 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextGNN: Improving Text Encoder via Graph Neural Network in Sponsored Search
Feb 09, 2021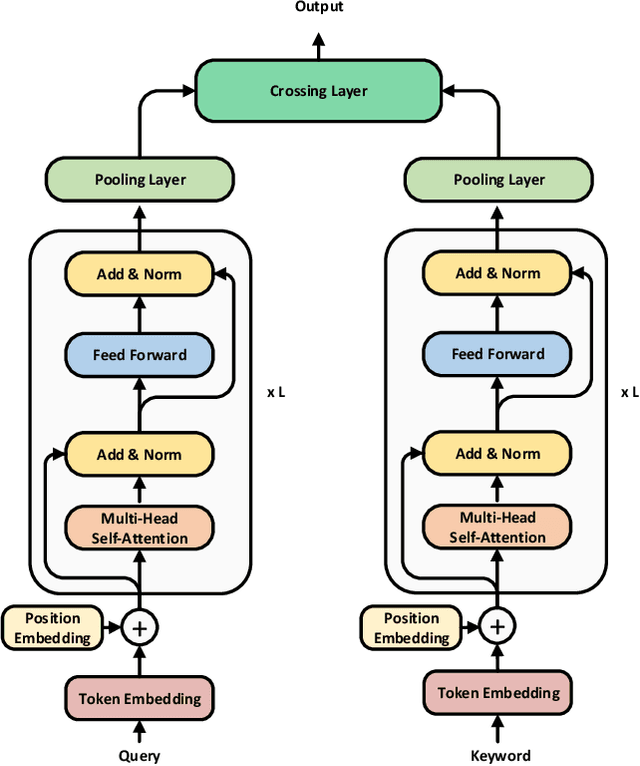
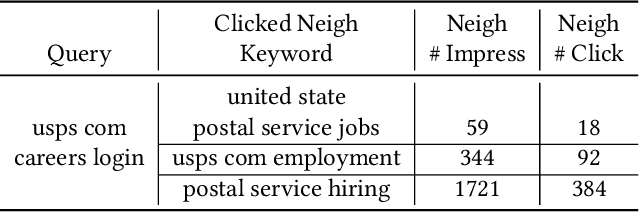
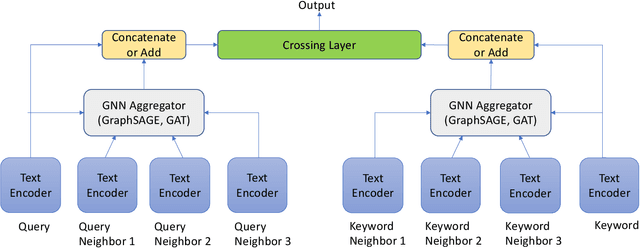
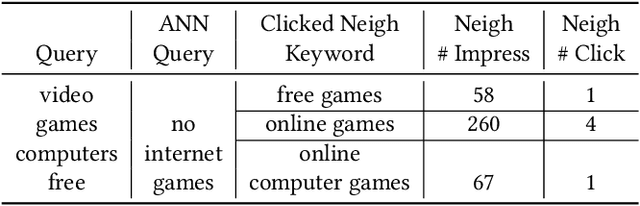
Text encoders based on C-DSSM or transformers have demonstrated strong performance in many Natural Language Processing (NLP) tasks. Low latency variants of these models have also been developed in recent years in order to apply them in the field of sponsored search which has strict computational constraints. However these models are not the panacea to solve all the Natural Language Understanding (NLU) challenges as the pure semantic information in the data is not sufficient to fully identify the user intents. We propose the TextGNN model that naturally extends the strong twin tower structured encoders with the complementary graph information from user historical behaviors, which serves as a natural guide to help us better understand the intents and hence generate better language representations. The model inherits all the benefits of twin tower models such as C-DSSM and TwinBERT so that it can still be used in the low latency environment while achieving a significant performance gain than the strong encoder-only counterpart baseline models in both offline evaluations and online production system. In offline experiments, the model achieves a 0.14% overall increase in ROC-AUC with a 1% increased accuracy for long-tail low-frequency Ads, and in the online A/B testing, the model shows a 2.03% increase in Revenue Per Mille with a 2.32% decrease in Ad defect rate.
SemEval-2020 Task 5: Counterfactual Recognition
Aug 02, 2020
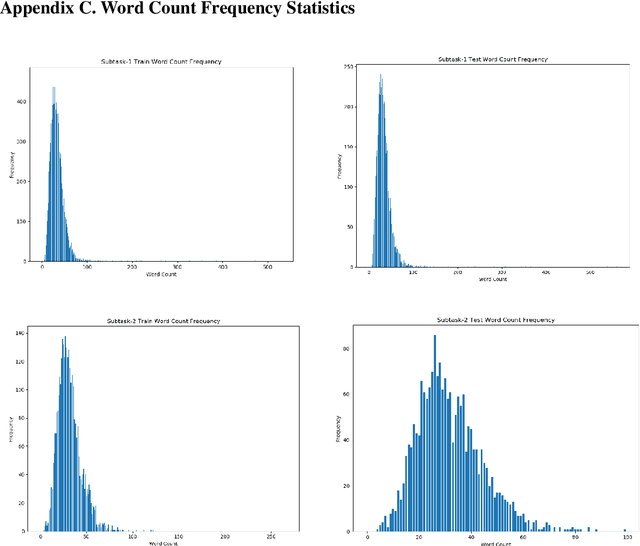

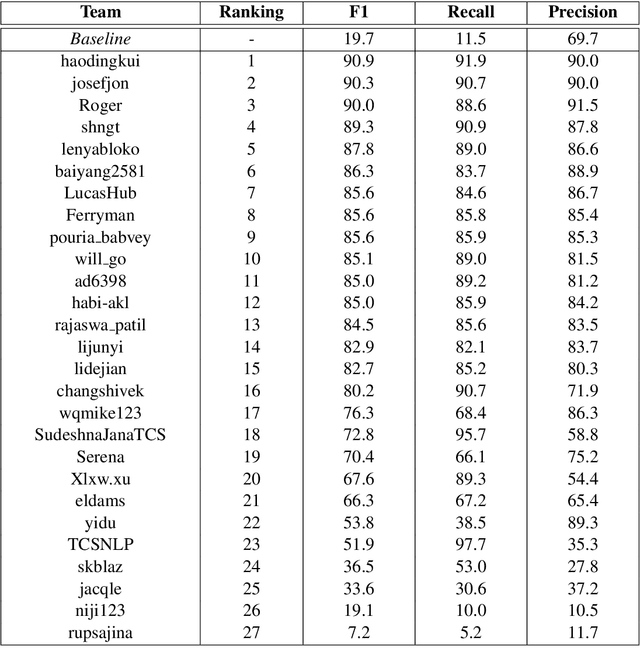
We present a counterfactual recognition (CR) task, the shared Task 5 of SemEval-2020. Counterfactuals describe potential outcomes (consequents) produced by actions or circumstances that did not happen or cannot happen and are counter to the facts (antecedent). Counterfactual thinking is an important characteristic of the human cognitive system; it connects antecedents and consequents with causal relations. Our task provides a benchmark for counterfactual recognition in natural language with two subtasks. Subtask-1 aims to determine whether a given sentence is a counterfactual statement or not. Subtask-2 requires the participating systems to extract the antecedent and consequent in a given counterfactual statement. During the SemEval-2020 official evaluation period, we received 27 submissions to Subtask-1 and 11 to Subtask-2. The data, baseline code, and leaderboard can be found at https://competitions.codalab.org/competitions/21691. The data and baseline code are also available at https://zenodo.org/record/3932442.
Graph Convolution for Multimodal Information Extraction from Visually Rich Documents
Mar 27, 2019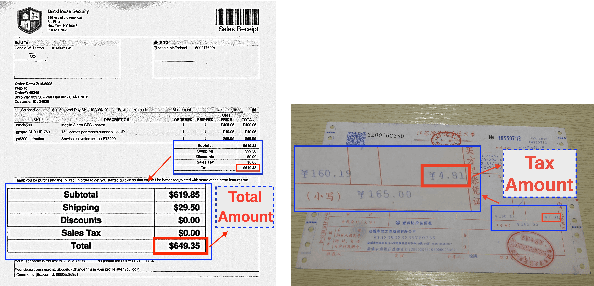
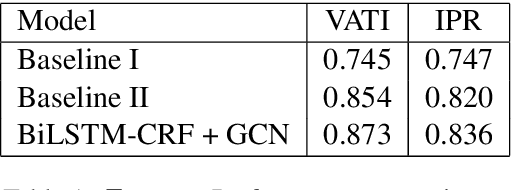
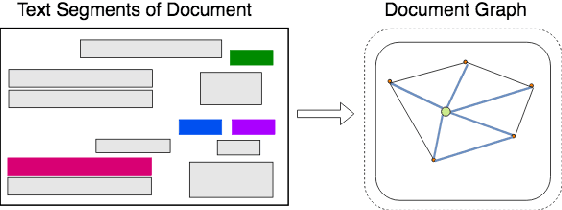
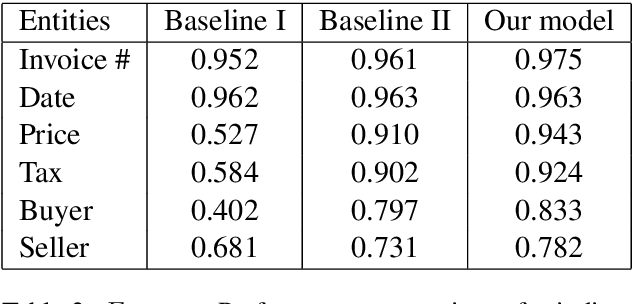
Visually rich documents (VRDs) are ubiquitous in daily business and life. Examples are purchase receipts, insurance policy documents, custom declaration forms and so on. In VRDs, visual and layout information is critical for document understanding, and texts in such documents cannot be serialized into the one-dimensional sequence without losing information. Classic information extraction models such as BiLSTM-CRF typically operate on text sequences and do not incorporate visual features. In this paper, we introduce a graph convolution based model to combine textual and visual information presented in VRDs. Graph embeddings are trained to summarize the context of a text segment in the document, and further combined with text embeddings for entity extraction. Extensive experiments have been conducted to show that our method outperforms BiLSTM-CRF baselines by significant margins, on two real-world datasets. Additionally, ablation studies are also performed to evaluate the effectiveness of each component of our model.
SAME but Different: Fast and High-Quality Gibbs Parameter Estimation
Sep 18, 2014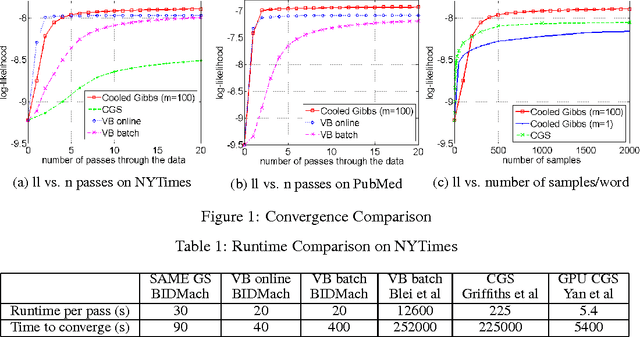
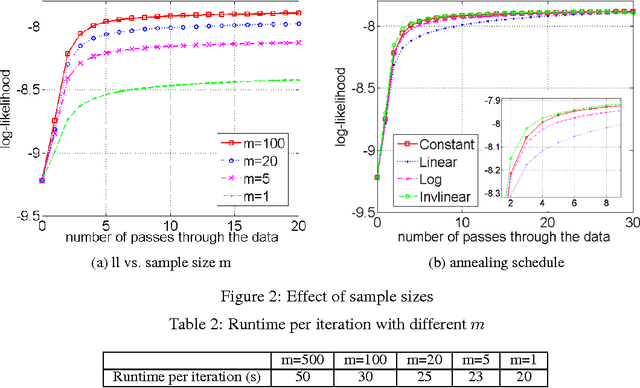
Gibbs sampling is a workhorse for Bayesian inference but has several limitations when used for parameter estimation, and is often much slower than non-sampling inference methods. SAME (State Augmentation for Marginal Estimation) \cite{Doucet99,Doucet02} is an approach to MAP parameter estimation which gives improved parameter estimates over direct Gibbs sampling. SAME can be viewed as cooling the posterior parameter distribution and allows annealed search for the MAP parameters, often yielding very high quality (lower loss) estimates. But it does so at the expense of additional samples per iteration and generally slower performance. On the other hand, SAME dramatically increases the parallelism in the sampling schedule, and is an excellent match for modern (SIMD) hardware. In this paper we explore the application of SAME to graphical model inference on modern hardware. We show that combining SAME with factored sample representation (or approximation) gives throughput competitive with the fastest symbolic methods, but with potentially better quality. We describe experiments on Latent Dirichlet Allocation, achieving speeds similar to the fastest reported methods (online Variational Bayes) and lower cross-validated loss than other LDA implementations. The method is simple to implement and should be applicable to many other models.
Sparse Allreduce: Efficient Scalable Communication for Power-Law Data
Dec 11, 2013



Many large datasets exhibit power-law statistics: The web graph, social networks, text data, click through data etc. Their adjacency graphs are termed natural graphs, and are known to be difficult to partition. As a consequence most distributed algorithms on these graphs are communication intensive. Many algorithms on natural graphs involve an Allreduce: a sum or average of partitioned data which is then shared back to the cluster nodes. Examples include PageRank, spectral partitioning, and many machine learning algorithms including regression, factor (topic) models, and clustering. In this paper we describe an efficient and scalable Allreduce primitive for power-law data. We point out scaling problems with existing butterfly and round-robin networks for Sparse Allreduce, and show that a hybrid approach improves on both. Furthermore, we show that Sparse Allreduce stages should be nested instead of cascaded (as in the dense case). And that the optimum throughput Allreduce network should be a butterfly of heterogeneous degree where degree decreases with depth into the network. Finally, a simple replication scheme is introduced to deal with node failures. We present experiments showing significant improvements over existing systems such as PowerGraph and Hadoop.