 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDispelling the Curse of Singularities in Neural Network Optimizations
Feb 01, 2026This work investigates the optimization instability of deep neural networks from a less-explored yet insightful perspective: the emergence and amplification of singularities in the parametric space. Our analysis reveals that parametric singularities inevitably grow with gradient updates and further intensify alignment with representations, leading to increased singularities in the representation space. We show that the gradient Frobenius norms are bounded by the top singular values of the weight matrices, and as training progresses, the mutually reinforcing growth of weight and representation singularities, termed the curse of singularities, relaxes these bounds, escalating the risk of sharp loss explosions. To counter this, we propose Parametric Singularity Smoothing (PSS), a lightweight, flexible, and effective method for smoothing the singular spectra of weight matrices. Extensive experiments across diverse datasets, architectures, and optimizers demonstrate that PSS mitigates instability, restores trainability even after failure, and improves both training efficiency and generalization.
Feature-Indexed Federated Recommendation with Residual-Quantized Codebooks
Jan 26, 2026Federated recommendation provides a privacy-preserving solution for training recommender systems without centralizing user interactions. However, existing methods follow an ID-indexed communication paradigm that transmit whole item embeddings between clients and the server, which has three major limitations: 1) consumes uncontrollable communication resources, 2) the uploaded item information cannot generalize to related non-interacted items, and 3) is sensitive to client noisy feedback. To solve these problems, it is necessary to fundamentally change the existing ID-indexed communication paradigm. Therefore, we propose a feature-indexed communication paradigm that transmits feature code embeddings as codebooks rather than raw item embeddings. Building on this paradigm, we present RQFedRec, which assigns each item a list of discrete code IDs via Residual Quantization (RQ)-Kmeans. Each client generates and trains code embeddings as codebooks based on discrete code IDs provided by the server, and the server collects and aggregates these codebooks rather than item embeddings. This design makes communication controllable since the codebooks could cover all items, enabling updates to propagate across related items in same code ID. In addition, since code embedding represents many items, which is more robust to a single noisy item. To jointly capture semantic and collaborative information, RQFedRec further adopts a collaborative-semantic dual-channel aggregation with a curriculum strategy that emphasizes semantic codes early and gradually increases the contribution of collaborative codes over training. Extensive experiments on real-world datasets demonstrate that RQFedRec consistently outperforms state-of-the-art federated recommendation baselines while significantly reducing communication overhead.
Local Gradient Regulation Stabilizes Federated Learning under Client Heterogeneity
Jan 07, 2026Federated learning (FL) enables collaborative model training across distributed clients without sharing raw data, yet its stability is fundamentally challenged by statistical heterogeneity in realistic deployments. Here, we show that client heterogeneity destabilizes FL primarily by distorting local gradient dynamics during client-side optimization, causing systematic drift that accumulates across communication rounds and impedes global convergence. This observation highlights local gradients as a key regulatory lever for stabilizing heterogeneous FL systems. Building on this insight, we develop a general client-side perspective that regulates local gradient contributions without incurring additional communication overhead. Inspired by swarm intelligence, we instantiate this perspective through Exploratory--Convergent Gradient Re-aggregation (ECGR), which balances well-aligned and misaligned gradient components to preserve informative updates while suppressing destabilizing effects. Theoretical analysis and extensive experiments, including evaluations on the LC25000 medical imaging dataset, demonstrate that regulating local gradient dynamics consistently stabilizes federated learning across state-of-the-art methods under heterogeneous data distributions.
Physics-Inspired Modeling and Content Adaptive Routing in an Infrared Gas Leak Detection Network
Dec 29, 2025Detecting infrared gas leaks is critical for environmental monitoring and industrial safety, yet remains difficult because plumes are faint, small, semitransparent, and have weak, diffuse boundaries. We present physics-edge hybrid gas dynamic routing network (PEG-DRNet). First, we introduce the Gas Block, a diffusion-convection unit modeling gas transport: a local branch captures short-range variations, while a large-kernel branch captures long-range propagation. An edge-gated learnable fusion module balances local detail and global context, strengthening weak-contrast plume and contour cues. Second, we propose the adaptive gradient and phase edge operator (AGPEO), computing reliable edge priors from multi-directional gradients and phase-consistent responses. These are transformed by a multi-scale edge perception module (MSEPM) into hierarchical edge features that reinforce boundaries. Finally, the content-adaptive sparse routing path aggregation network (CASR-PAN), with adaptive information modulation modules for fusion and self, selectively propagates informative features across scales based on edge and content cues, improving cross-scale discriminability while reducing redundancy. Experiments on the IIG dataset show that PEG-DRNet achieves an overall AP of 29.8\%, an AP$_{50}$ of 84.3\%, and a small-object AP of 25.3\%, surpassing the RT-DETR-R18 baseline by 3.0\%, 6.5\%, and 5.3\%, respectively, while requiring only 43.7 Gflops and 14.9 M parameters. The proposed PEG-DRNet achieves superior overall performance with the best balance of accuracy and computational efficiency, outperforming existing CNN and Transformer detectors in AP and AP$_{50}$ on the IIG and LangGas dataset.
CTTA-T: Continual Test-Time Adaptation for Text Understanding via Teacher-Student with a Domain-aware and Generalized Teacher
Dec 20, 2025Text understanding often suffers from domain shifts. To handle testing domains, domain adaptation (DA) is trained to adapt to a fixed and observed testing domain; a more challenging paradigm, test-time adaptation (TTA), cannot access the testing domain during training and online adapts to the testing samples during testing, where the samples are from a fixed domain. We aim to explore a more practical and underexplored scenario, continual test-time adaptation (CTTA) for text understanding, which involves a sequence of testing (unobserved) domains in testing. Current CTTA methods struggle in reducing error accumulation over domains and enhancing generalization to handle unobserved domains: 1) Noise-filtering reduces accumulated errors but discards useful information, and 2) accumulating historical domains enhances generalization, but it is hard to achieve adaptive accumulation. In this paper, we propose a CTTA-T (continual test-time adaptation for text understanding) framework adaptable to evolving target domains: it adopts a teacher-student framework, where the teacher is domain-aware and generalized for evolving domains. To improve teacher predictions, we propose a refine-then-filter based on dropout-driven consistency, which calibrates predictions and removes unreliable guidance. For the adaptation-generalization trade-off, we construct a domain-aware teacher by dynamically accumulating cross-domain semantics via incremental PCA, which continuously tracks domain shifts. Experiments show CTTA-T excels baselines.
Trade in Minutes! Rationality-Driven Agentic System for Quantitative Financial Trading
Oct 06, 2025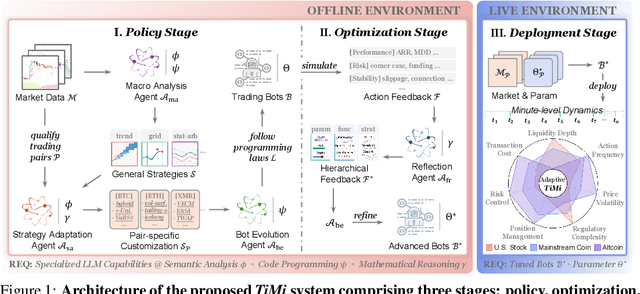
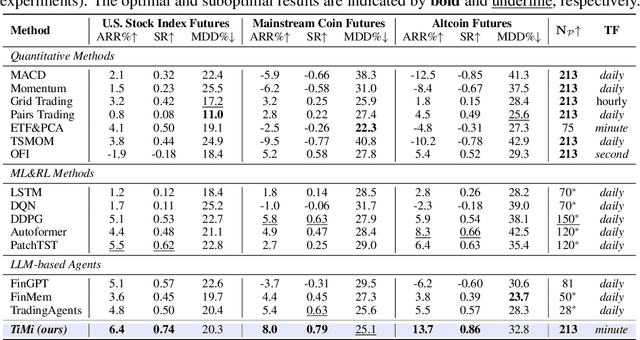
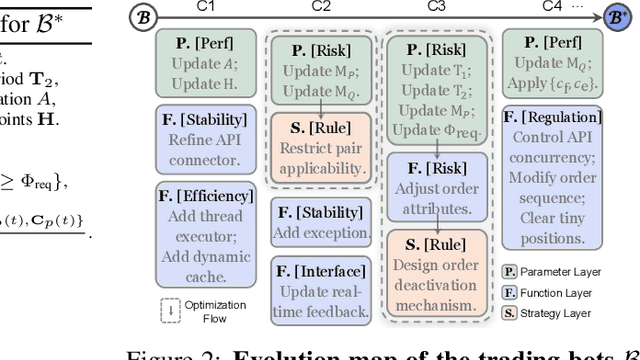
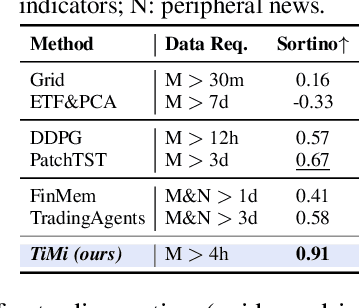
Recent advancements in large language models (LLMs) and agentic systems have shown exceptional decision-making capabilities, revealing significant potential for autonomic finance. Current financial trading agents predominantly simulate anthropomorphic roles that inadvertently introduce emotional biases and rely on peripheral information, while being constrained by the necessity for continuous inference during deployment. In this paper, we pioneer the harmonization of strategic depth in agents with the mechanical rationality essential for quantitative trading. Consequently, we present TiMi (Trade in Minutes), a rationality-driven multi-agent system that architecturally decouples strategy development from minute-level deployment. TiMi leverages specialized LLM capabilities of semantic analysis, code programming, and mathematical reasoning within a comprehensive policy-optimization-deployment chain. Specifically, we propose a two-tier analytical paradigm from macro patterns to micro customization, layered programming design for trading bot implementation, and closed-loop optimization driven by mathematical reflection. Extensive evaluations across 200+ trading pairs in stock and cryptocurrency markets empirically validate the efficacy of TiMi in stable profitability, action efficiency, and risk control under volatile market dynamics.
Prompt Disentanglement via Language Guidance and Representation Alignment for Domain Generalization
Jul 03, 2025Domain Generalization (DG) seeks to develop a versatile model capable of performing effectively on unseen target domains. Notably, recent advances in pre-trained Visual Foundation Models (VFMs), such as CLIP, have demonstrated considerable potential in enhancing the generalization capabilities of deep learning models. Despite the increasing attention toward VFM-based domain prompt tuning within DG, the effective design of prompts capable of disentangling invariant features across diverse domains remains a critical challenge. In this paper, we propose addressing this challenge by leveraging the controllable and flexible language prompt of the VFM. Noting that the text modality of VFMs is naturally easier to disentangle, we introduce a novel framework for text feature-guided visual prompt tuning. This framework first automatically disentangles the text prompt using a large language model (LLM) and then learns domain-invariant visual representation guided by the disentangled text feature. However, relying solely on language to guide visual feature disentanglement has limitations, as visual features can sometimes be too complex or nuanced to be fully captured by descriptive text. To address this, we introduce Worst Explicit Representation Alignment (WERA), which extends text-guided visual prompts by incorporating an additional set of abstract prompts. These prompts enhance source domain diversity through stylized image augmentations, while alignment constraints ensure that visual representations remain consistent across both the original and augmented distributions. Experiments conducted on major DG datasets, including PACS, VLCS, OfficeHome, DomainNet, and TerraInc, demonstrate that our proposed method outperforms state-of-the-art DG methods.
Enhancing User Engagement in Socially-Driven Dialogue through Interactive LLM Alignments
Jun 26, 2025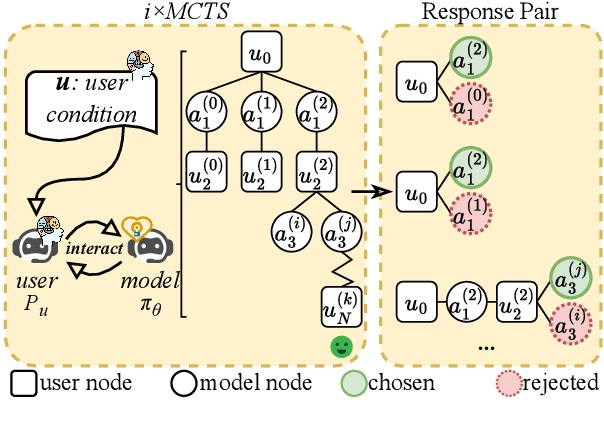

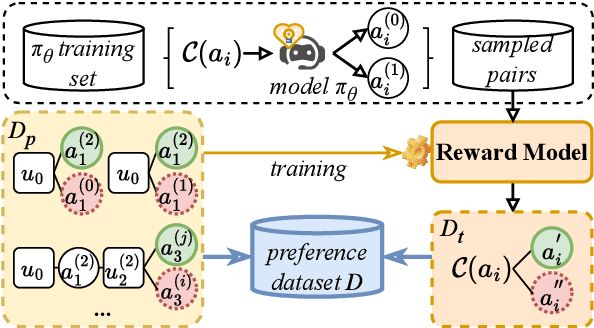

Enhancing user engagement through interactions plays an essential role in socially-driven dialogues. While prior works have optimized models to reason over relevant knowledge or plan a dialogue act flow, the relationship between user engagement and knowledge or dialogue acts is subtle and does not guarantee user engagement in socially-driven dialogues. To this end, we enable interactive LLMs to learn user engagement by leveraging signals from the future development of conversations. Specifically, we adopt a more direct and relevant indicator of user engagement, i.e., the user's reaction related to dialogue intention after the interaction, as a reward to align interactive LLMs. To achieve this, we develop a user simulator to interact with target interactive LLMs and explore interactions between the user and the interactive LLM system via \textit{i$\times$MCTS} (\textit{M}onte \textit{C}arlo \textit{T}ree \textit{S}earch for \textit{i}nteraction). In this way, we collect a dataset containing pairs of higher and lower-quality experiences using \textit{i$\times$MCTS}, and align interactive LLMs for high-level user engagement by direct preference optimization (DPO) accordingly. Experiments conducted on two socially-driven dialogue scenarios (emotional support conversations and persuasion for good) demonstrate that our method effectively enhances user engagement in interactive LLMs.
Bidirectional Knowledge Distillation for Enhancing Sequential Recommendation with Large Language Models
May 23, 2025Large language models (LLMs) have demonstrated exceptional performance in understanding and generating semantic patterns, making them promising candidates for sequential recommendation tasks. However, when combined with conventional recommendation models (CRMs), LLMs often face challenges related to high inference costs and static knowledge transfer methods. In this paper, we propose a novel mutual distillation framework, LLMD4Rec, that fosters dynamic and bidirectional knowledge exchange between LLM-centric and CRM-based recommendation systems. Unlike traditional unidirectional distillation methods, LLMD4Rec enables iterative optimization by alternately refining both models, enhancing the semantic understanding of CRMs and enriching LLMs with collaborative signals from user-item interactions. By leveraging sample-wise adaptive weighting and aligning output distributions, our approach eliminates the need for additional parameters while ensuring effective knowledge transfer. Extensive experiments on real-world datasets demonstrate that LLMD4Rec significantly improves recommendation accuracy across multiple benchmarks without increasing inference costs. This method provides a scalable and efficient solution for combining the strengths of both LLMs and CRMs in sequential recommendation systems.
Do Not Let Low-Probability Tokens Over-Dominate in RL for LLMs
May 19, 2025Reinforcement learning (RL) has become a cornerstone for enhancing the reasoning capabilities of large language models (LLMs), with recent innovations such as Group Relative Policy Optimization (GRPO) demonstrating exceptional effectiveness. In this study, we identify a critical yet underexplored issue in RL training: low-probability tokens disproportionately influence model updates due to their large gradient magnitudes. This dominance hinders the effective learning of high-probability tokens, whose gradients are essential for LLMs' performance but are substantially suppressed. To mitigate this interference, we propose two novel methods: Advantage Reweighting and Low-Probability Token Isolation (Lopti), both of which effectively attenuate gradients from low-probability tokens while emphasizing parameter updates driven by high-probability tokens. Our approaches promote balanced updates across tokens with varying probabilities, thereby enhancing the efficiency of RL training. Experimental results demonstrate that they substantially improve the performance of GRPO-trained LLMs, achieving up to a 46.2% improvement in K&K Logic Puzzle reasoning tasks. Our implementation is available at https://github.com/zhyang2226/AR-Lopti.