 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing the Medical Context-Awareness Ability of LLMs via Multifaceted Self-Refinement Learning
Nov 14, 2025Large language models (LLMs) have shown great promise in the medical domain, achieving strong performance on several benchmarks. However, they continue to underperform in real-world medical scenarios, which often demand stronger context-awareness, i.e., the ability to recognize missing or critical details (e.g., user identity, medical history, risk factors) and provide safe, helpful, and contextually appropriate responses. To address this issue, we propose Multifaceted Self-Refinement (MuSeR), a data-driven approach that enhances LLMs' context-awareness along three key facets (decision-making, communication, and safety) through self-evaluation and refinement. Specifically, we first design a attribute-conditioned query generator that simulates diverse real-world user contexts by varying attributes such as role, geographic region, intent, and degree of information ambiguity. An LLM then responds to these queries, self-evaluates its answers along three key facets, and refines its responses to better align with the requirements of each facet. Finally, the queries and refined responses are used for supervised fine-tuning to reinforce the model's context-awareness ability. Evaluation results on the latest HealthBench dataset demonstrate that our method significantly improves LLM performance across multiple aspects, with particularly notable gains in the context-awareness axis. Furthermore, by incorporating knowledge distillation with the proposed method, the performance of a smaller backbone LLM (e.g., Qwen3-32B) surpasses its teacher model, achieving a new SOTA across all open-source LLMs on HealthBench (63.8%) and its hard subset (43.1%). Code and dataset will be released at https://muser-llm.github.io.
REMOTE: A Unified Multimodal Relation Extraction Framework with Multilevel Optimal Transport and Mixture-of-Experts
Sep 05, 2025
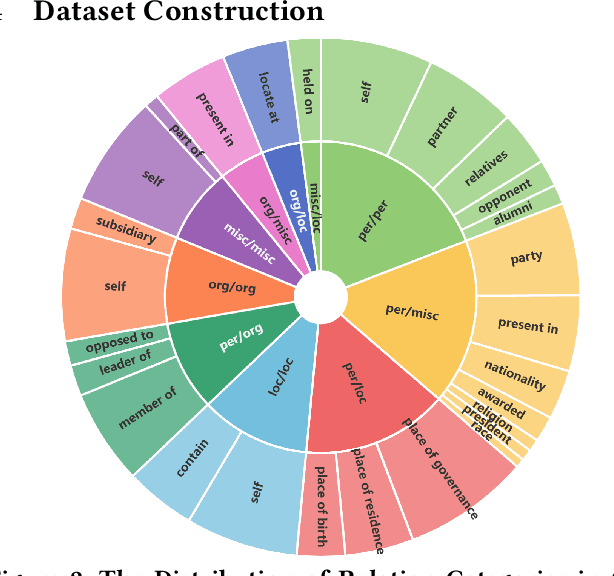
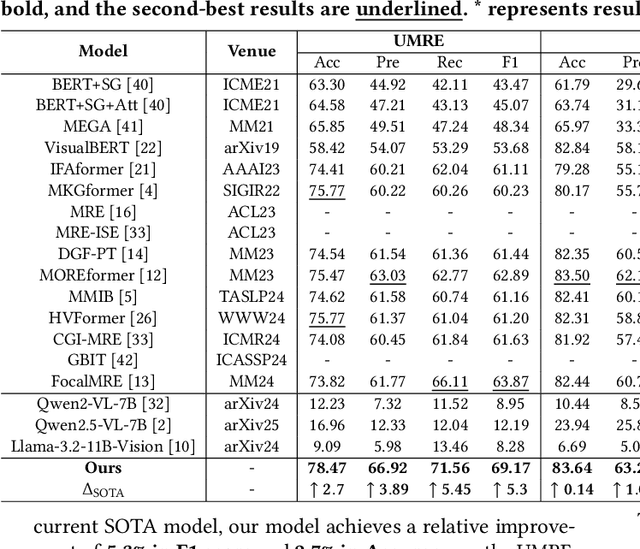
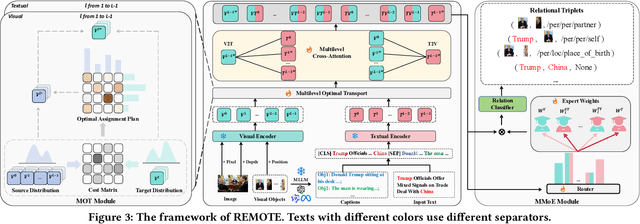
Multimodal relation extraction (MRE) is a crucial task in the fields of Knowledge Graph and Multimedia, playing a pivotal role in multimodal knowledge graph construction. However, existing methods are typically limited to extracting a single type of relational triplet, which restricts their ability to extract triplets beyond the specified types. Directly combining these methods fails to capture dynamic cross-modal interactions and introduces significant computational redundancy. Therefore, we propose a novel \textit{unified multimodal Relation Extraction framework with Multilevel Optimal Transport and mixture-of-Experts}, termed REMOTE, which can simultaneously extract intra-modal and inter-modal relations between textual entities and visual objects. To dynamically select optimal interaction features for different types of relational triplets, we introduce mixture-of-experts mechanism, ensuring the most relevant modality information is utilized. Additionally, considering that the inherent property of multilayer sequential encoding in existing encoders often leads to the loss of low-level information, we adopt a multilevel optimal transport fusion module to preserve low-level features while maintaining multilayer encoding, yielding more expressive representations. Correspondingly, we also create a Unified Multimodal Relation Extraction (UMRE) dataset to evaluate the effectiveness of our framework, encompassing diverse cases where the head and tail entities can originate from either text or image. Extensive experiments show that REMOTE effectively extracts various types of relational triplets and achieves state-of-the-art performanc on almost all metrics across two other public MRE datasets. We release our resources at https://github.com/Nikol-coder/REMOTE.
Exploring Interpretability for Visual Prompt Tuning with Hierarchical Concepts
Mar 08, 2025Visual prompt tuning offers significant advantages for adapting pre-trained visual foundation models to specific tasks. However, current research provides limited insight into the interpretability of this approach, which is essential for enhancing AI reliability and enabling AI-driven knowledge discovery. In this paper, rather than learning abstract prompt embeddings, we propose the first framework, named Interpretable Visual Prompt Tuning (IVPT), to explore interpretability for visual prompts, by introducing hierarchical concept prototypes. Specifically, visual prompts are linked to human-understandable semantic concepts, represented as a set of category-agnostic prototypes, each corresponding to a specific region of the image. Then, IVPT aggregates features from these regions to generate interpretable prompts, which are structured hierarchically to explain visual prompts at different granularities. Comprehensive qualitative and quantitative evaluations on fine-grained classification benchmarks show its superior interpretability and performance over conventional visual prompt tuning methods and existing interpretable methods.
Bilevel Multi-Armed Bandit-Based Hierarchical Reinforcement Learning for Interaction-Aware Self-Driving at Unsignalized Intersections
Feb 06, 2025



In this work, we present BiM-ACPPO, a bilevel multi-armed bandit-based hierarchical reinforcement learning framework for interaction-aware decision-making and planning at unsignalized intersections. Essentially, it proactively takes the uncertainties associated with surrounding vehicles (SVs) into consideration, which encompass those stemming from the driver's intention, interactive behaviors, and the varying number of SVs. Intermediate decision variables are introduced to enable the high-level RL policy to provide an interaction-aware reference, for guiding low-level model predictive control (MPC) and further enhancing the generalization ability of the proposed framework. By leveraging the structured nature of self-driving at unsignalized intersections, the training problem of the RL policy is modeled as a bilevel curriculum learning task, which is addressed by the proposed Exp3.S-based BiMAB algorithm. It is noteworthy that the training curricula are dynamically adjusted, thereby facilitating the sample efficiency of the RL training process. Comparative experiments are conducted in the high-fidelity CARLA simulator, and the results indicate that our approach achieves superior performance compared to all baseline methods. Furthermore, experimental results in two new urban driving scenarios clearly demonstrate the commendable generalization performance of the proposed method.
LearningFlow: Automated Policy Learning Workflow for Urban Driving with Large Language Models
Jan 09, 2025Recent advancements in reinforcement learning (RL) demonstrate the significant potential in autonomous driving. Despite this promise, challenges such as the manual design of reward functions and low sample efficiency in complex environments continue to impede the development of safe and effective driving policies. To tackle these issues, we introduce LearningFlow, an innovative automated policy learning workflow tailored to urban driving. This framework leverages the collaboration of multiple large language model (LLM) agents throughout the RL training process. LearningFlow includes a curriculum sequence generation process and a reward generation process, which work in tandem to guide the RL policy by generating tailored training curricula and reward functions. Particularly, each process is supported by an analysis agent that evaluates training progress and provides critical insights to the generation agent. Through the collaborative efforts of these LLM agents, LearningFlow automates policy learning across a series of complex driving tasks, and it significantly reduces the reliance on manual reward function design while enhancing sample efficiency. Comprehensive experiments are conducted in the high-fidelity CARLA simulator, along with comparisons with other existing methods, to demonstrate the efficacy of our proposed approach. The results demonstrate that LearningFlow excels in generating rewards and curricula. It also achieves superior performance and robust generalization across various driving tasks, as well as commendable adaptation to different RL algorithms.
CALMM-Drive: Confidence-Aware Autonomous Driving with Large Multimodal Model
Dec 05, 2024



Decision-making and motion planning are pivotal in ensuring the safety and efficiency of Autonomous Vehicles (AVs). Existing methodologies typically adopt two paradigms: decision then planning or generation then scoring. However, the former often struggles with misalignment between decisions and planning, while the latter encounters significant challenges in integrating short-term operational utility with long-term tactical efficacy. To address these issues, we introduce CALMM-Drive, a novel Confidence-Aware Large Multimodal Model (LMM) empowered Autonomous Driving framework. Our approach employs Top-K confidence elicitation, which facilitates the generation of multiple candidate decisions along with their confidence levels. Furthermore, we propose a novel planning module that integrates a diffusion model for trajectory generation and a hierarchical refinement process to find the optimal path. This framework enables the selection of the best plan accounting for both low-level solution quality and high-level tactical confidence, which mitigates the risks of one-shot decisions and overcomes the limitations induced by short-sighted scoring mechanisms. Comprehensive evaluations in nuPlan closed-loop simulation environments demonstrate the effectiveness of CALMM-Drive in achieving reliable and flexible driving performance, showcasing a significant advancement in the integration of uncertainty in LMM-empowered AVs. The code will be released upon acceptance.
Uni$^2$Det: Unified and Universal Framework for Prompt-Guided Multi-dataset 3D Detection
Sep 30, 2024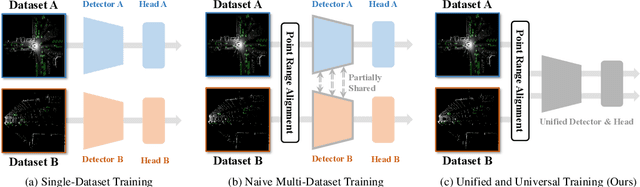
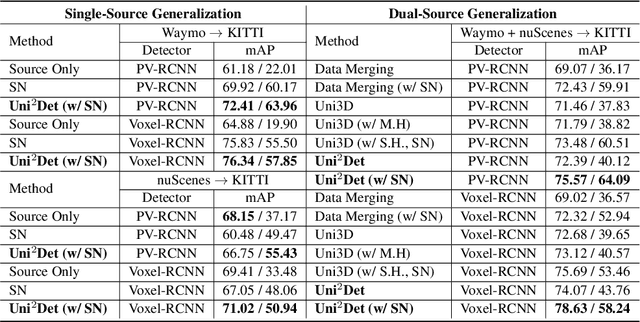
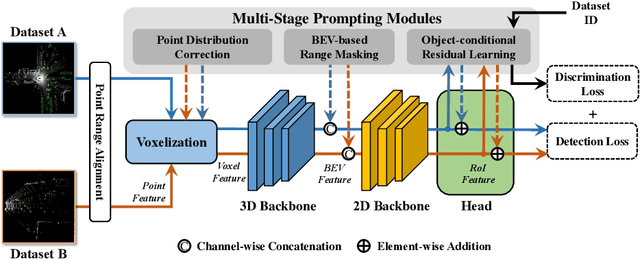
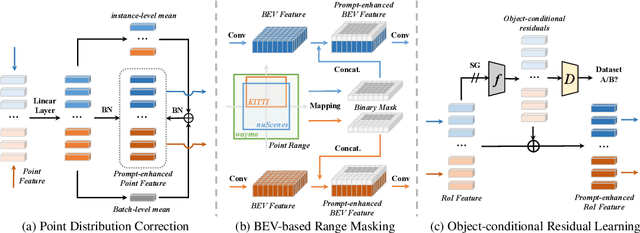
We present Uni$^2$Det, a brand new framework for unified and universal multi-dataset training on 3D detection, enabling robust performance across diverse domains and generalization to unseen domains. Due to substantial disparities in data distribution and variations in taxonomy across diverse domains, training such a detector by simply merging datasets poses a significant challenge. Motivated by this observation, we introduce multi-stage prompting modules for multi-dataset 3D detection, which leverages prompts based on the characteristics of corresponding datasets to mitigate existing differences. This elegant design facilitates seamless plug-and-play integration within various advanced 3D detection frameworks in a unified manner, while also allowing straightforward adaptation for universal applicability across datasets. Experiments are conducted across multiple dataset consolidation scenarios involving KITTI, Waymo, and nuScenes, demonstrating that our Uni$^2$Det outperforms existing methods by a large margin in multi-dataset training. Notably, results on zero-shot cross-dataset transfer validate the generalization capability of our proposed method.
HPT++: Hierarchically Prompting Vision-Language Models with Multi-Granularity Knowledge Generation and Improved Structure Modeling
Aug 27, 2024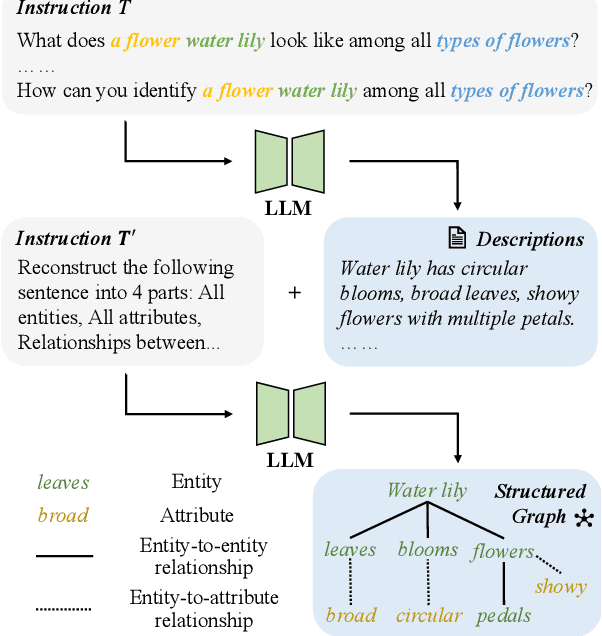
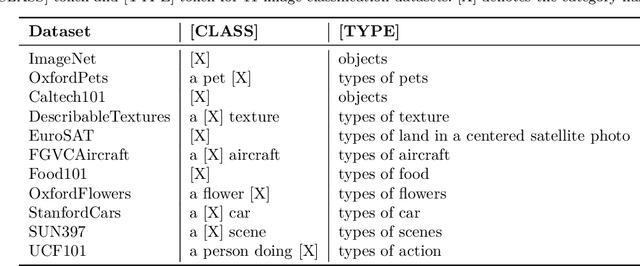
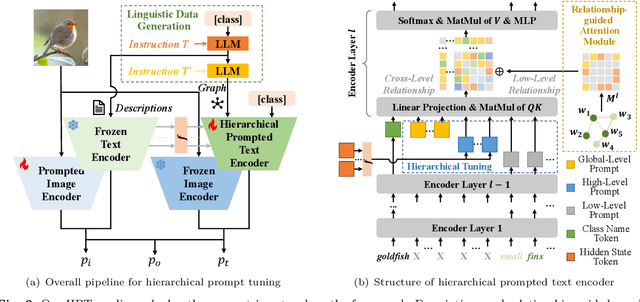
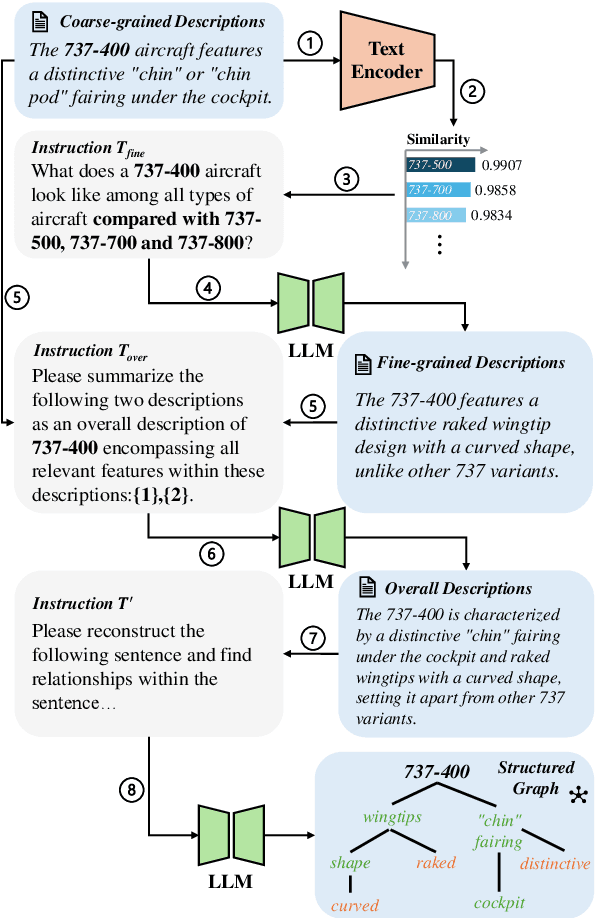
Prompt learning has become a prevalent strategy for adapting vision-language foundation models (VLMs) such as CLIP to downstream tasks. With the emergence of large language models (LLMs), recent studies have explored the potential of using category-related descriptions to enhance prompt effectiveness. However, conventional descriptions lack explicit structured information necessary to represent the interconnections among key elements like entities or attributes with relation to a particular category. Since existing prompt tuning methods give little consideration to managing structured knowledge, this paper advocates leveraging LLMs to construct a graph for each description to prioritize such structured knowledge. Consequently, we propose a novel approach called Hierarchical Prompt Tuning (HPT), enabling simultaneous modeling of both structured and conventional linguistic knowledge. Specifically, we introduce a relationship-guided attention module to capture pair-wise associations among entities and attributes for low-level prompt learning. In addition, by incorporating high-level and global-level prompts modeling overall semantics, the proposed hierarchical structure forges cross-level interlinks and empowers the model to handle more complex and long-term relationships. Finally, by enhancing multi-granularity knowledge generation, redesigning the relationship-driven attention re-weighting module, and incorporating consistent constraints on the hierarchical text encoder, we propose HPT++, which further improves the performance of HPT. Our experiments are conducted across a wide range of evaluation settings, including base-to-new generalization, cross-dataset evaluation, and domain generalization. Extensive results and ablation studies demonstrate the effectiveness of our methods, which consistently outperform existing SOTA methods.
ActPrompt: In-Domain Feature Adaptation via Action Cues for Video Temporal Grounding
Aug 13, 2024Video temporal grounding is an emerging topic aiming to identify specific clips within videos. In addition to pre-trained video models, contemporary methods utilize pre-trained vision-language models (VLM) to capture detailed characteristics of diverse scenes and objects from video frames. However, as pre-trained on images, VLM may struggle to distinguish action-sensitive patterns from static objects, making it necessary to adapt them to specific data domains for effective feature representation over temporal grounding. We address two primary challenges to achieve this goal. Specifically, to mitigate high adaptation costs, we propose an efficient preliminary in-domain fine-tuning paradigm for feature adaptation, where downstream-adaptive features are learned through several pretext tasks. Furthermore, to integrate action-sensitive information into VLM, we introduce Action-Cue-Injected Temporal Prompt Learning (ActPrompt), which injects action cues into the image encoder of VLM for better discovering action-sensitive patterns. Extensive experiments demonstrate that ActPrompt is an off-the-shelf training framework that can be effectively applied to various SOTA methods, resulting in notable improvements. The complete code used in this study is provided in the supplementary materials.
Reward-Driven Automated Curriculum Learning for Interaction-Aware Self-Driving at Unsignalized Intersections
Mar 20, 2024



In this work, we present a reward-driven automated curriculum reinforcement learning approach for interaction-aware self-driving at unsignalized intersections, taking into account the uncertainties associated with surrounding vehicles (SVs). These uncertainties encompass the uncertainty of SVs' driving intention and also the quantity of SVs. To deal with this problem, the curriculum set is specifically designed to accommodate a progressively increasing number of SVs. By implementing an automated curriculum selection mechanism, the importance weights are rationally allocated across various curricula, thereby facilitating improved sample efficiency and training outcomes. Furthermore, the reward function is meticulously designed to guide the agent towards effective policy exploration. Thus the proposed framework could proactively address the above uncertainties at unsignalized intersections by employing the automated curriculum learning technique that progressively increases task difficulty, and this ensures safe self-driving through effective interaction with SVs. Comparative experiments are conducted in $Highway\_Env$, and the results indicate that our approach achieves the highest task success rate, attains strong robustness to initialization parameters of the curriculum selection module, and exhibits superior adaptability to diverse situational configurations at unsignalized intersections. Furthermore, the effectiveness of the proposed method is validated using the high-fidelity CARLA simulator.