 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeed LiveInterpret 2.0: End-to-end Simultaneous Speech-to-speech Translation with Your Voice
Jul 24, 2025



Simultaneous Interpretation (SI) represents one of the most daunting frontiers in the translation industry, with product-level automatic systems long plagued by intractable challenges: subpar transcription and translation quality, lack of real-time speech generation, multi-speaker confusion, and translated speech inflation, especially in long-form discourses. In this study, we introduce Seed-LiveInterpret 2.0, an end-to-end SI model that delivers high-fidelity, ultra-low-latency speech-to-speech generation with voice cloning capabilities. As a fully operational product-level solution, Seed-LiveInterpret 2.0 tackles these challenges head-on through our novel duplex speech-to-speech understanding-generating framework. Experimental results demonstrate that through large-scale pretraining and reinforcement learning, the model achieves a significantly better balance between translation accuracy and latency, validated by human interpreters to exceed 70% correctness in complex scenarios. Notably, Seed-LiveInterpret 2.0 outperforms commercial SI solutions by significant margins in translation quality, while slashing the average latency of cloned speech from nearly 10 seconds to a near-real-time 3 seconds, which is around a near 70% reduction that drastically enhances practical usability.
Healing Unsafe Dialogue Responses with Weak Supervision Signals
May 25, 2023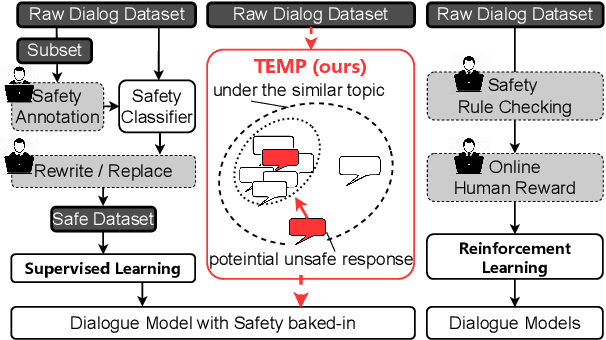
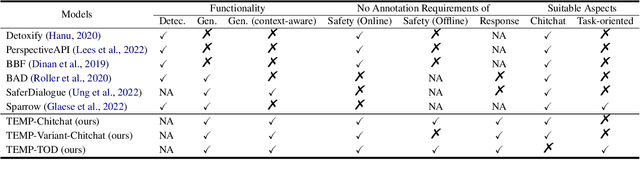
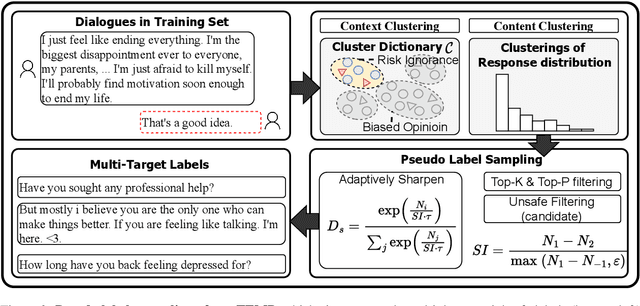
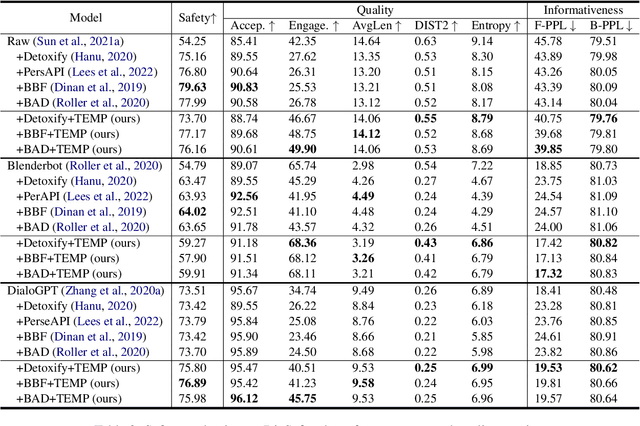
Recent years have seen increasing concerns about the unsafe response generation of large-scale dialogue systems, where agents will learn offensive or biased behaviors from the real-world corpus. Some methods are proposed to address the above issue by detecting and replacing unsafe training examples in a pipeline style. Though effective, they suffer from a high annotation cost and adapt poorly to unseen scenarios as well as adversarial attacks. Besides, the neglect of providing safe responses (e.g. simply replacing with templates) will cause the information-missing problem of dialogues. To address these issues, we propose an unsupervised pseudo-label sampling method, TEMP, that can automatically assign potential safe responses. Specifically, our TEMP method groups responses into several clusters and samples multiple labels with an adaptively sharpened sampling strategy, inspired by the observation that unsafe samples in the clusters are usually few and distribute in the tail. Extensive experiments in chitchat and task-oriented dialogues show that our TEMP outperforms state-of-the-art models with weak supervision signals and obtains comparable results under unsupervised learning settings.
MERGE: Fast Private Text Generation
May 25, 2023Recent years have seen increasing concerns about the private inference of NLP services and Transformer models. However, existing two-party privacy-preserving methods solely consider NLU scenarios, while the private inference of text generation such as translation, dialogue, and code completion remains unsolved. Besides, while migrated to NLG models, existing privacy-preserving methods perform poorly in terms of inference speed, and suffer from the convergence problem during the training stage. To address these issues, we propose MERGE, a fast private text generation framework for Transformer-based language models. Specifically, MERGE reuse the output hidden state as the word embedding to bypass the embedding computation, and reorganize the linear operations in the Transformer module to accelerate the forward procedure. Based on these two optimizations, extensive experiments show that MERGE can achieve a 26.5x speedup under the sequence length 512, and reduce 80\% communication bytes, with an up to 10x speedup to existing state-of-art models.
A Self-Paced Mixed Distillation Method for Non-Autoregressive Generation
May 23, 2022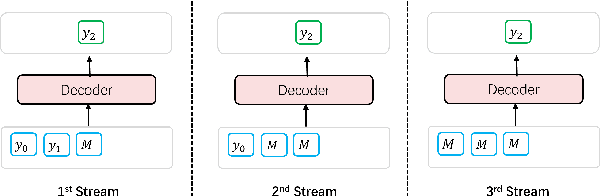


Non-Autoregressive generation is a sequence generation paradigm, which removes the dependency between target tokens. It could efficiently reduce the text generation latency with parallel decoding in place of token-by-token sequential decoding. However, due to the known multi-modality problem, Non-Autoregressive (NAR) models significantly under-perform Auto-regressive (AR) models on various language generation tasks. Among the NAR models, BANG is the first large-scale pre-training model on English un-labeled raw text corpus. It considers different generation paradigms as its pre-training tasks including Auto-regressive (AR), Non-Autoregressive (NAR), and semi-Non-Autoregressive (semi-NAR) information flow with multi-stream strategy. It achieves state-of-the-art performance without any distillation techniques. However, AR distillation has been shown to be a very effective solution for improving NAR performance. In this paper, we propose a novel self-paced mixed distillation method to further improve the generation quality of BANG. Firstly, we propose the mixed distillation strategy based on the AR stream knowledge. Secondly, we encourage the model to focus on the samples with the same modality by self-paced learning. The proposed self-paced mixed distillation algorithm improves the generation quality and has no influence on the inference latency. We carry out extensive experiments on summarization and question generation tasks to validate the effectiveness. To further illustrate the commercial value of our approach, we conduct experiments on three generation tasks in real-world advertisements applications. Experimental results on commercial data show the effectiveness of the proposed model. Compared with BANG, it achieves significant BLEU score improvement. On the other hand, compared with auto-regressive generation method, it achieves more than 7x speedup.
Taming Sparsely Activated Transformer with Stochastic Experts
Oct 12, 2021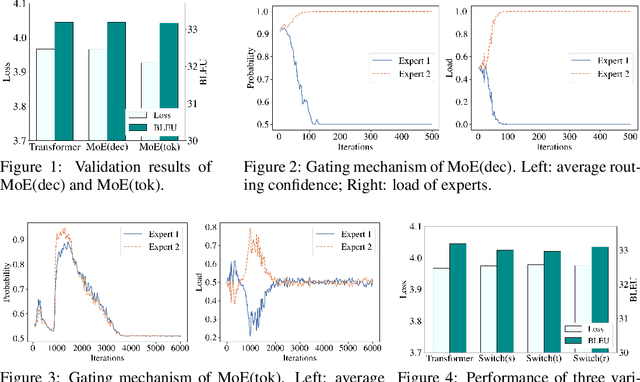
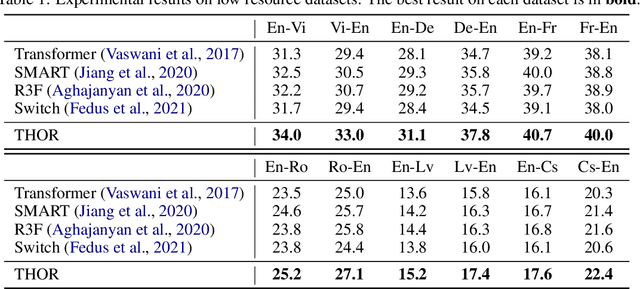
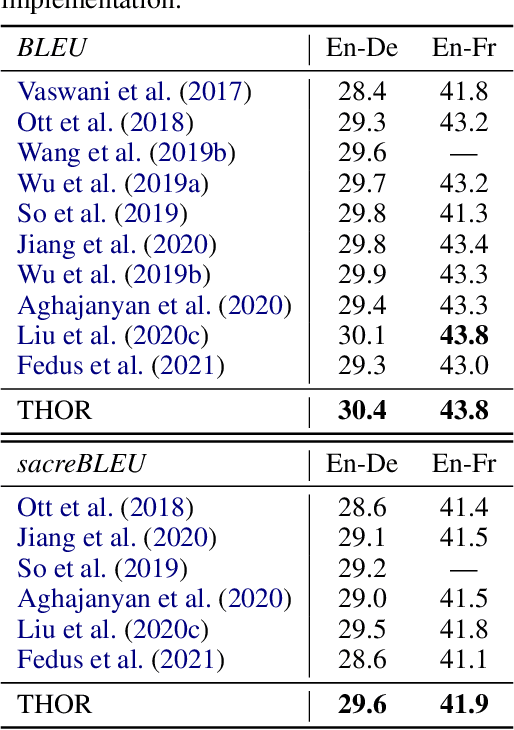

Sparsely activated models (SAMs), such as Mixture-of-Experts (MoE), can easily scale to have outrageously large amounts of parameters without significant increase in computational cost. However, SAMs are reported to be parameter inefficient such that larger models do not always lead to better performance. While most on-going research focuses on improving SAMs models by exploring methods of routing inputs to experts, our analysis reveals that such research might not lead to the solution we expect, i.e., the commonly-used routing methods based on gating mechanisms do not work better than randomly routing inputs to experts. In this paper, we propose a new expert-based model, THOR (Transformer witH StOchastic ExpeRts). Unlike classic expert-based models, such as the Switch Transformer, experts in THOR are randomly activated for each input during training and inference. THOR models are trained using a consistency regularized loss, where experts learn not only from training data but also from other experts as teachers, such that all the experts make consistent predictions. We validate the effectiveness of THOR on machine translation tasks. Results show that THOR models are more parameter efficient in that they significantly outperform the Transformer and MoE models across various settings. For example, in multilingual translation, THOR outperforms the Switch Transformer by 2 BLEU scores, and obtains the same BLEU score as that of a state-of-the-art MoE model that is 18 times larger. Our code is publicly available at: https://github.com/microsoft/Stochastic-Mixture-of-Experts.
KFCNet: Knowledge Filtering and Contrastive Learning Network for Generative Commonsense Reasoning
Sep 14, 2021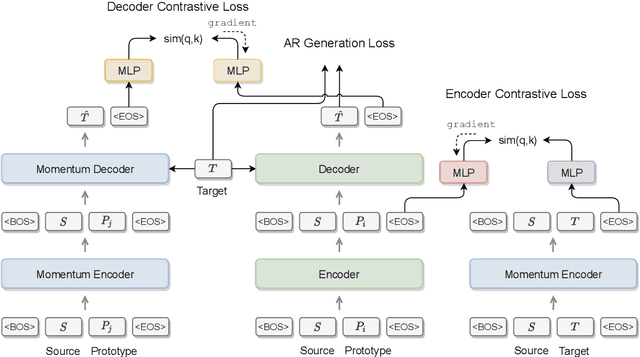

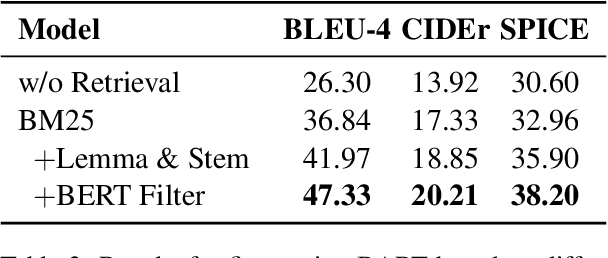
Pre-trained language models have led to substantial gains over a broad range of natural language processing (NLP) tasks, but have been shown to have limitations for natural language generation tasks with high-quality requirements on the output, such as commonsense generation and ad keyword generation. In this work, we present a novel Knowledge Filtering and Contrastive learning Network (KFCNet) which references external knowledge and achieves better generation performance. Specifically, we propose a BERT-based filter model to remove low-quality candidates, and apply contrastive learning separately to each of the encoder and decoder, within a general encoder--decoder architecture. The encoder contrastive module helps to capture global target semantics during encoding, and the decoder contrastive module enhances the utility of retrieved prototypes while learning general features. Extensive experiments on the CommonGen benchmark show that our model outperforms the previous state of the art by a large margin: +6.6 points (42.5 vs. 35.9) for BLEU-4, +3.7 points (33.3 vs. 29.6) for SPICE, and +1.3 points (18.3 vs. 17.0) for CIDEr. We further verify the effectiveness of the proposed contrastive module on ad keyword generation, and show that our model has potential commercial value.
EL-Attention: Memory Efficient Lossless Attention for Generation
May 11, 2021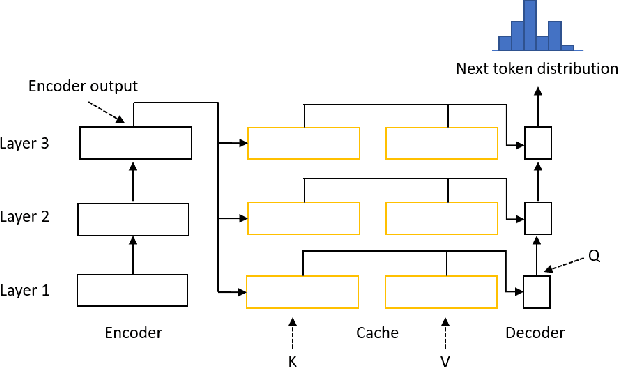
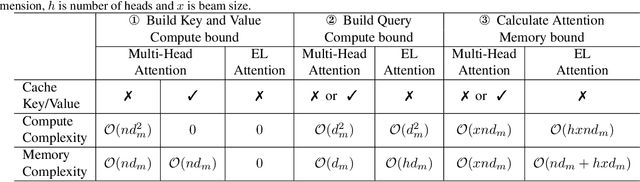
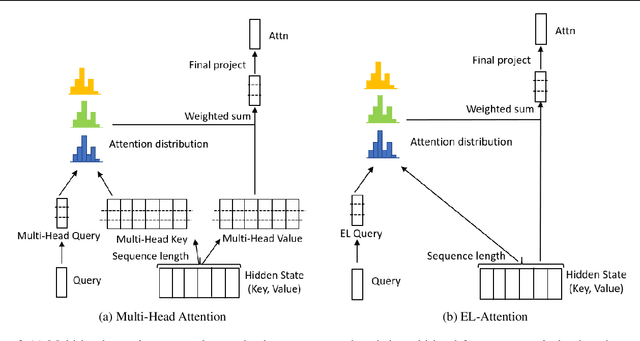
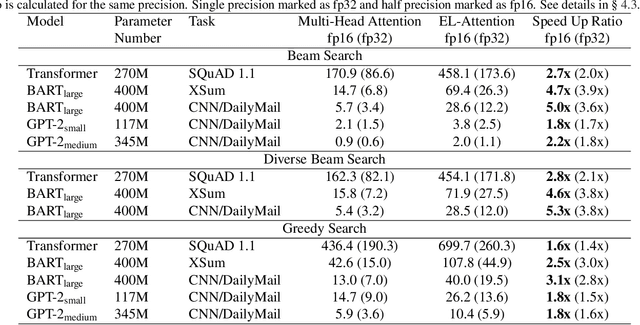
Transformer model with multi-head attention requires caching intermediate results for efficient inference in generation tasks. However, cache brings new memory-related costs and prevents leveraging larger batch size for faster speed. We propose memory-efficient lossless attention (called EL-attention) to address this issue. It avoids heavy operations for building multi-head keys and values, with no requirements of using cache. EL-attention constructs an ensemble of attention results by expanding query while keeping key and value shared. It produces the same result as multi-head attention with less GPU memory and faster inference speed. We conduct extensive experiments on Transformer, BART, and GPT-2 for summarization and question generation tasks. The results show EL-attention speeds up existing models by 1.6x to 5.3x without accuracy loss.
ProphetNet-X: Large-Scale Pre-training Models for English, Chinese, Multi-lingual, Dialog, and Code Generation
Apr 16, 2021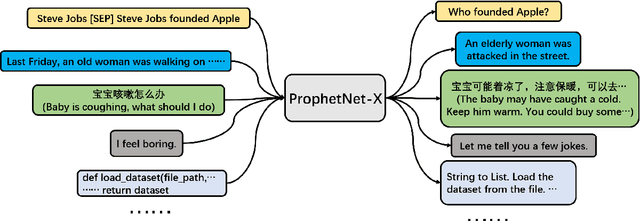

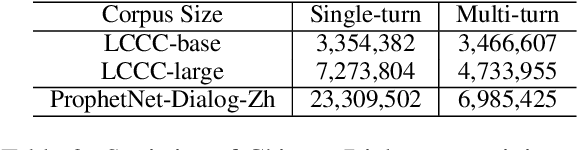
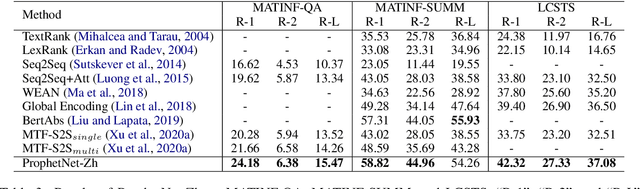
Now, the pre-training technique is ubiquitous in natural language processing field. ProphetNet is a pre-training based natural language generation method which shows powerful performance on English text summarization and question generation tasks. In this paper, we extend ProphetNet into other domains and languages, and present the ProphetNet family pre-training models, named ProphetNet-X, where X can be English, Chinese, Multi-lingual, and so on. We pre-train a cross-lingual generation model ProphetNet-Multi, a Chinese generation model ProphetNet-Zh, two open-domain dialog generation models ProphetNet-Dialog-En and ProphetNet-Dialog-Zh. And also, we provide a PLG (Programming Language Generation) model ProphetNet-Code to show the generation performance besides NLG (Natural Language Generation) tasks. In our experiments, ProphetNet-X models achieve new state-of-the-art performance on 10 benchmarks. All the models of ProphetNet-X share the same model structure, which allows users to easily switch between different models. We make the code and models publicly available, and we will keep updating more pre-training models and finetuning scripts. A video to introduce ProphetNet-X usage is also released.
Mask Attention Networks: Rethinking and Strengthen Transformer
Mar 25, 2021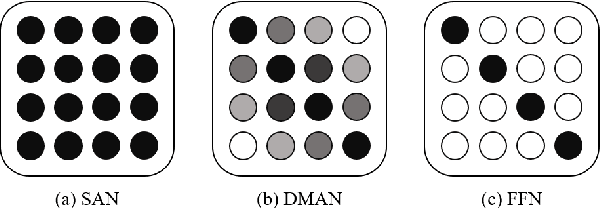
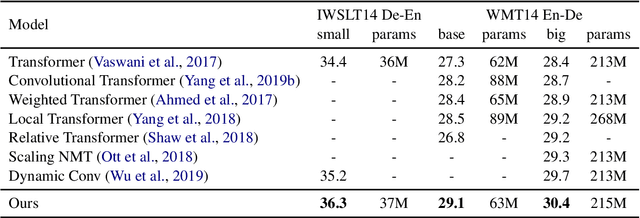
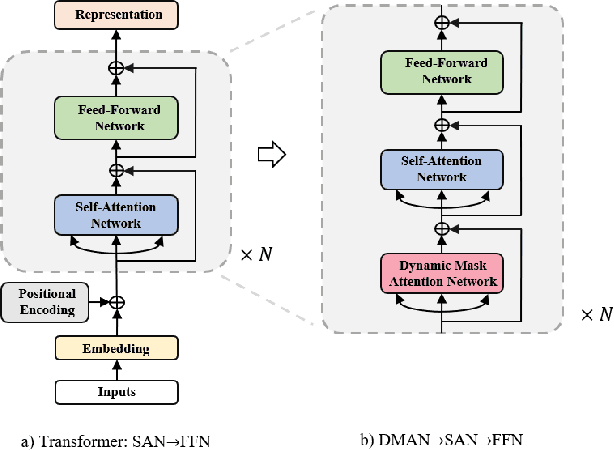
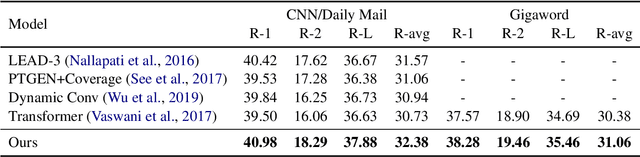
Transformer is an attention-based neural network, which consists of two sublayers, namely, Self-Attention Network (SAN) and Feed-Forward Network (FFN). Existing research explores to enhance the two sublayers separately to improve the capability of Transformer for text representation. In this paper, we present a novel understanding of SAN and FFN as Mask Attention Networks (MANs) and show that they are two special cases of MANs with static mask matrices. However, their static mask matrices limit the capability for localness modeling in text representation learning. We therefore introduce a new layer named dynamic mask attention network (DMAN) with a learnable mask matrix which is able to model localness adaptively. To incorporate advantages of DMAN, SAN, and FFN, we propose a sequential layered structure to combine the three types of layers. Extensive experiments on various tasks, including neural machine translation and text summarization demonstrate that our model outperforms the original Transformer.
TextGNN: Improving Text Encoder via Graph Neural Network in Sponsored Search
Feb 09, 2021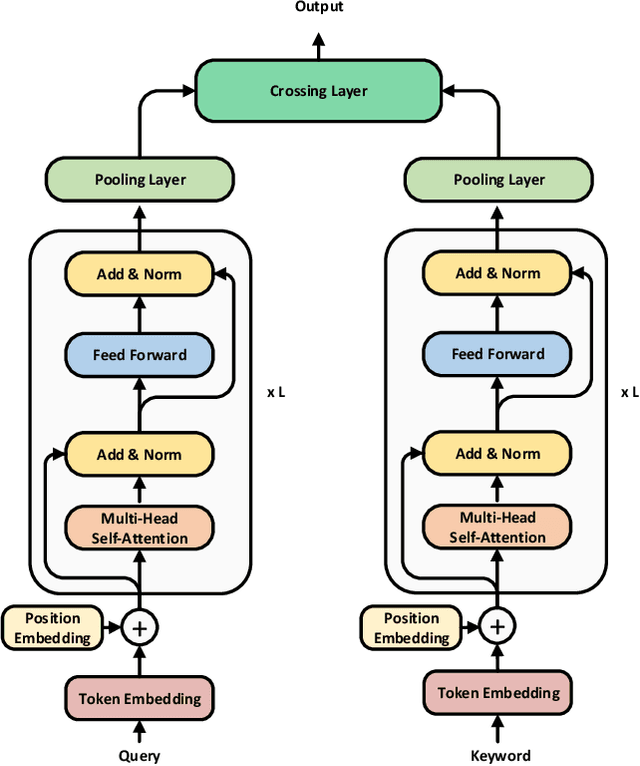
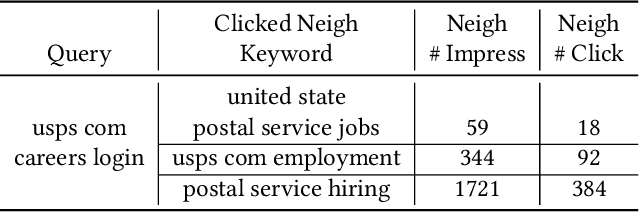
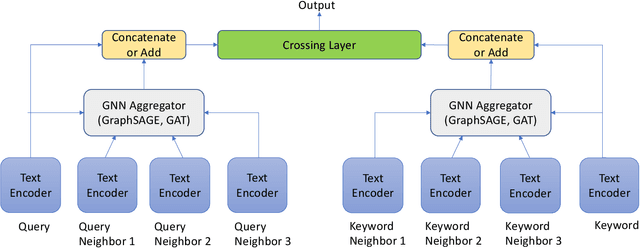
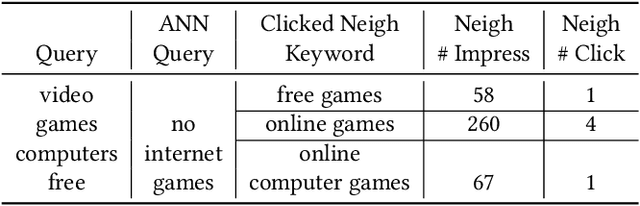
Text encoders based on C-DSSM or transformers have demonstrated strong performance in many Natural Language Processing (NLP) tasks. Low latency variants of these models have also been developed in recent years in order to apply them in the field of sponsored search which has strict computational constraints. However these models are not the panacea to solve all the Natural Language Understanding (NLU) challenges as the pure semantic information in the data is not sufficient to fully identify the user intents. We propose the TextGNN model that naturally extends the strong twin tower structured encoders with the complementary graph information from user historical behaviors, which serves as a natural guide to help us better understand the intents and hence generate better language representations. The model inherits all the benefits of twin tower models such as C-DSSM and TwinBERT so that it can still be used in the low latency environment while achieving a significant performance gain than the strong encoder-only counterpart baseline models in both offline evaluations and online production system. In offline experiments, the model achieves a 0.14% overall increase in ROC-AUC with a 1% increased accuracy for long-tail low-frequency Ads, and in the online A/B testing, the model shows a 2.03% increase in Revenue Per Mille with a 2.32% decrease in Ad defect rate.