 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhoneWorld: Scaling Phone-Use Agent Environments
May 28, 2026A central bottleneck for phone-use agents is that controllable, reproducible environments covering real mobile behavior are hard to build at scale. Existing mobile-agent benchmarks have made important progress on evaluation, but they do not by themselves provide a scalable way to construct many new phone-use environments. We present PhoneWorld, a reusable pipeline that converts real GUI trajectories and screenshots into controllable phone-use environments, executable tasks, automatic verifiers, and training rollouts. Rather than hand-building one mobile benchmark at a time, PhoneWorld uses real trajectories to recover which screens matter, how screens connect, which interactions must change environment state, and which user goals admit automatic verification. From these signals, it builds runnable mock Android apps backed by read-only app content and mutable state, then derives executable tasks, rule-based verifiers, and training rollouts from the same environments. In its current instantiation, PhoneWorld covers 34 apps across 16 domains, spanning common consumer mobile behaviors such as search, browsing, shopping, booking, media, and social interaction. Under a fixed training budget, replacing 10K steps from an auxiliary AndroidWorld corpus in an AndroidWorld-based baseline with broad PhoneWorld supervision improves all four evaluation benchmarks at once, raising HYMobileBench by 17.7 points, AndroidControl by 6.0 points, AndroidWorld by 14.7 points, and PhoneWorld by 52.5 points. We then study two additional scaling questions: increasing the amount of PhoneWorld supervision strongly improves PhoneWorld performance, and under a fixed PhoneWorld budget, expanding app coverage yields even larger gains. Overall, PhoneWorld shifts the focus from building one mobile benchmark at a time to scaling the supply of phone-use environments themselves.
Towards Resilient and Autonomous Networks: A BlueSky Vision on AI-Native 6G
May 20, 2026The proliferation of emerging applications, such as autonomous driving and immersive experiences, demands cellular networks that are not only faster, but fundamentally more resilient and autonomous. This paper presents a BlueSky vision on how Artificial Intelligence will be natively integrated into 6G, shifting the paradigm from \underline{Network for AI} to \underline{AI for Network}. We envision that, unlike 5G's reliance on scattered, ad-hoc models each trained for a single task, native AI in the 6G era will be anchored by a foundation model and and orchestrated via collaborative multi-agent systems, framing network management as a unified, multi-modal, multi-task optimization problem. Built on this vision, we outline two transformative directions. The first focuses on developing a 6G foundation model as a unified backbone, with task-specific knowledge distilled into compact models suited for diverse edge deployments. The second advances multi-agent systems designed to autonomously diagnose, maintain, and recover networks with minimal human intervention. These directions chart a roadmap for 6G to evolve into an intelligent, self-sustaining communication infrastructure.
Channel Knowledge Map-Enabled NLoS ISAC Localization
Apr 08, 2026Accurate localization in non-line-of-sight (NLoS) environments remains challenging even with both angle-of-arrival (AoA) and time-of-arrival (ToA) measurements. In complex urban scenarios, the absence of line-of-sight (LoS) paths and the lack of environment prior knowledge make geometric based localization methods inapplicable, while prior-based approach such as fingerprinting is sensitive to environmental perturbations. This paper proposes a novel environment-aware localization framework enabled by the emerging concept called channel knowledge map (CKM). In the offline stage, AoA-ToA path signatures are learned by the CKM, with each path mapped to one candidate scatterer, thereby forming geometric priors within the environment. In the online stage, observed paths are matched to the CKM to extract high-confidence scatterers. Nonlinear least squares (NLS) method is then applied to jointly estimate the user and dominant scatterer locations. Even with imperfect CSI matching, geometric feasibility consistent with CKM scatterer priors provides corrective information and suppresses ambiguity. Simulations demonstrate that the proposed scheme outperforms fingerprinting and offers a robust and scalable solution to address the challenging NLoS localization for integrated sensing and communication (ISAC) systems.
E-VAds: An E-commerce Short Videos Understanding Benchmark for MLLMs
Feb 09, 2026E-commerce short videos represent a high-revenue segment of the online video industry characterized by a goal-driven format and dense multi-modal signals. Current models often struggle with these videos because existing benchmarks focus primarily on general-purpose tasks and neglect the reasoning of commercial intent. In this work, we first propose a \textbf{multi-modal information density assessment framework} to quantify the complexity of this domain. Our evaluation reveals that e-commerce content exhibits substantially higher density across visual, audio, and textual modalities compared to mainstream datasets, establishing a more challenging frontier for video understanding. To address this gap, we introduce \textbf{E-commerce Video Ads Benchmark (E-VAds)}, which is the first benchmark specifically designed for e-commerce short video understanding. We curated 3,961 high-quality videos from Taobao covering a wide range of product categories and used a multi-agent system to generate 19,785 open-ended Q&A pairs. These questions are organized into two primary dimensions, namely Perception and Cognition and Reasoning, which consist of five distinct tasks. Finally, we develop \textbf{E-VAds-R1}, an RL-based reasoning model featuring a multi-grained reward design called \textbf{MG-GRPO}. This strategy provides smooth guidance for early exploration while creating a non-linear incentive for expert-level precision. Experimental results demonstrate that E-VAds-R1 achieves a 109.2% performance gain in commercial intent reasoning with only a few hundred training samples.
A Generalist Foundation Model for Total-body PET/CT Enables Diagnostic Reporting and System-wide Metabolic Profiling
Jan 19, 2026Total-body PET/CT enables system-wide molecular imaging, but heterogeneous anatomical and metabolic signals, approximately 2 m axial coverage, and structured radiology semantics challenge existing medical AI models that assume single-modality inputs, localized fields of view, and coarse image-text alignment. We introduce SDF-HOLO (Systemic Dual-stream Fusion Holo Model), a multimodal foundation model for holistic total-body PET/CT, pre-trained on more than 10,000 patients. SDF-HOLO decouples CT and PET representation learning with dual-stream encoders and couples them through a cross-modal interaction module, allowing anatomical context to refine PET aggregation while metabolic saliency guides subtle morphological reasoning. To model long-range dependencies across the body, hierarchical context modeling combines efficient local windows with global attention. To bridge voxels and clinical language, we use anatomical segmentation masks as explicit semantic anchors and perform voxel-mask-text alignment during pre-training. Across tumor segmentation, low-dose lesion detection, and multilingual diagnostic report generation, SDF-HOLO outperforms strong task-specific and clinical-reference baselines while reducing localization errors and hallucinated findings. Beyond focal interpretation, the model enables system-wide metabolic profiling and reveals tumor-associated fingerprints of inter-organ metabolic network interactions, providing a scalable computational foundation for total-body PET/CT diagnostics and system-level precision oncology.
OpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
Enhanced Whole Page Optimization via Mixed-Grained Reward Mechanism-Adapted Language Models
Jun 10, 2025Optimizing the presentation of search and recommendation results is crucial to enhancing user experience and engagement. Whole Page Optimization (WPO) plays a pivotal role in this process, as it directly influences how information is surfaced to users. While Pre-trained Large Language Models (LLMs) have demonstrated remarkable capabilities in generating coherent and contextually relevant content, fine-tuning these models for complex tasks like WPO presents challenges. Specifically, the need for extensive human-annotated data to mitigate issues such as hallucinations and model instability can be prohibitively expensive, especially in large-scale systems that interact with millions of items daily. In this work, we address the challenge of fine-tuning LLMs for WPO by using user feedback as the supervision. Unlike manually labeled datasets, user feedback is inherently noisy and less precise. To overcome this, we propose a reward-based fine-tuning approach, PageLLM, which employs a mixed-grained reward mechanism that combines page-level and item-level rewards. The page-level reward evaluates the overall quality and coherence, while the item-level reward focuses on the accuracy and relevance of key recommendations. This dual-reward structure ensures that both the holistic presentation and the critical individual components are optimized. We validate PageLLM on both public and industrial datasets. PageLLM outperforms baselines and achieves a 0.44\% GMV increase in an online A/B test with over 10 million users, demonstrating its real-world impact.
Stability-based Generalization Analysis of Randomized Coordinate Descent for Pairwise Learning
Mar 03, 2025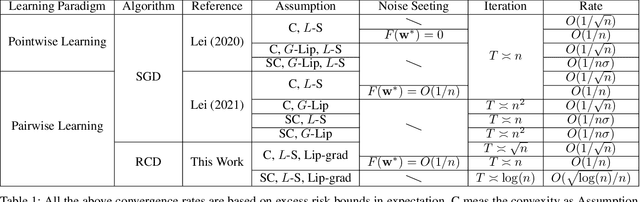
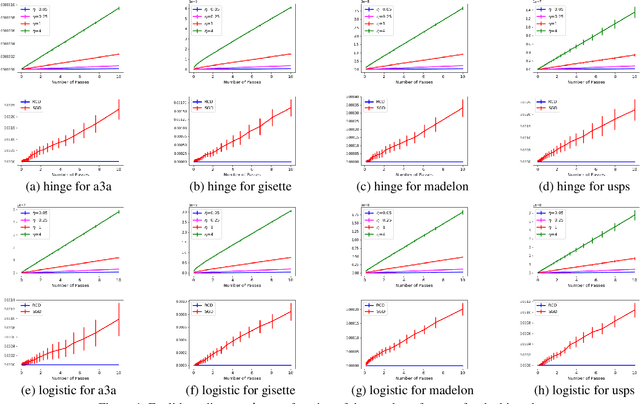
Pairwise learning includes various machine learning tasks, with ranking and metric learning serving as the primary representatives. While randomized coordinate descent (RCD) is popular in various learning problems, there is much less theoretical analysis on the generalization behavior of models trained by RCD, especially under the pairwise learning framework. In this paper, we consider the generalization of RCD for pairwise learning. We measure the on-average argument stability for both convex and strongly convex objective functions, based on which we develop generalization bounds in expectation. The early-stopping strategy is adopted to quantify the balance between estimation and optimization. Our analysis further incorporates the low-noise setting into the excess risk bound to achieve the optimistic bound as $O(1/n)$, where $n$ is the sample size.
R-CoT: Reverse Chain-of-Thought Problem Generation for Geometric Reasoning in Large Multimodal Models
Oct 23, 2024



Existing Large Multimodal Models (LMMs) struggle with mathematical geometric reasoning due to a lack of high-quality image-text paired data. Current geometric data generation approaches, which apply preset templates to generate geometric data or use Large Language Models (LLMs) to rephrase questions and answers (Q&A), unavoidably limit data accuracy and diversity. To synthesize higher-quality data, we propose a two-stage Reverse Chain-of-Thought (R-CoT) geometry problem generation pipeline. First, we introduce GeoChain to produce high-fidelity geometric images and corresponding descriptions highlighting relations among geometric elements. We then design a Reverse A&Q method that reasons step-by-step based on the descriptions and generates questions in reverse from the reasoning results. Experiments demonstrate that the proposed method brings significant and consistent improvements on multiple LMM baselines, achieving new performance records in the 2B, 7B, and 8B settings. Notably, R-CoT-8B significantly outperforms previous state-of-the-art open-source mathematical models by 16.6% on MathVista and 9.2% on GeoQA, while also surpassing the closed-source model GPT-4o by an average of 13% across both datasets. The code is available at https://github.com/dle666/R-CoT.
Merging Multiple Datasets for Improved Appearance-Based Gaze Estimation
Sep 02, 2024Multiple datasets have been created for training and testing appearance-based gaze estimators. Intuitively, more data should lead to better performance. However, combining datasets to train a single esti-mator rarely improves gaze estimation performance. One reason may be differences in the experimental protocols used to obtain the gaze sam-ples, resulting in differences in the distributions of head poses, gaze an-gles, illumination, etc. Another reason may be the inconsistency between methods used to define gaze angles (label mismatch). We propose two innovations to improve the performance of gaze estimation by leveraging multiple datasets, a change in the estimator architecture and the intro-duction of a gaze adaptation module. Most state-of-the-art estimators merge information extracted from images of the two eyes and the entire face either in parallel or combine information from the eyes first then with the face. Our proposed Two-stage Transformer-based Gaze-feature Fusion (TTGF) method uses transformers to merge information from each eye and the face separately and then merge across the two eyes. We argue that this improves head pose invariance since changes in head pose affect left and right eye images in different ways. Our proposed Gaze Adaptation Module (GAM) method handles annotation inconsis-tency by applying a Gaze Adaption Module for each dataset to correct gaze estimates from a single shared estimator. This enables us to combine information across datasets despite differences in labeling. Our experi-ments show that these innovations improve gaze estimation performance over the SOTA both individually and collectively (by 10% - 20%). Our code is available at https://github.com/HKUST-NISL/GazeSetMerge.