 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdsGNN: Behavior-Graph Augmented Relevance Modeling in Sponsored Search
Apr 25, 2021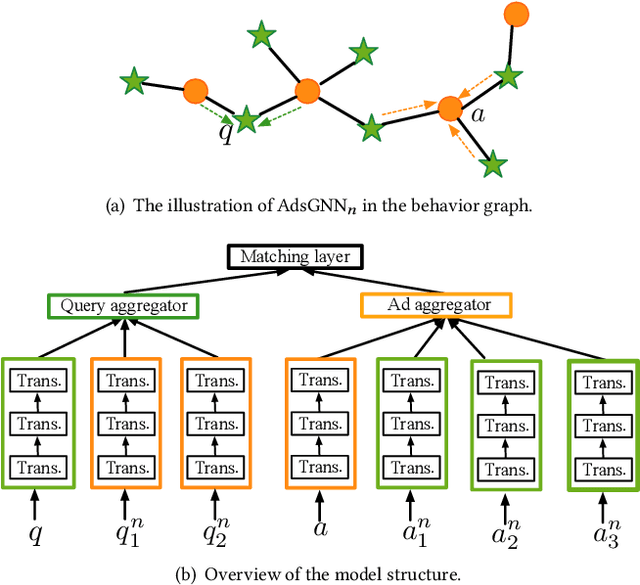

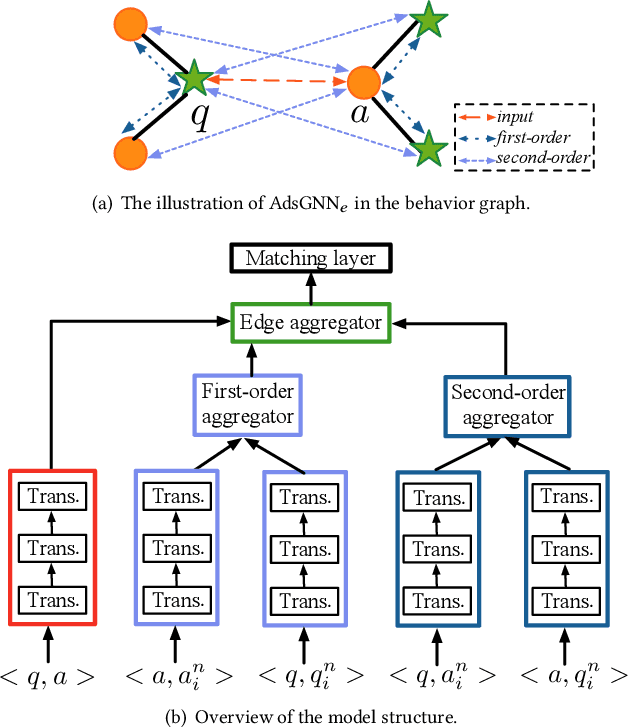
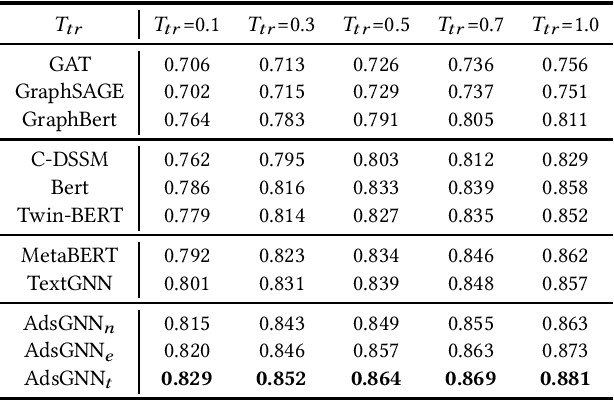
Sponsored search ads appear next to search results when people look for products and services on search engines. In recent years, they have become one of the most lucrative channels for marketing. As the fundamental basis of search ads, relevance modeling has attracted increasing attention due to the significant research challenges and tremendous practical value. Most existing approaches solely rely on the semantic information in the input query-ad pair, while the pure semantic information in the short ads data is not sufficient to fully identify user's search intents. Our motivation lies in incorporating the tremendous amount of unsupervised user behavior data from the historical search logs as the complementary graph to facilitate relevance modeling. In this paper, we extensively investigate how to naturally fuse the semantic textual information with the user behavior graph, and further propose three novel AdsGNN models to aggregate topological neighborhood from the perspectives of nodes, edges and tokens. Furthermore, two critical but rarely investigated problems, domain-specific pre-training and long-tail ads matching, are studied thoroughly. Empirically, we evaluate the AdsGNN models over the large industry dataset, and the experimental results of online/offline tests consistently demonstrate the superiority of our proposal.
TextGNN: Improving Text Encoder via Graph Neural Network in Sponsored Search
Feb 09, 2021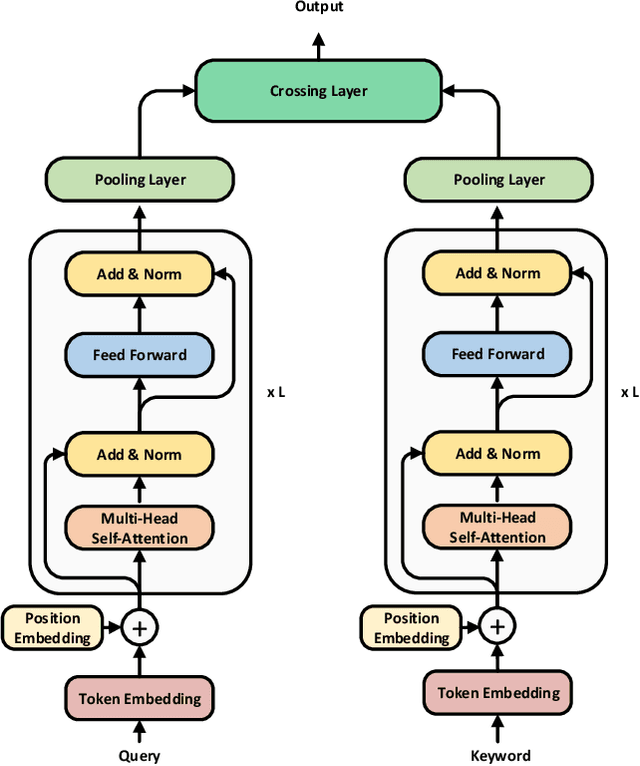
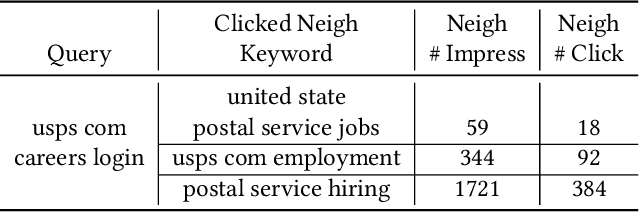
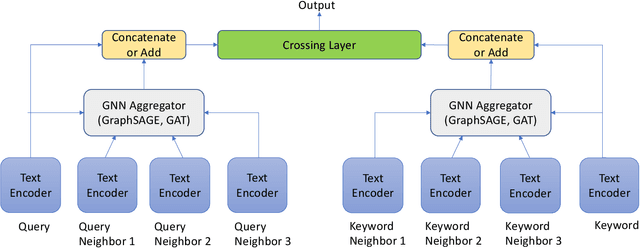
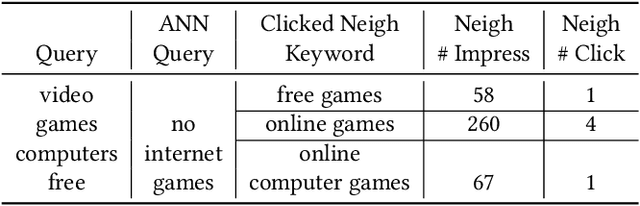
Text encoders based on C-DSSM or transformers have demonstrated strong performance in many Natural Language Processing (NLP) tasks. Low latency variants of these models have also been developed in recent years in order to apply them in the field of sponsored search which has strict computational constraints. However these models are not the panacea to solve all the Natural Language Understanding (NLU) challenges as the pure semantic information in the data is not sufficient to fully identify the user intents. We propose the TextGNN model that naturally extends the strong twin tower structured encoders with the complementary graph information from user historical behaviors, which serves as a natural guide to help us better understand the intents and hence generate better language representations. The model inherits all the benefits of twin tower models such as C-DSSM and TwinBERT so that it can still be used in the low latency environment while achieving a significant performance gain than the strong encoder-only counterpart baseline models in both offline evaluations and online production system. In offline experiments, the model achieves a 0.14% overall increase in ROC-AUC with a 1% increased accuracy for long-tail low-frequency Ads, and in the online A/B testing, the model shows a 2.03% increase in Revenue Per Mille with a 2.32% decrease in Ad defect rate.