 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Outlier Rectification via Optimal Transport
Mar 21, 2024



In this paper, we propose a novel conceptual framework to detect outliers using optimal transport with a concave cost function. Conventional outlier detection approaches typically use a two-stage procedure: first, outliers are detected and removed, and then estimation is performed on the cleaned data. However, this approach does not inform outlier removal with the estimation task, leaving room for improvement. To address this limitation, we propose an automatic outlier rectification mechanism that integrates rectification and estimation within a joint optimization framework. We take the first step to utilize an optimal transport distance with a concave cost function to construct a rectification set in the space of probability distributions. Then, we select the best distribution within the rectification set to perform the estimation task. Notably, the concave cost function we introduced in this paper is the key to making our estimator effectively identify the outlier during the optimization process. We discuss the fundamental differences between our estimator and optimal transport-based distributionally robust optimization estimator. finally, we demonstrate the effectiveness and superiority of our approach over conventional approaches in extensive simulation and empirical analyses for mean estimation, least absolute regression, and the fitting of option implied volatility surfaces.
Deep Learning Statistical Arbitrage
Jun 08, 2021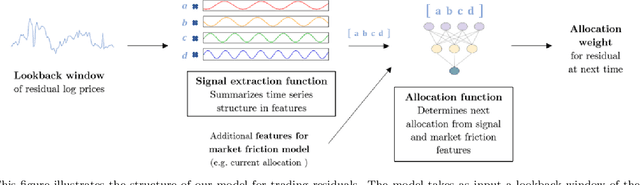
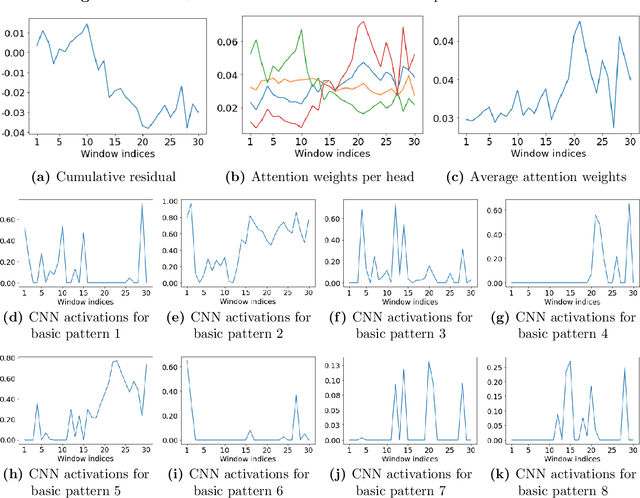
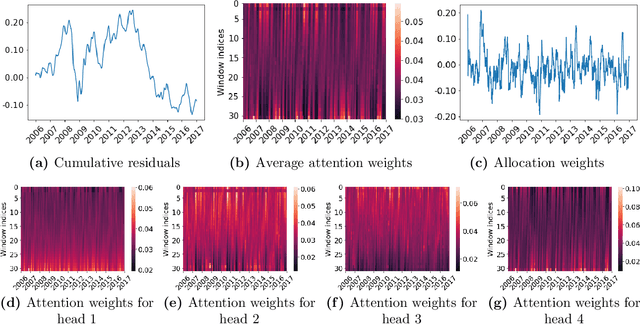
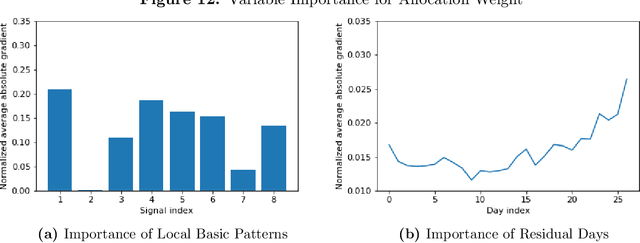
Statistical arbitrage identifies and exploits temporal price differences between similar assets. We propose a unifying conceptual framework for statistical arbitrage and develop a novel deep learning solution, which finds commonality and time-series patterns from large panels in a data-driven and flexible way. First, we construct arbitrage portfolios of similar assets as residual portfolios from conditional latent asset pricing factors. Second, we extract the time series signals of these residual portfolios with one of the most powerful machine learning time-series solutions, a convolutional transformer. Last, we use these signals to form an optimal trading policy, that maximizes risk-adjusted returns under constraints. We conduct a comprehensive empirical comparison study with daily large cap U.S. stocks. Our optimal trading strategy obtains a consistently high out-of-sample Sharpe ratio and substantially outperforms all benchmark approaches. It is orthogonal to common risk factors, and exploits asymmetric local trend and reversion patterns. Our strategies remain profitable after taking into account trading frictions and costs. Our findings suggest a high compensation for arbitrageurs to enforce the law of one price.
Time-Series Imputation with Wasserstein Interpolation for Optimal Look-Ahead-Bias and Variance Tradeoff
Feb 25, 2021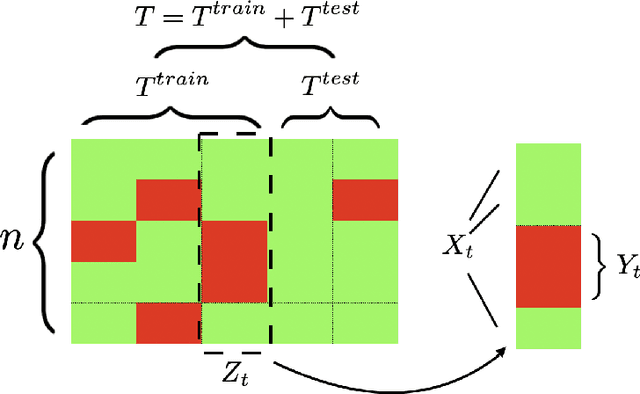
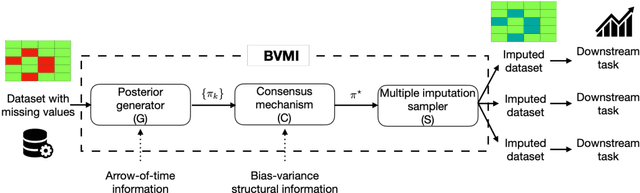
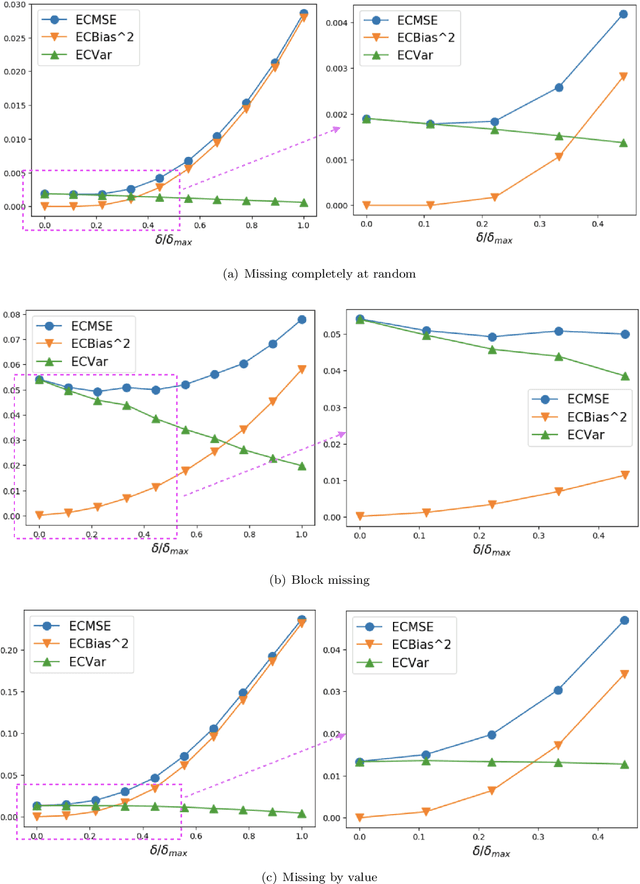
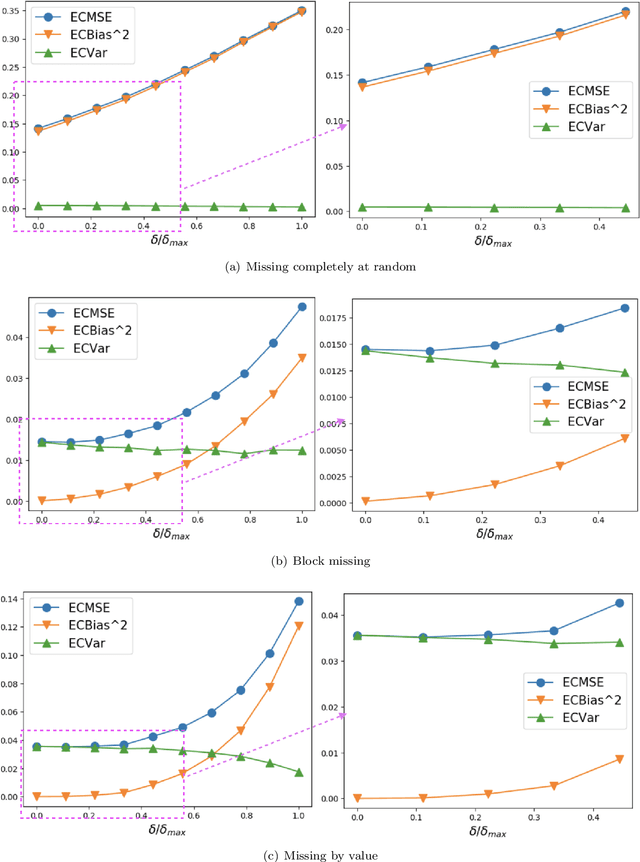
Missing time-series data is a prevalent practical problem. Imputation methods in time-series data often are applied to the full panel data with the purpose of training a model for a downstream out-of-sample task. For example, in finance, imputation of missing returns may be applied prior to training a portfolio optimization model. Unfortunately, this practice may result in a look-ahead-bias in the future performance on the downstream task. There is an inherent trade-off between the look-ahead-bias of using the full data set for imputation and the larger variance in the imputation from using only the training data. By connecting layers of information revealed in time, we propose a Bayesian posterior consensus distribution which optimally controls the variance and look-ahead-bias trade-off in the imputation. We demonstrate the benefit of our methodology both in synthetic and real financial data.
TextGNN: Improving Text Encoder via Graph Neural Network in Sponsored Search
Feb 09, 2021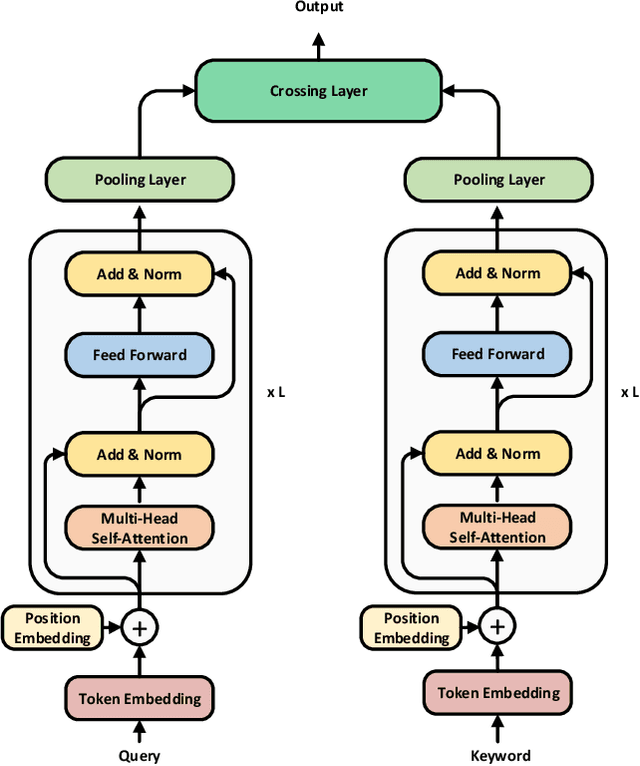
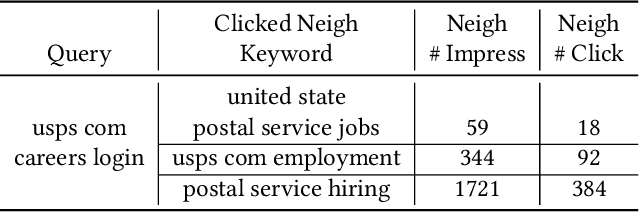
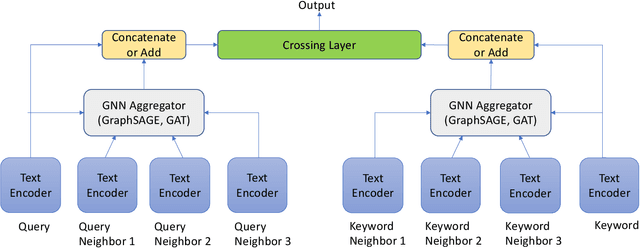
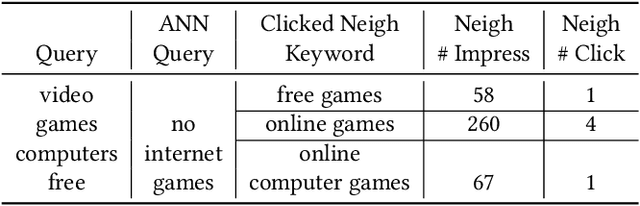
Text encoders based on C-DSSM or transformers have demonstrated strong performance in many Natural Language Processing (NLP) tasks. Low latency variants of these models have also been developed in recent years in order to apply them in the field of sponsored search which has strict computational constraints. However these models are not the panacea to solve all the Natural Language Understanding (NLU) challenges as the pure semantic information in the data is not sufficient to fully identify the user intents. We propose the TextGNN model that naturally extends the strong twin tower structured encoders with the complementary graph information from user historical behaviors, which serves as a natural guide to help us better understand the intents and hence generate better language representations. The model inherits all the benefits of twin tower models such as C-DSSM and TwinBERT so that it can still be used in the low latency environment while achieving a significant performance gain than the strong encoder-only counterpart baseline models in both offline evaluations and online production system. In offline experiments, the model achieves a 0.14% overall increase in ROC-AUC with a 1% increased accuracy for long-tail low-frequency Ads, and in the online A/B testing, the model shows a 2.03% increase in Revenue Per Mille with a 2.32% decrease in Ad defect rate.