 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmni-DNA: A Unified Genomic Foundation Model for Cross-Modal and Multi-Task Learning
Feb 05, 2025



Large Language Models (LLMs) demonstrate remarkable generalizability across diverse tasks, yet genomic foundation models (GFMs) still require separate finetuning for each downstream application, creating significant overhead as model sizes grow. Moreover, existing GFMs are constrained by rigid output formats, limiting their applicability to various genomic tasks. In this work, we revisit the transformer-based auto-regressive models and introduce Omni-DNA, a family of cross-modal multi-task models ranging from 20 million to 1 billion parameters. Our approach consists of two stages: (i) pretraining on DNA sequences with next token prediction objective, and (ii) expanding the multi-modal task-specific tokens and finetuning for multiple downstream tasks simultaneously. When evaluated on the Nucleotide Transformer and GB benchmarks, Omni-DNA achieves state-of-the-art performance on 18 out of 26 tasks. Through multi-task finetuning, Omni-DNA addresses 10 acetylation and methylation tasks at once, surpassing models trained on each task individually. Finally, we design two complex genomic tasks, DNA2Function and Needle-in-DNA, which map DNA sequences to textual functional descriptions and images, respectively, indicating Omni-DNA's cross-modal capabilities to broaden the scope of genomic applications. All the models are available through https://huggingface.co/collections/zehui127
GV-Rep: A Large-Scale Dataset for Genetic Variant Representation Learning
Jul 24, 2024


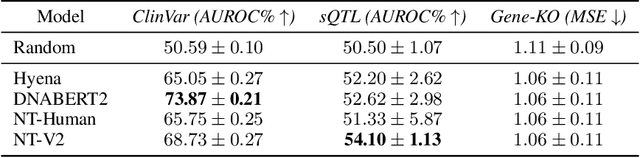
Genetic variants (GVs) are defined as differences in the DNA sequences among individuals and play a crucial role in diagnosing and treating genetic diseases. The rapid decrease in next generation sequencing cost has led to an exponential increase in patient-level GV data. This growth poses a challenge for clinicians who must efficiently prioritize patient-specific GVs and integrate them with existing genomic databases to inform patient management. To addressing the interpretation of GVs, genomic foundation models (GFMs) have emerged. However, these models lack standardized performance assessments, leading to considerable variability in model evaluations. This poses the question: How effectively do deep learning methods classify unknown GVs and align them with clinically-verified GVs? We argue that representation learning, which transforms raw data into meaningful feature spaces, is an effective approach for addressing both indexing and classification challenges. We introduce a large-scale Genetic Variant dataset, named GV-Rep, featuring variable-length contexts and detailed annotations, designed for deep learning models to learn GV representations across various traits, diseases, tissue types, and experimental contexts. Our contributions are three-fold: (i) Construction of a comprehensive dataset with 7 million records, each labeled with characteristics of the corresponding variants, alongside additional data from 17,548 gene knockout tests across 1,107 cell types, 1,808 variant combinations, and 156 unique clinically verified GVs from real-world patients. (ii) Analysis of the structure and properties of the dataset. (iii) Experimentation of the dataset with pre-trained GFMs. The results show a significant gap between GFMs current capabilities and accurate GV representation. We hope this dataset will help advance genomic deep learning to bridge this gap.
MLHOps: Machine Learning for Healthcare Operations
May 04, 2023



Machine Learning Health Operations (MLHOps) is the combination of processes for reliable, efficient, usable, and ethical deployment and maintenance of machine learning models in healthcare settings. This paper provides both a survey of work in this area and guidelines for developers and clinicians to deploy and maintain their own models in clinical practice. We cover the foundational concepts of general machine learning operations, describe the initial setup of MLHOps pipelines (including data sources, preparation, engineering, and tools). We then describe long-term monitoring and updating (including data distribution shifts and model updating) and ethical considerations (including bias, fairness, interpretability, and privacy). This work therefore provides guidance across the full pipeline of MLHOps from conception to initial and ongoing deployment.