 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter-Efficient Fine-Tuning in Spectral Domain for Point Cloud Learning
Oct 10, 2024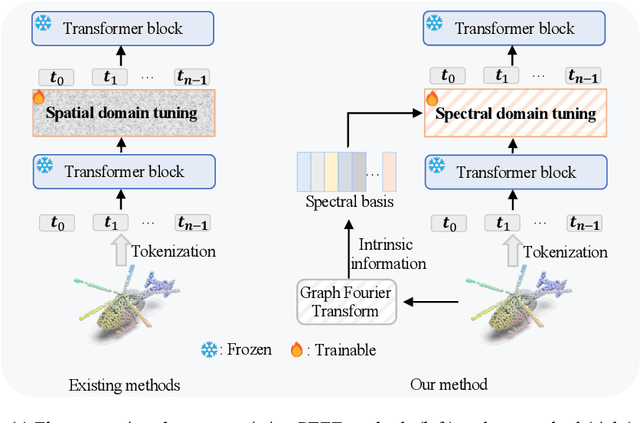



Recently, leveraging pre-training techniques to enhance point cloud models has become a hot research topic. However, existing approaches typically require full fine-tuning of pre-trained models to achieve satisfied performance on downstream tasks, accompanying storage-intensive and computationally demanding. To address this issue, we propose a novel Parameter-Efficient Fine-Tuning (PEFT) method for point cloud, called PointGST (Point cloud Graph Spectral Tuning). PointGST freezes the pre-trained model and introduces a lightweight, trainable Point Cloud Spectral Adapter (PCSA) to fine-tune parameters in the spectral domain. The core idea is built on two observations: 1) The inner tokens from frozen models might present confusion in the spatial domain; 2) Task-specific intrinsic information is important for transferring the general knowledge to the downstream task. Specifically, PointGST transfers the point tokens from the spatial domain to the spectral domain, effectively de-correlating confusion among tokens via using orthogonal components for separating. Moreover, the generated spectral basis involves intrinsic information about the downstream point clouds, enabling more targeted tuning. As a result, PointGST facilitates the efficient transfer of general knowledge to downstream tasks while significantly reducing training costs. Extensive experiments on challenging point cloud datasets across various tasks demonstrate that PointGST not only outperforms its fully fine-tuning counterpart but also significantly reduces trainable parameters, making it a promising solution for efficient point cloud learning. It improves upon a solid baseline by +2.28%, 1.16%, and 2.78%, resulting in 99.48%, 97.76%, and 96.18% on the ScanObjNN OBJ BG, OBJ OBLY, and PB T50 RS datasets, respectively. This advancement establishes a new state-of-the-art, using only 0.67% of the trainable parameters.
Uni$^2$Det: Unified and Universal Framework for Prompt-Guided Multi-dataset 3D Detection
Sep 30, 2024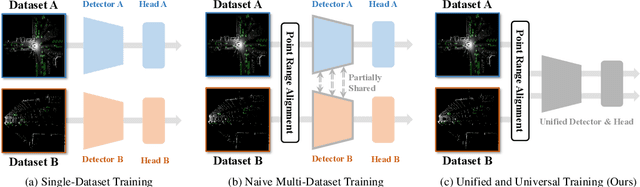
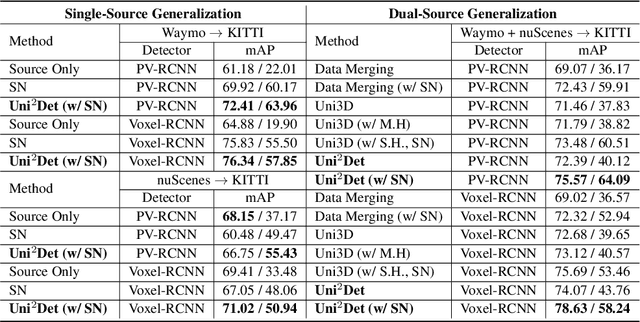
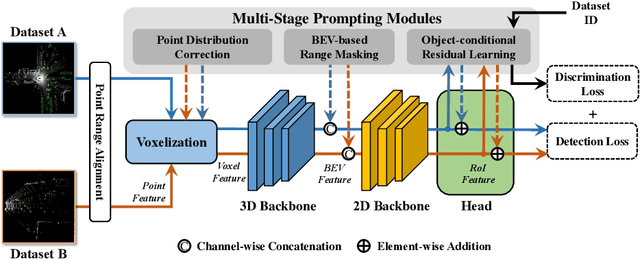
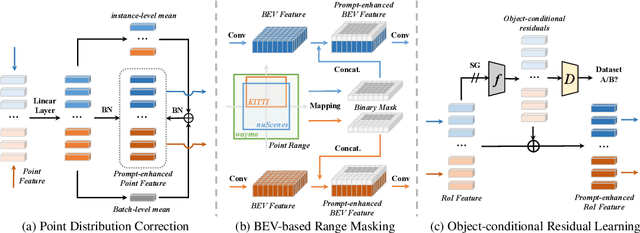
We present Uni$^2$Det, a brand new framework for unified and universal multi-dataset training on 3D detection, enabling robust performance across diverse domains and generalization to unseen domains. Due to substantial disparities in data distribution and variations in taxonomy across diverse domains, training such a detector by simply merging datasets poses a significant challenge. Motivated by this observation, we introduce multi-stage prompting modules for multi-dataset 3D detection, which leverages prompts based on the characteristics of corresponding datasets to mitigate existing differences. This elegant design facilitates seamless plug-and-play integration within various advanced 3D detection frameworks in a unified manner, while also allowing straightforward adaptation for universal applicability across datasets. Experiments are conducted across multiple dataset consolidation scenarios involving KITTI, Waymo, and nuScenes, demonstrating that our Uni$^2$Det outperforms existing methods by a large margin in multi-dataset training. Notably, results on zero-shot cross-dataset transfer validate the generalization capability of our proposed method.
Exploring the Causality of End-to-End Autonomous Driving
Jul 09, 2024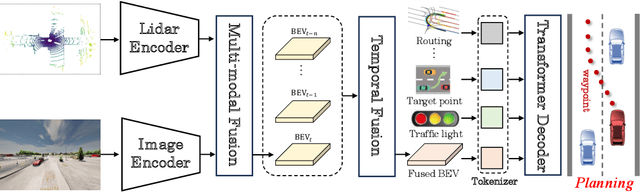
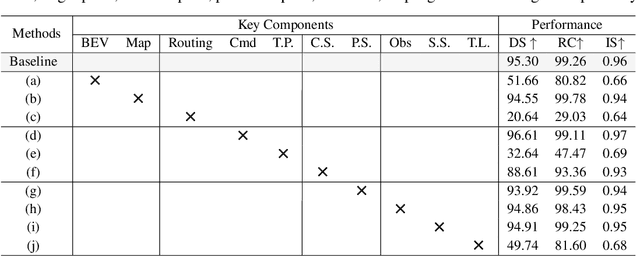

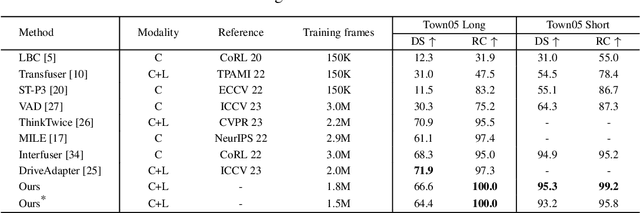
Deep learning-based models are widely deployed in autonomous driving areas, especially the increasingly noticed end-to-end solutions. However, the black-box property of these models raises concerns about their trustworthiness and safety for autonomous driving, and how to debug the causality has become a pressing concern. Despite some existing research on the explainability of autonomous driving, there is currently no systematic solution to help researchers debug and identify the key factors that lead to the final predicted action of end-to-end autonomous driving. In this work, we propose a comprehensive approach to explore and analyze the causality of end-to-end autonomous driving. First, we validate the essential information that the final planning depends on by using controlled variables and counterfactual interventions for qualitative analysis. Then, we quantitatively assess the factors influencing model decisions by visualizing and statistically analyzing the response of key model inputs. Finally, based on the comprehensive study of the multi-factorial end-to-end autonomous driving system, we have developed a strong baseline and a tool for exploring causality in the close-loop simulator CARLA. It leverages the essential input sources to obtain a well-designed model, resulting in highly competitive capabilities. As far as we know, our work is the first to unveil the mystery of end-to-end autonomous driving and turn the black box into a white one. Thorough close-loop experiments demonstrate that our method can be applied to end-to-end autonomous driving solutions for causality debugging. Code will be available at https://github.com/bdvisl/DriveInsight.
SOOD++: Leveraging Unlabeled Data to Boost Oriented Object Detection
Jul 01, 2024Semi-supervised object detection (SSOD), leveraging unlabeled data to boost object detectors, has become a hot topic recently. However, existing SSOD approaches mainly focus on horizontal objects, leaving multi-oriented objects common in aerial images unexplored. At the same time, the annotation cost of multi-oriented objects is significantly higher than that of their horizontal counterparts. Therefore, in this paper, we propose a simple yet effective Semi-supervised Oriented Object Detection method termed SOOD++. Specifically, we observe that objects from aerial images are usually arbitrary orientations, small scales, and aggregation, which inspires the following core designs: a Simple Instance-aware Dense Sampling (SIDS) strategy is used to generate comprehensive dense pseudo-labels; the Geometry-aware Adaptive Weighting (GAW) loss dynamically modulates the importance of each pair between pseudo-label and corresponding prediction by leveraging the intricate geometric information of aerial objects; we treat aerial images as global layouts and explicitly build the many-to-many relationship between the sets of pseudo-labels and predictions via the proposed Noise-driven Global Consistency (NGC). Extensive experiments conducted on various multi-oriented object datasets under various labeled settings demonstrate the effectiveness of our method. For example, on the DOTA-V1.5 benchmark, the proposed method outperforms previous state-of-the-art (SOTA) by a large margin (+2.92, +2.39, and +2.57 mAP under 10%, 20%, and 30% labeled data settings, respectively) with single-scale training and testing. More importantly, it still improves upon a strong supervised baseline with 70.66 mAP, trained using the full DOTA-V1.5 train-val set, by +1.82 mAP, resulting in a 72.48 mAP, pushing the new state-of-the-art. The code will be made available.
Dynamic Adapter Meets Prompt Tuning: Parameter-Efficient Transfer Learning for Point Cloud Analysis
Mar 03, 2024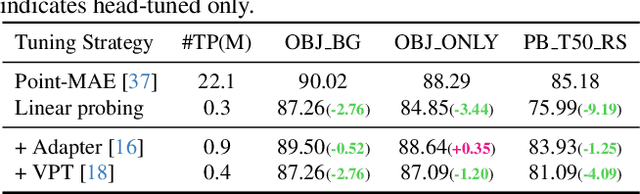
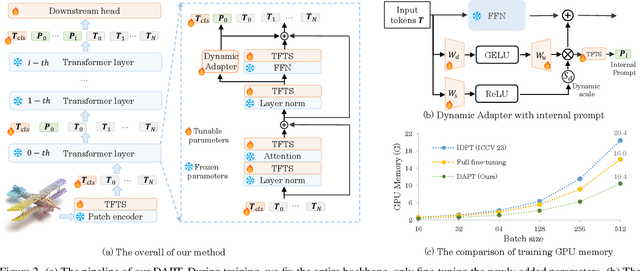
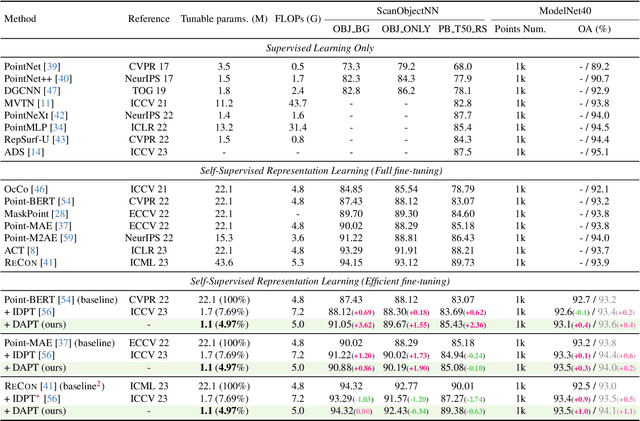
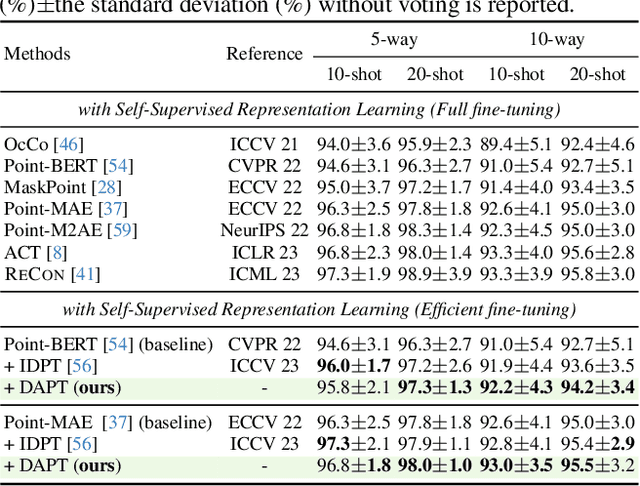
Point cloud analysis has achieved outstanding performance by transferring point cloud pre-trained models. However, existing methods for model adaptation usually update all model parameters, i.e., full fine-tuning paradigm, which is inefficient as it relies on high computational costs (e.g., training GPU memory) and massive storage space. In this paper, we aim to study parameter-efficient transfer learning for point cloud analysis with an ideal trade-off between task performance and parameter efficiency. To achieve this goal, we freeze the parameters of the default pre-trained models and then propose the Dynamic Adapter, which generates a dynamic scale for each token, considering the token significance to the downstream task. We further seamlessly integrate Dynamic Adapter with Prompt Tuning (DAPT) by constructing Internal Prompts, capturing the instance-specific features for interaction. Extensive experiments conducted on five challenging datasets demonstrate that the proposed DAPT achieves superior performance compared to the full fine-tuning counterparts while significantly reducing the trainable parameters and training GPU memory by 95% and 35%, respectively. Code is available at https://github.com/LMD0311/DAPT.
AVS-Net: Point Sampling with Adaptive Voxel Size for 3D Point Cloud Analysis
Feb 27, 2024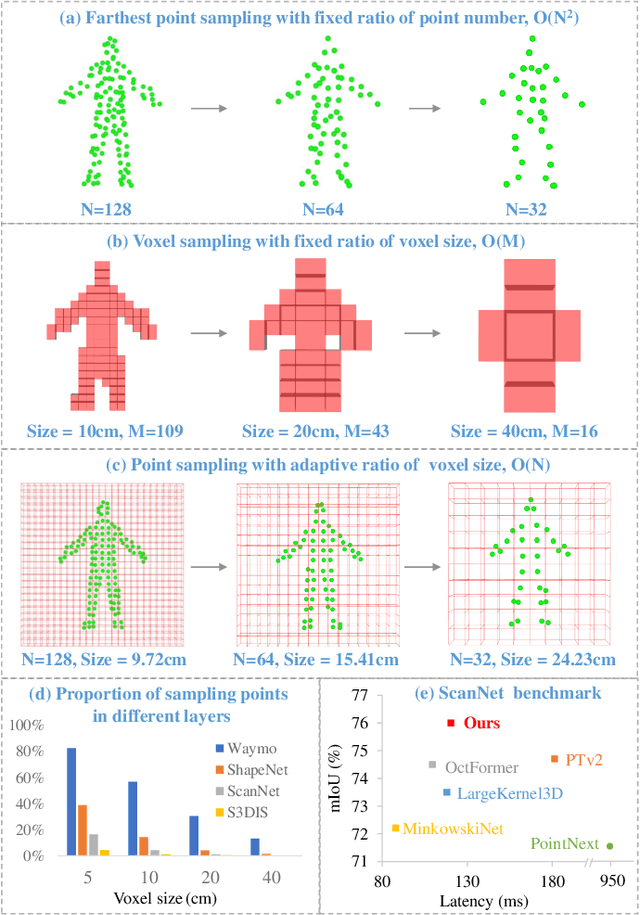
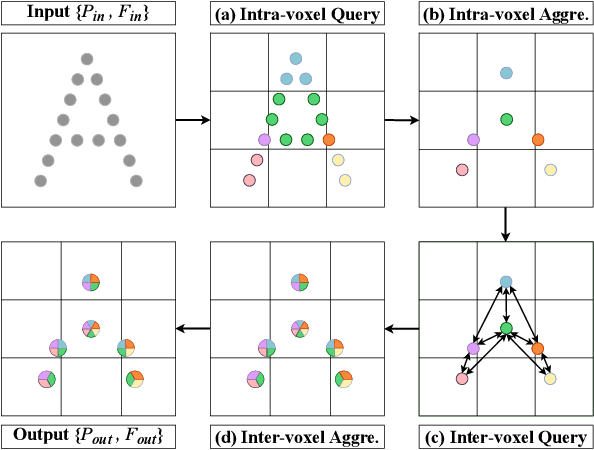
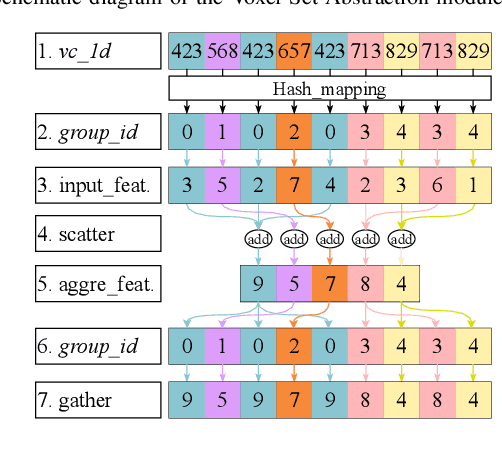
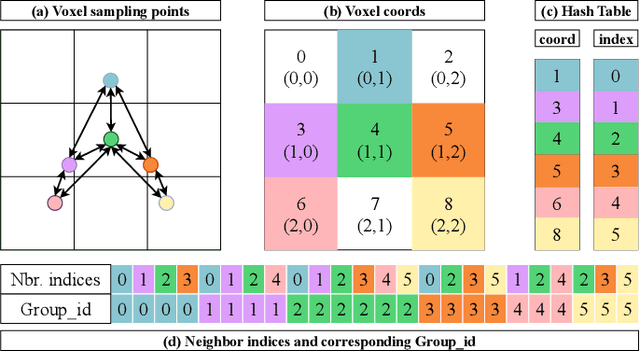
Efficient downsampling plays a crucial role in point cloud learning, particularly for large-scale 3D scenes. Existing downsampling methods either require a huge computational burden or sacrifice fine-grained geometric information. This paper presents an advanced sampler that achieves both high accuracy and efficiency. The proposed method utilizes voxel-based sampling as a foundation, but effectively addresses the challenges regarding voxel size determination and the preservation of critical geometric cues. Specifically, we propose a Voxel Adaptation Module that adaptively adjusts voxel sizes with the reference of point-based downsampling ratio. This ensures the sampling results exhibit a favorable distribution for comprehending various 3D objects or scenes. Additionally, we introduce a network compatible with arbitrary voxel sizes for sampling and feature extraction while maintaining high efficiency. Our method achieves state-of-the-art accuracy on the ShapeNetPart and ScanNet benchmarks with promising efficiency. Code will be available at https://github.com/yhc2021/AVS-Net.
PointMamba: A Simple State Space Model for Point Cloud Analysis
Feb 19, 2024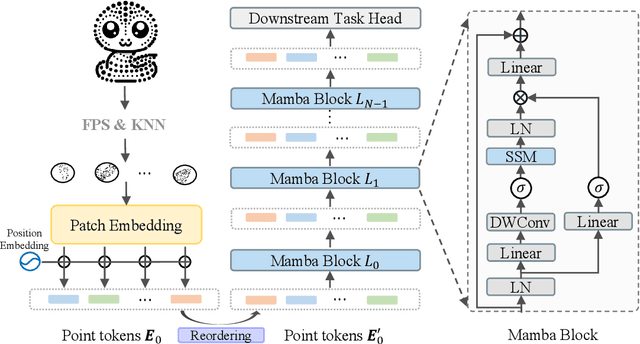
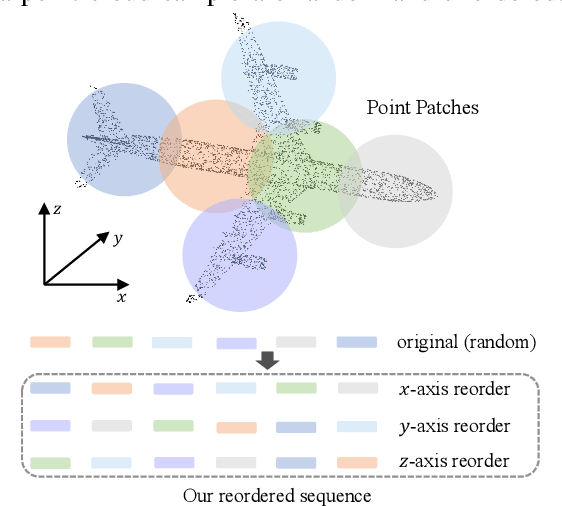
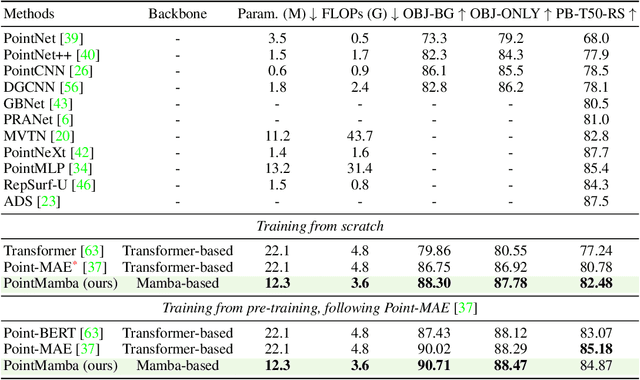
Transformers have become one of the foundational architectures in point cloud analysis tasks due to their excellent global modeling ability. However, the attention mechanism has quadratic complexity and is difficult to extend to long sequence modeling due to limited computational resources and so on. Recently, state space models (SSM), a new family of deep sequence models, have presented great potential for sequence modeling in NLP tasks. In this paper, taking inspiration from the success of SSM in NLP, we propose PointMamba, a framework with global modeling and linear complexity. Specifically, by taking embedded point patches as input, we proposed a reordering strategy to enhance SSM's global modeling ability by providing a more logical geometric scanning order. The reordered point tokens are then sent to a series of Mamba blocks to causally capture the point cloud structure. Experimental results show our proposed PointMamba outperforms the transformer-based counterparts on different point cloud analysis datasets, while significantly saving about 44.3% parameters and 25% FLOPs, demonstrating the potential option for constructing foundational 3D vision models. We hope our PointMamba can provide a new perspective for point cloud analysis. The code is available at https://github.com/LMD0311/PointMamba.
Diffusion-based 3D Object Detection with Random Boxes
Sep 05, 2023



3D object detection is an essential task for achieving autonomous driving. Existing anchor-based detection methods rely on empirical heuristics setting of anchors, which makes the algorithms lack elegance. In recent years, we have witnessed the rise of several generative models, among which diffusion models show great potential for learning the transformation of two distributions. Our proposed Diff3Det migrates the diffusion model to proposal generation for 3D object detection by considering the detection boxes as generative targets. During training, the object boxes diffuse from the ground truth boxes to the Gaussian distribution, and the decoder learns to reverse this noise process. In the inference stage, the model progressively refines a set of random boxes to the prediction results. We provide detailed experiments on the KITTI benchmark and achieve promising performance compared to classical anchor-based 3D detection methods.
CityTrack: Improving City-Scale Multi-Camera Multi-Target Tracking by Location-Aware Tracking and Box-Grained Matching
Jul 06, 2023



Multi-Camera Multi-Target Tracking (MCMT) is a computer vision technique that involves tracking multiple targets simultaneously across multiple cameras. MCMT in urban traffic visual analysis faces great challenges due to the complex and dynamic nature of urban traffic scenes, where multiple cameras with different views and perspectives are often used to cover a large city-scale area. Targets in urban traffic scenes often undergo occlusion, illumination changes, and perspective changes, making it difficult to associate targets across different cameras accurately. To overcome these challenges, we propose a novel systematic MCMT framework, called CityTrack. Specifically, we present a Location-Aware SCMT tracker which integrates various advanced techniques to improve its effectiveness in the MCMT task and propose a novel Box-Grained Matching (BGM) method for the ICA module to solve the aforementioned problems. We evaluated our approach on the public test set of the CityFlowV2 dataset and achieved an IDF1 of 84.91%, ranking 1st in the 2022 AI CITY CHALLENGE. Our experimental results demonstrate the effectiveness of our approach in overcoming the challenges posed by urban traffic scenes.
Understanding Depth Map Progressively: Adaptive Distance Interval Separation for Monocular 3d Object Detection
Jun 19, 2023
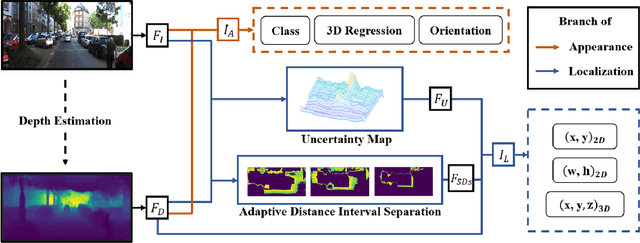
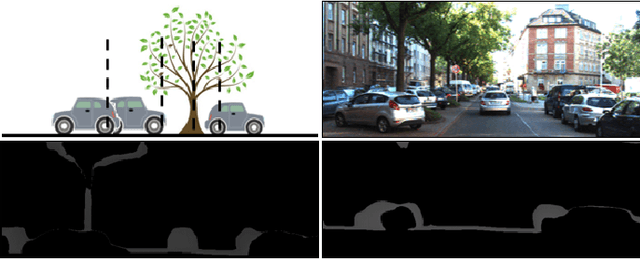
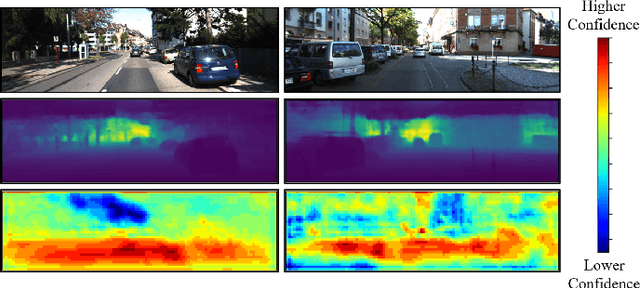
Monocular 3D object detection aims to locate objects in different scenes with just a single image. Due to the absence of depth information, several monocular 3D detection techniques have emerged that rely on auxiliary depth maps from the depth estimation task. There are multiple approaches to understanding the representation of depth maps, including treating them as pseudo-LiDAR point clouds, leveraging implicit end-to-end learning of depth information, or considering them as an image input. However, these methods have certain drawbacks, such as their reliance on the accuracy of estimated depth maps and suboptimal utilization of depth maps due to their image-based nature. While LiDAR-based methods and convolutional neural networks (CNNs) can be utilized for pseudo point clouds and depth maps, respectively, it is always an alternative. In this paper, we propose a framework named the Adaptive Distance Interval Separation Network (ADISN) that adopts a novel perspective on understanding depth maps, as a form that lies between LiDAR and images. We utilize an adaptive separation approach that partitions the depth map into various subgraphs based on distance and treats each of these subgraphs as an individual image for feature extraction. After adaptive separations, each subgraph solely contains pixels within a learned interval range. If there is a truncated object within this range, an evident curved edge will appear, which we can leverage for texture extraction using CNNs to obtain rich depth information in pixels. Meanwhile, to mitigate the inaccuracy of depth estimation, we designed an uncertainty module. To take advantage of both images and depth maps, we use different branches to learn localization detection tasks and appearance tasks separately.