 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-scale EM Benchmark for Multi-Organelle Instance Segmentation in the Wild
Jan 18, 2026Accurate instance-level segmentation of organelles in electron microscopy (EM) is critical for quantitative analysis of subcellular morphology and inter-organelle interactions. However, current benchmarks, based on small, curated datasets, fail to capture the inherent heterogeneity and large spatial context of in-the-wild EM data, imposing fundamental limitations on current patch-based methods. To address these limitations, we developed a large-scale, multi-source benchmark for multi-organelle instance segmentation, comprising over 100,000 2D EM images across variety cell types and five organelle classes that capture real-world variability. Dataset annotations were generated by our designed connectivity-aware Label Propagation Algorithm (3D LPA) with expert refinement. We further benchmarked several state-of-the-art models, including U-Net, SAM variants, and Mask2Former. Our results show several limitations: current models struggle to generalize across heterogeneous EM data and perform poorly on organelles with global, distributed morphologies (e.g., Endoplasmic Reticulum). These findings underscore the fundamental mismatch between local-context models and the challenge of modeling long-range structural continuity in the presence of real-world variability. The benchmark dataset and labeling tool will be publicly released soon.
RFAssigner: A Generic Label Assignment Strategy for Dense Object Detection
Jan 03, 2026Label assignment is a critical component in training dense object detectors. State-of-the-art methods typically assign each training sample a positive and a negative weight, optimizing the assignment scheme during training. However, these strategies often assign an insufficient number of positive samples to small objects, leading to a scale imbalance during training. To address this limitation, we introduce RFAssigner, a novel assignment strategy designed to enhance the multi-scale learning capabilities of dense detectors. RFAssigner first establishes an initial set of positive samples using a point-based prior. It then leverages a Gaussian Receptive Field (GRF) distance to measure the similarity between the GRFs of unassigned candidate locations and the ground-truth objects. Based on this metric, RFAssigner adaptively selects supplementary positive samples from the unassigned pool, promoting a more balanced learning process across object scales. Comprehensive experiments on three datasets with distinct object scale distributions validate the effectiveness and generalizability of our method. Notably, a single FCOS-ResNet-50 detector equipped with RFAssigner achieves state-of-the-art performance across all object scales, consistently outperforming existing strategies without requiring auxiliary modules or heuristics.
CARE What Fails: Contrastive Anchored-REflection for Verifiable Multimodal
Dec 22, 2025Group-relative reinforcement learning with verifiable rewards (RLVR) often wastes the most informative data it already has the failures. When all rollouts are wrong, gradients stall; when one happens to be correct, the update usually ignores why the others are close-but-wrong, and credit can be misassigned to spurious chains. We present CARE (Contrastive Anchored REflection), a failure-centric post-training framework for multimodal reasoning that turns errors into supervision. CARE combines: (i) an anchored-contrastive objective that forms a compact subgroup around the best rollout and a set of semantically proximate hard negatives, performs within-subgroup z-score normalization with negative-only scaling, and includes an all-negative rescue to prevent zero-signal batches; and (ii) Reflection-Guided Resampling (RGR), a one-shot structured self-repair that rewrites a representative failure and re-scores it with the same verifier, converting near-misses into usable positives without any test-time reflection. CARE improves accuracy and training smoothness while explicitly increasing the share of learning signal that comes from failures. On Qwen2.5-VL-7B, CARE lifts macro-averaged accuracy by 4.6 points over GRPO across six verifiable visual-reasoning benchmarks; with Qwen3-VL-8B it reaches competitive or state-of-the-art results on MathVista and MMMU-Pro under an identical evaluation protocol.
HybridTM: Combining Transformer and Mamba for 3D Semantic Segmentation
Jul 24, 2025Transformer-based methods have demonstrated remarkable capabilities in 3D semantic segmentation through their powerful attention mechanisms, but the quadratic complexity limits their modeling of long-range dependencies in large-scale point clouds. While recent Mamba-based approaches offer efficient processing with linear complexity, they struggle with feature representation when extracting 3D features. However, effectively combining these complementary strengths remains an open challenge in this field. In this paper, we propose HybridTM, the first hybrid architecture that integrates Transformer and Mamba for 3D semantic segmentation. In addition, we propose the Inner Layer Hybrid Strategy, which combines attention and Mamba at a finer granularity, enabling simultaneous capture of long-range dependencies and fine-grained local features. Extensive experiments demonstrate the effectiveness and generalization of our HybridTM on diverse indoor and outdoor datasets. Furthermore, our HybridTM achieves state-of-the-art performance on ScanNet, ScanNet200, and nuScenes benchmarks. The code will be made available at https://github.com/deepinact/HybridTM.
PDCNet: a benchmark and general deep learning framework for activity prediction of peptide-drug conjugates
Jun 15, 2025Peptide-drug conjugates (PDCs) represent a promising therapeutic avenue for human diseases, particularly in cancer treatment. Systematic elucidation of structure-activity relationships (SARs) and accurate prediction of the activity of PDCs are critical for the rational design and optimization of these conjugates. To this end, we carefully design and construct a benchmark PDCs dataset compiled from literature-derived collections and PDCdb database, and then develop PDCNet, the first unified deep learning framework for forecasting the activity of PDCs. The architecture systematically captures the complex factors underlying anticancer decisions of PDCs in real-word scenarios through a multi-level feature fusion framework that collaboratively characterizes and learns the features of peptides, linkers, and payloads. Leveraging a curated PDCs benchmark dataset, comprehensive evaluation results show that PDCNet demonstrates superior predictive capability, with the highest AUC, F1, MCC and BA scores of 0.9213, 0.7656, 0.7071 and 0.8388 for the test set, outperforming eight established traditional machine learning models. Multi-level validations, including 5-fold cross-validation, threshold testing, ablation studies, model interpretability analysis and external independent testing, further confirm the superiority, robustness, and usability of the PDCNet architecture. We anticipate that PDCNet represents a novel paradigm, incorporating both a benchmark dataset and advanced models, which can accelerate the design and discovery of new PDC-based therapeutic agents.
Generative Compositor for Few-Shot Visual Information Extraction
Mar 21, 2025Visual Information Extraction (VIE), aiming at extracting structured information from visually rich document images, plays a pivotal role in document processing. Considering various layouts, semantic scopes, and languages, VIE encompasses an extensive range of types, potentially numbering in the thousands. However, many of these types suffer from a lack of training data, which poses significant challenges. In this paper, we propose a novel generative model, named Generative Compositor, to address the challenge of few-shot VIE. The Generative Compositor is a hybrid pointer-generator network that emulates the operations of a compositor by retrieving words from the source text and assembling them based on the provided prompts. Furthermore, three pre-training strategies are employed to enhance the model's perception of spatial context information. Besides, a prompt-aware resampler is specially designed to enable efficient matching by leveraging the entity-semantic prior contained in prompts. The introduction of the prompt-based retrieval mechanism and the pre-training strategies enable the model to acquire more effective spatial and semantic clues with limited training samples. Experiments demonstrate that the proposed method achieves highly competitive results in the full-sample training, while notably outperforms the baseline in the 1-shot, 5-shot, and 10-shot settings.
Computation-Efficient and Recognition-Friendly 3D Point Cloud Privacy Protection
Mar 20, 2025



3D point cloud has been widely used in applications such as self-driving cars, robotics, CAD models, etc. To the best of our knowledge, these applications raised the issue of privacy leakage in 3D point clouds, which has not been studied well. Different from the 2D image privacy, which is related to texture and 2D geometric structure, the 3D point cloud is texture-less and only relevant to 3D geometric structure. In this work, we defined the 3D point cloud privacy problem and proposed an efficient privacy-preserving framework named PointFlowGMM that can support downstream classification and segmentation tasks without seeing the original data. Using a flow-based generative model, the point cloud is projected into a latent Gaussian mixture distributed subspace. We further designed a novel angular similarity loss to obfuscate the original geometric structure and reduce the model size from 767MB to 120MB without a decrease in recognition performance. The projected point cloud in the latent space is orthogonally rotated randomly to further protect the original geometric structure, the class-to-class relationship is preserved after rotation, thus, the protected point cloud can support the recognition task. We evaluated our model on multiple datasets and achieved comparable recognition results on encrypted point clouds compared to the original point clouds.
Retrieval-guided Cross-view Image Synthesis
Nov 29, 2024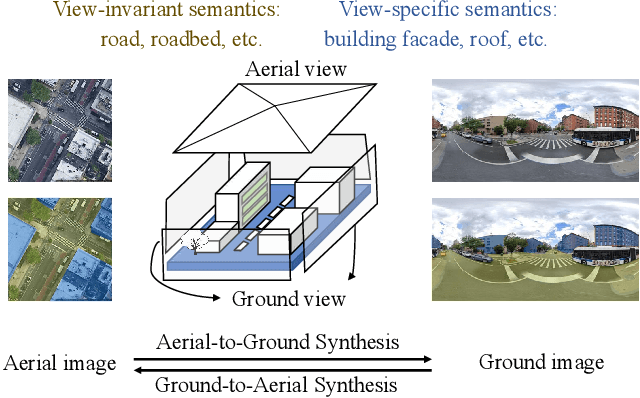


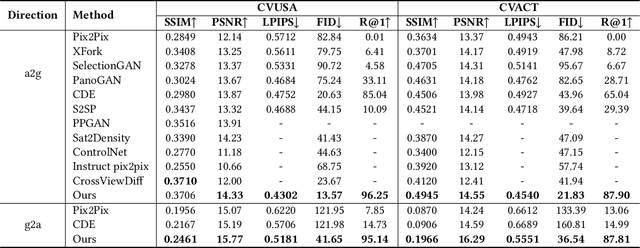
Cross-view image synthesis involves generating new images of a scene from different viewpoints or perspectives, given one input image from other viewpoints. Despite recent advancements, there are several limitations in existing methods: 1) reliance on additional data such as semantic segmentation maps or preprocessing modules to bridge the domain gap; 2) insufficient focus on view-specific semantics, leading to compromised image quality and realism; and 3) a lack of diverse datasets representing complex urban environments. To tackle these challenges, we propose: 1) a novel retrieval-guided framework that employs a retrieval network as an embedder to address the domain gap; 2) an innovative generator that enhances semantic consistency and diversity specific to the target view to improve image quality and realism; and 3) a new dataset, VIGOR-GEN, providing diverse cross-view image pairs in urban settings to enrich dataset diversity. Extensive experiments on well-known CVUSA, CVACT, and new VIGOR-GEN datasets demonstrate that our method generates images of superior realism, significantly outperforming current leading approaches, particularly in SSIM and FID evaluations.
R-CoT: Reverse Chain-of-Thought Problem Generation for Geometric Reasoning in Large Multimodal Models
Oct 23, 2024



Existing Large Multimodal Models (LMMs) struggle with mathematical geometric reasoning due to a lack of high-quality image-text paired data. Current geometric data generation approaches, which apply preset templates to generate geometric data or use Large Language Models (LLMs) to rephrase questions and answers (Q&A), unavoidably limit data accuracy and diversity. To synthesize higher-quality data, we propose a two-stage Reverse Chain-of-Thought (R-CoT) geometry problem generation pipeline. First, we introduce GeoChain to produce high-fidelity geometric images and corresponding descriptions highlighting relations among geometric elements. We then design a Reverse A&Q method that reasons step-by-step based on the descriptions and generates questions in reverse from the reasoning results. Experiments demonstrate that the proposed method brings significant and consistent improvements on multiple LMM baselines, achieving new performance records in the 2B, 7B, and 8B settings. Notably, R-CoT-8B significantly outperforms previous state-of-the-art open-source mathematical models by 16.6% on MathVista and 9.2% on GeoQA, while also surpassing the closed-source model GPT-4o by an average of 13% across both datasets. The code is available at https://github.com/dle666/R-CoT.
More Than Positive and Negative: Communicating Fine Granularity in Medical Diagnosis
Aug 05, 2024With the advance of deep learning, much progress has been made in building powerful artificial intelligence (AI) systems for automatic Chest X-ray (CXR) analysis. Most existing AI models are trained to be a binary classifier with the aim of distinguishing positive and negative cases. However, a large gap exists between the simple binary setting and complicated real-world medical scenarios. In this work, we reinvestigate the problem of automatic radiology diagnosis. We first observe that there is considerable diversity among cases within the positive class, which means simply classifying them as positive loses many important details. This motivates us to build AI models that can communicate fine-grained knowledge from medical images like human experts. To this end, we first propose a new benchmark on fine granularity learning from medical images. Specifically, we devise a division rule based on medical knowledge to divide positive cases into two subcategories, namely atypical positive and typical positive. Then, we propose a new metric termed AUC$^\text{FG}$ on the two subcategories for evaluation of the ability to separate them apart. With the proposed benchmark, we encourage the community to develop AI diagnosis systems that could better learn fine granularity from medical images. Last, we propose a simple risk modulation approach to this problem by only using coarse labels in training. Empirical results show that despite its simplicity, the proposed method achieves superior performance and thus serves as a strong baseline.