 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Robustness of Verbal Confidence of LLMs in Adversarial Attacks
Jul 09, 2025



Robust verbal confidence generated by large language models (LLMs) is crucial for the deployment of LLMs to ensure transparency, trust, and safety in human-AI interactions across many high-stakes applications. In this paper, we present the first comprehensive study on the robustness of verbal confidence under adversarial attacks. We introduce a novel framework for attacking verbal confidence scores through both perturbation and jailbreak-based methods, and show that these attacks can significantly jeopardize verbal confidence estimates and lead to frequent answer changes. We examine a variety of prompting strategies, model sizes, and application domains, revealing that current confidence elicitation methods are vulnerable and that commonly used defence techniques are largely ineffective or counterproductive. Our findings underscore the urgent need to design more robust mechanisms for confidence expression in LLMs, as even subtle semantic-preserving modifications can lead to misleading confidence in responses.
FAIIR: Building Toward A Conversational AI Agent Assistant for Youth Mental Health Service Provision
Jun 10, 2024



World's healthcare systems and mental health agencies face both a growing demand for youth mental health services, alongside a simultaneous challenge of limited resources. Given these constraints, this work presents our experience in the creation and evaluation of the FAIIR (Frontline Assistant: Issue Identification and Recommendation) tool, an ensemble of domain-adapted and fine-tuned transformer models, leveraging natural language processing to identify issues that youth may be experiencing. We explore the technical development, performance, and validation processes leveraged for the FAIIR tool in application to situations of frontline crisis response via Kids Help Phone. Frontline Crisis Responders assign an issue tag from a defined list following each conversation. Assisting with the identification of issues of relevance helps reduce the burden on CRs, ensuring that appropriate resources can be provided and that active rescues and mandatory reporting can take place in critical situations requiring immediate de-escalation.
The FAIIR Tool: A Conversational AI Agent Assistant for Youth Mental Health Service Provision
May 28, 2024World's healthcare systems and mental health agencies face both a growing demand for youth mental health services, alongside a simultaneous challenge of limited resources. Given these constraints, this work presents our experience in the creation and evaluation of the FAIIR (Frontline Assistant: Issue Identification and Recommendation) tool, an ensemble of domain-adapted and fine-tuned transformer models, leveraging natural language processing to identify issues that youth may be experiencing. We explore the technical development, performance, and validation processes leveraged for the FAIIR tool in application to situations of frontline crisis response via Kids Help Phone. Frontline Crisis Responders assign an issue tag from a defined list following each conversation. Assisting with the identification of issues of relevance helps reduce the burden on CRs, ensuring that appropriate resources can be provided and that active rescues and mandatory reporting can take place in critical situations requiring immediate de-escalation.
Calibration Attack: A Framework For Adversarial Attacks Targeting Calibration
Jan 05, 2024



We introduce a new framework of adversarial attacks, named calibration attacks, in which the attacks are generated and organized to trap victim models to be miscalibrated without altering their original accuracy, hence seriously endangering the trustworthiness of the models and any decision-making based on their confidence scores. Specifically, we identify four novel forms of calibration attacks: underconfidence attacks, overconfidence attacks, maximum miscalibration attacks, and random confidence attacks, in both the black-box and white-box setups. We then test these new attacks on typical victim models with comprehensive datasets, demonstrating that even with a relatively low number of queries, the attacks can create significant calibration mistakes. We further provide detailed analyses to understand different aspects of calibration attacks. Building on that, we investigate the effectiveness of widely used adversarial defences and calibration methods against these types of attacks, which then inspires us to devise two novel defences against such calibration attacks.
Effectiveness of Data Augmentation for Prefix Tuning with Limited Data
Mar 05, 2023



Recent work has demonstrated that tuning continuous prompts on large, frozen pretrained language models (i.e., prefix tuning or P-tuning) can yield performance that is comparable or superior to fine-tuning. Nevertheless, the effectiveness of such methods under the context of data augmentation, which has been considered a common strategy to improve learning under low data regimes, has not be studied. In this paper, we examine several popular task-agnostic data augmentation techniques, i.e., EDA, Back Translation, and Mixup, when using prefix tuning under data scarcity. We show that data augmentation can be used to boost the performance of prefix tuning models, but the effectiveness of each technique varies and certain methods can lead to a notable degradation in performance, particularly when using larger models and on harder tasks. To help understand the above behaviour, we run experiments which reveal how prefix tuning generally presents a limited ability to separate the sentence embeddings from different classes of augmented data, and displays poorer performance on heavily altered data in particular. We also demonstrate that by adding a simple contrastive loss we can help mitigate such issues for prefix tuning, resulting in an improvement to augmented data performance.
Bringing the State-of-the-Art to Customers: A Neural Agent Assistant Framework for Customer Service Support
Feb 07, 2023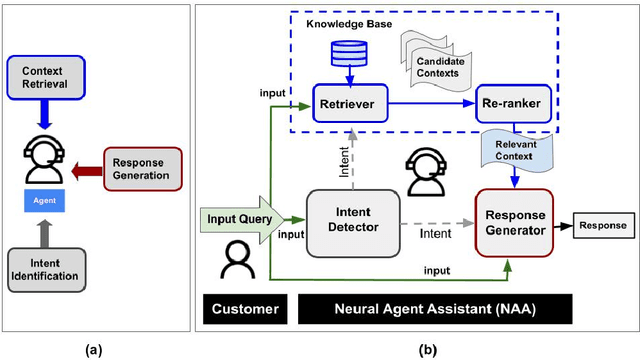
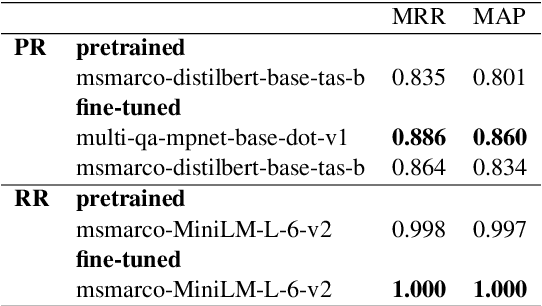
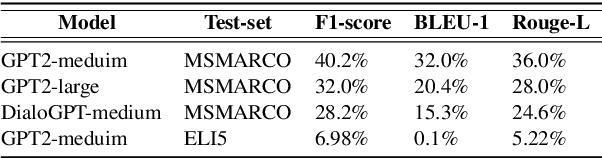
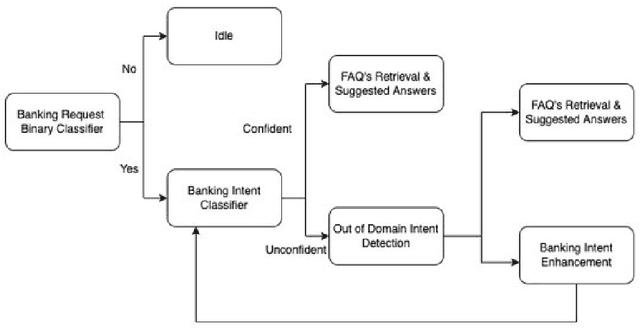
Building Agent Assistants that can help improve customer service support requires inputs from industry users and their customers, as well as knowledge about state-of-the-art Natural Language Processing (NLP) technology. We combine expertise from academia and industry to bridge the gap and build task/domain-specific Neural Agent Assistants (NAA) with three high-level components for: (1) Intent Identification, (2) Context Retrieval, and (3) Response Generation. In this paper, we outline the pipeline of the NAA's core system and also present three case studies in which three industry partners successfully adapt the framework to find solutions to their unique challenges. Our findings suggest that a collaborative process is instrumental in spurring the development of emerging NLP models for Conversational AI tasks in industry. The full reference implementation code and results are available at \url{https://github.com/VectorInstitute/NAA}
SemEval-2020 Task 5: Counterfactual Recognition
Aug 02, 2020
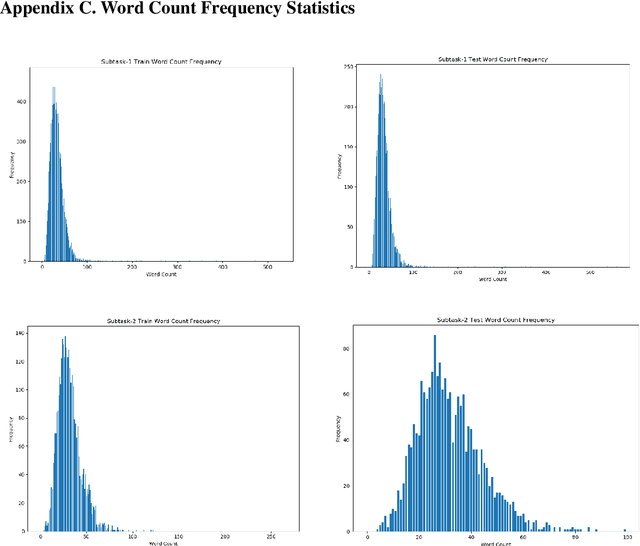

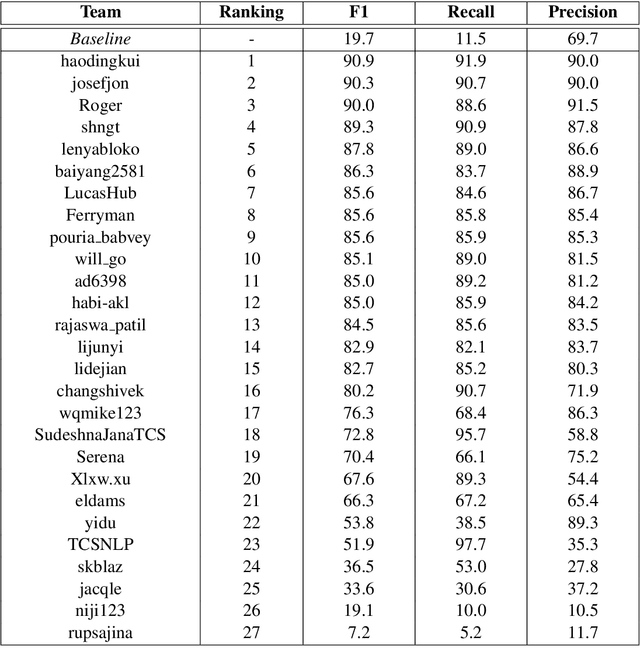
We present a counterfactual recognition (CR) task, the shared Task 5 of SemEval-2020. Counterfactuals describe potential outcomes (consequents) produced by actions or circumstances that did not happen or cannot happen and are counter to the facts (antecedent). Counterfactual thinking is an important characteristic of the human cognitive system; it connects antecedents and consequents with causal relations. Our task provides a benchmark for counterfactual recognition in natural language with two subtasks. Subtask-1 aims to determine whether a given sentence is a counterfactual statement or not. Subtask-2 requires the participating systems to extract the antecedent and consequent in a given counterfactual statement. During the SemEval-2020 official evaluation period, we received 27 submissions to Subtask-1 and 11 to Subtask-2. The data, baseline code, and leaderboard can be found at https://competitions.codalab.org/competitions/21691. The data and baseline code are also available at https://zenodo.org/record/3932442.