 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRVCBench: Benchmarking the Robustness of Voice Cloning Across Modern Audio Generation Models
Jan 31, 2026Modern voice cloning (VC) can synthesize speech that closely matches a target speaker from only seconds of reference audio, enabling applications such as personalized speech interfaces and dubbing. In practical deployments, modern audio generation models inevitably encounter noisy reference audios, imperfect text prompts, and diverse downstream processing, which can significantly hurt robustness. Despite rapid progress in VC driven by autoregressive codec-token language models and diffusion-based models, robustness under realistic deployment shifts remains underexplored. This paper introduces RVCBench, a comprehensive benchmark that evaluates Robustness in VC across the full generation pipeline, including input variation, generation challenges, output post-processing, and adversarial perturbations, covering 10 robustness tasks, 225 speakers, 14,370 utterances, and 11 representative modern VC models. Our evaluation uncovers substantial robustness gaps in VC: performance can deteriorate sharply under common input shifts and post-processing; long-context and cross-lingual scenarios further expose stability limitations; and both passive noise and proactive perturbation influence generation robustness. Collectively, these findings provide a unified picture of how current VC models fail in practice and introduce a standardized, open-source testbed to support the development of more robust and deployable VC models. We open-source our project at https://github.com/Nanboy-Ronan/RVCBench.
SONIC-O1: A Real-World Benchmark for Evaluating Multimodal Large Language Models on Audio-Video Understanding
Jan 29, 2026Multimodal Large Language Models (MLLMs) are a major focus of recent AI research. However, most prior work focuses on static image understanding, while their ability to process sequential audio-video data remains underexplored. This gap highlights the need for a high-quality benchmark to systematically evaluate MLLM performance in a real-world setting. We introduce SONIC-O1, a comprehensive, fully human-verified benchmark spanning 13 real-world conversational domains with 4,958 annotations and demographic metadata. SONIC-O1 evaluates MLLMs on key tasks, including open-ended summarization, multiple-choice question (MCQ) answering, and temporal localization with supporting rationales (reasoning). Experiments on closed- and open-source models reveal limitations. While the performance gap in MCQ accuracy between two model families is relatively small, we observe a substantial 22.6% performance difference in temporal localization between the best performing closed-source and open-source models. Performance further degrades across demographic groups, indicating persistent disparities in model behavior. Overall, SONIC-O1 provides an open evaluation suite for temporally grounded and socially robust multimodal understanding. We release SONIC-O1 for reproducibility and research: Project page: https://vectorinstitute.github.io/sonic-o1/ Dataset: https://huggingface.co/datasets/vector-institute/sonic-o1 Github: https://github.com/vectorinstitute/sonic-o1 Leaderboard: https://huggingface.co/spaces/vector-institute/sonic-o1-leaderboard
Just as Humans Need Vaccines, So Do Models: Model Immunization to Combat Falsehoods
May 23, 2025Generative AI models often learn and reproduce false information present in their training corpora. This position paper argues that, analogous to biological immunization, where controlled exposure to a weakened pathogen builds immunity, AI models should be fine tuned on small, quarantined sets of explicitly labeled falsehoods as a "vaccine" against misinformation. These curated false examples are periodically injected during finetuning, strengthening the model ability to recognize and reject misleading claims while preserving accuracy on truthful inputs. An illustrative case study shows that immunized models generate substantially less misinformation than baselines. To our knowledge, this is the first training framework that treats fact checked falsehoods themselves as a supervised vaccine, rather than relying on input perturbations or generic human feedback signals, to harden models against future misinformation. We also outline ethical safeguards and governance controls to ensure the safe use of false data. Model immunization offers a proactive paradigm for aligning AI systems with factuality.
HumaniBench: A Human-Centric Framework for Large Multimodal Models Evaluation
May 16, 2025



Large multimodal models (LMMs) now excel on many vision language benchmarks, however, they still struggle with human centered criteria such as fairness, ethics, empathy, and inclusivity, key to aligning with human values. We introduce HumaniBench, a holistic benchmark of 32K real-world image question pairs, annotated via a scalable GPT4o assisted pipeline and exhaustively verified by domain experts. HumaniBench evaluates seven Human Centered AI (HCAI) principles: fairness, ethics, understanding, reasoning, language inclusivity, empathy, and robustness, across seven diverse tasks, including open and closed ended visual question answering (VQA), multilingual QA, visual grounding, empathetic captioning, and robustness tests. Benchmarking 15 state of the art LMMs (open and closed source) reveals that proprietary models generally lead, though robustness and visual grounding remain weak points. Some open-source models also struggle to balance accuracy with adherence to human-aligned principles. HumaniBench is the first benchmark purpose built around HCAI principles. It provides a rigorous testbed for diagnosing alignment gaps and guiding LMMs toward behavior that is both accurate and socially responsible. Dataset, annotation prompts, and evaluation code are available at: https://vectorinstitute.github.io/HumaniBench
Practical Guide for Causal Pathways and Sub-group Disparity Analysis
Jul 02, 2024



In this study, we introduce the application of causal disparity analysis to unveil intricate relationships and causal pathways between sensitive attributes and the targeted outcomes within real-world observational data. Our methodology involves employing causal decomposition analysis to quantify and examine the causal interplay between sensitive attributes and outcomes. We also emphasize the significance of integrating heterogeneity assessment in causal disparity analysis to gain deeper insights into the impact of sensitive attributes within specific sub-groups on outcomes. Our two-step investigation focuses on datasets where race serves as the sensitive attribute. The results on two datasets indicate the benefit of leveraging causal analysis and heterogeneity assessment not only for quantifying biases in the data but also for disentangling their influences on outcomes. We demonstrate that the sub-groups identified by our approach to be affected the most by disparities are the ones with the largest ML classification errors. We also show that grouping the data only based on a sensitive attribute is not enough, and through these analyses, we can find sub-groups that are directly affected by disparities. We hope that our findings will encourage the adoption of such methodologies in future ethical AI practices and bias audits, fostering a more equitable and fair technological landscape.
FAIIR: Building Toward A Conversational AI Agent Assistant for Youth Mental Health Service Provision
Jun 10, 2024



World's healthcare systems and mental health agencies face both a growing demand for youth mental health services, alongside a simultaneous challenge of limited resources. Given these constraints, this work presents our experience in the creation and evaluation of the FAIIR (Frontline Assistant: Issue Identification and Recommendation) tool, an ensemble of domain-adapted and fine-tuned transformer models, leveraging natural language processing to identify issues that youth may be experiencing. We explore the technical development, performance, and validation processes leveraged for the FAIIR tool in application to situations of frontline crisis response via Kids Help Phone. Frontline Crisis Responders assign an issue tag from a defined list following each conversation. Assisting with the identification of issues of relevance helps reduce the burden on CRs, ensuring that appropriate resources can be provided and that active rescues and mandatory reporting can take place in critical situations requiring immediate de-escalation.
The FAIIR Tool: A Conversational AI Agent Assistant for Youth Mental Health Service Provision
May 28, 2024World's healthcare systems and mental health agencies face both a growing demand for youth mental health services, alongside a simultaneous challenge of limited resources. Given these constraints, this work presents our experience in the creation and evaluation of the FAIIR (Frontline Assistant: Issue Identification and Recommendation) tool, an ensemble of domain-adapted and fine-tuned transformer models, leveraging natural language processing to identify issues that youth may be experiencing. We explore the technical development, performance, and validation processes leveraged for the FAIIR tool in application to situations of frontline crisis response via Kids Help Phone. Frontline Crisis Responders assign an issue tag from a defined list following each conversation. Assisting with the identification of issues of relevance helps reduce the burden on CRs, ensuring that appropriate resources can be provided and that active rescues and mandatory reporting can take place in critical situations requiring immediate de-escalation.
FAIR Enough: How Can We Develop and Assess a FAIR-Compliant Dataset for Large Language Models' Training?
Jan 23, 2024The rapid evolution of Large Language Models (LLMs) underscores the critical importance of ethical considerations and data integrity in AI development, emphasizing the role of FAIR (Findable, Accessible, Interoperable, Reusable) data principles. While these principles have long been a cornerstone of ethical data stewardship, their application in LLM training data is less prevalent, an issue our research aims to address. Our study begins with a review of existing literature, highlighting the significance of FAIR principles in data management for model training. Building on this foundation, we introduce a novel framework that incorporates FAIR principles into the LLM training process. A key aspect of this approach is a comprehensive checklist, designed to assist researchers and developers in consistently applying FAIR data principles throughout the model development lifecycle. The practicality and effectiveness of our framework are demonstrated through a case study that involves creating a FAIR-compliant dataset to detect and reduce biases. This case study not only validates the usefulness of our framework but also establishes new benchmarks for more equitable, transparent, and ethical practices in LLM training. We offer this framework to the community as a means to promote technologically advanced, ethically sound, and socially responsible AI models.
Mitigating Bias in Conversations: A Hate Speech Classifier and Debiaser with Prompts
Jul 14, 2023

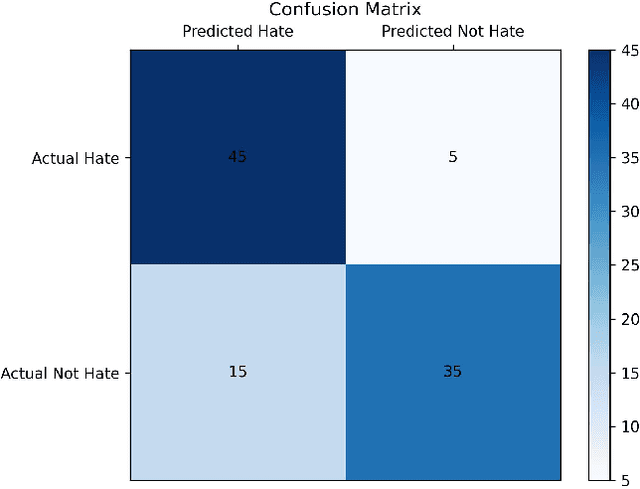

Discriminatory language and biases are often present in hate speech during conversations, which usually lead to negative impacts on targeted groups such as those based on race, gender, and religion. To tackle this issue, we propose an approach that involves a two-step process: first, detecting hate speech using a classifier, and then utilizing a debiasing component that generates less biased or unbiased alternatives through prompts. We evaluated our approach on a benchmark dataset and observed reduction in negativity due to hate speech comments. The proposed method contributes to the ongoing efforts to reduce biases in online discourse and promote a more inclusive and fair environment for communication.
Soft-prompt Tuning for Large Language Models to Evaluate Bias
Jun 07, 2023
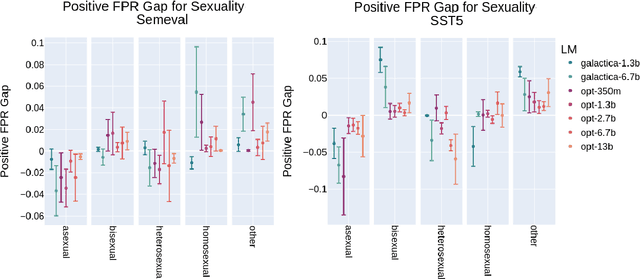
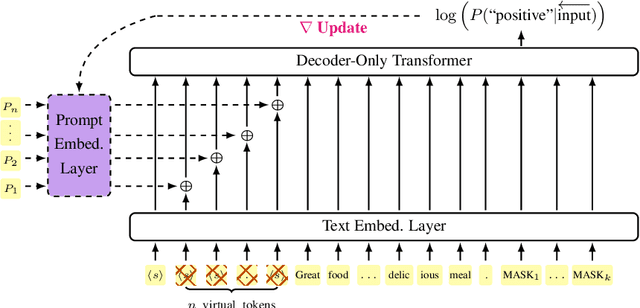
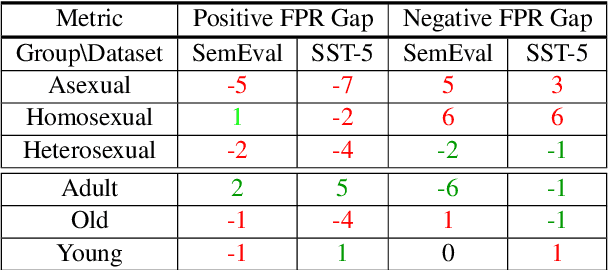
Prompting large language models has gained immense popularity in recent years due to the advantage of producing good results even without the need for labelled data. However, this requires prompt tuning to get optimal prompts that lead to better model performances. In this paper, we explore the use of soft-prompt tuning on sentiment classification task to quantify the biases of large language models (LLMs) such as Open Pre-trained Transformers (OPT) and Galactica language model. Since these models are trained on real-world data that could be prone to bias toward certain groups of populations, it is important to identify these underlying issues. Using soft-prompts to evaluate bias gives us the extra advantage of avoiding the human-bias injection that can be caused by manually designed prompts. We check the model biases on different sensitive attributes using the group fairness (bias) and find interesting bias patterns. Since LLMs have been used in the industry in various applications, it is crucial to identify the biases before deploying these models in practice. We open-source our pipeline and encourage industry researchers to adapt our work to their use cases.