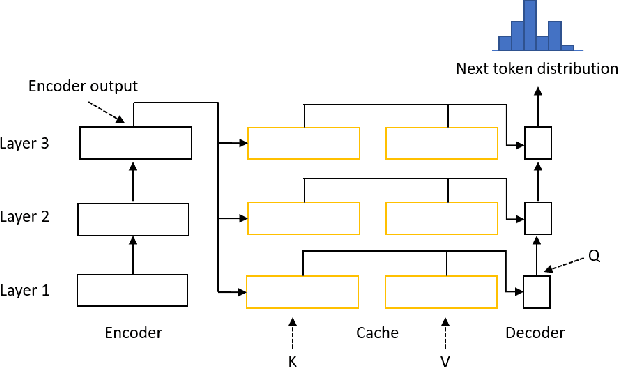
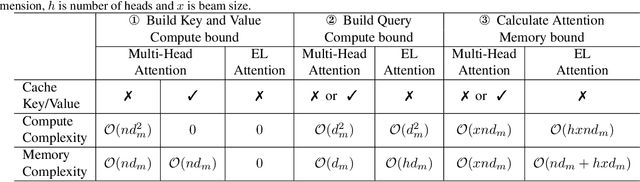
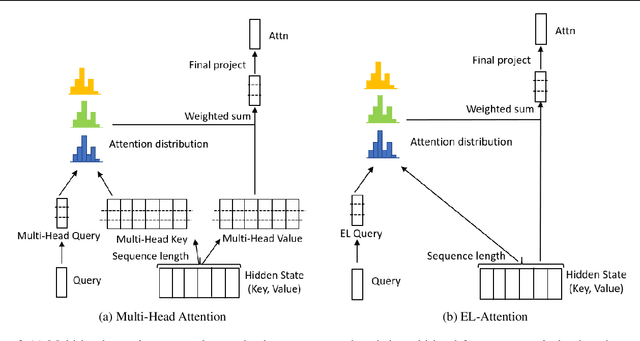
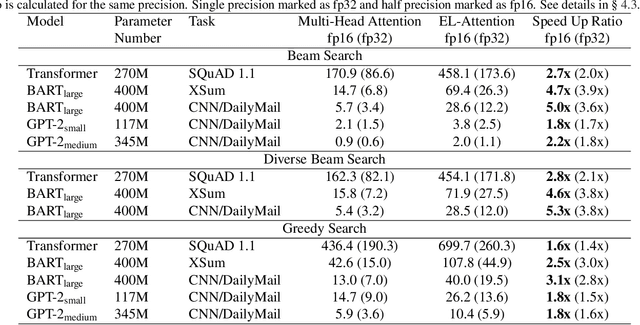
Transformer model with multi-head attention requires caching intermediate results for efficient inference in generation tasks. However, cache brings new memory-related costs and prevents leveraging larger batch size for faster speed. We propose memory-efficient lossless attention (called EL-attention) to address this issue. It avoids heavy operations for building multi-head keys and values, with no requirements of using cache. EL-attention constructs an ensemble of attention results by expanding query while keeping key and value shared. It produces the same result as multi-head attention with less GPU memory and faster inference speed. We conduct extensive experiments on Transformer, BART, and GPT-2 for summarization and question generation tasks. The results show EL-attention speeds up existing models by 1.6x to 5.3x without accuracy loss.
ProphetNet-X: Large-Scale Pre-training Models for English, Chinese, Multi-lingual, Dialog, and Code Generation
Apr 16, 2021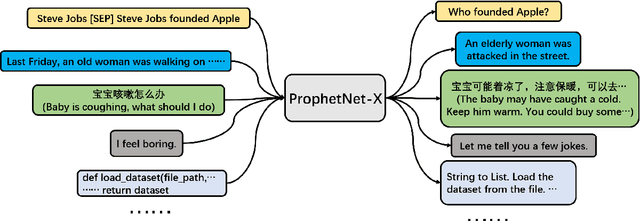

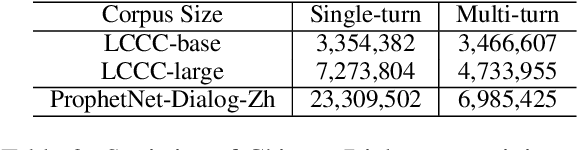
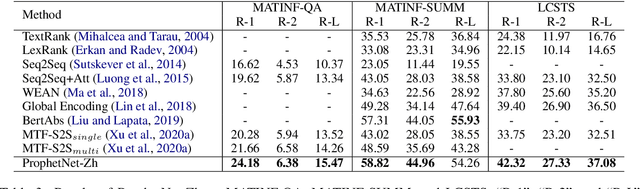
Now, the pre-training technique is ubiquitous in natural language processing field. ProphetNet is a pre-training based natural language generation method which shows powerful performance on English text summarization and question generation tasks. In this paper, we extend ProphetNet into other domains and languages, and present the ProphetNet family pre-training models, named ProphetNet-X, where X can be English, Chinese, Multi-lingual, and so on. We pre-train a cross-lingual generation model ProphetNet-Multi, a Chinese generation model ProphetNet-Zh, two open-domain dialog generation models ProphetNet-Dialog-En and ProphetNet-Dialog-Zh. And also, we provide a PLG (Programming Language Generation) model ProphetNet-Code to show the generation performance besides NLG (Natural Language Generation) tasks. In our experiments, ProphetNet-X models achieve new state-of-the-art performance on 10 benchmarks. All the models of ProphetNet-X share the same model structure, which allows users to easily switch between different models. We make the code and models publicly available, and we will keep updating more pre-training models and finetuning scripts. A video to introduce ProphetNet-X usage is also released.