 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControl LLM: Controlled Evolution for Intelligence Retention in LLM
Jan 19, 2025



Large Language Models (LLMs) demand significant computational resources, making it essential to enhance their capabilities without retraining from scratch. A key challenge in this domain is \textit{catastrophic forgetting} (CF), which hampers performance during Continuous Pre-training (CPT) and Continuous Supervised Fine-Tuning (CSFT). We propose \textbf{Control LLM}, a novel approach that leverages parallel pre-trained and expanded transformer blocks, aligning their hidden-states through interpolation strategies This method effectively preserves performance on existing tasks while seamlessly integrating new knowledge. Extensive experiments demonstrate the effectiveness of Control LLM in both CPT and CSFT. On Llama3.1-8B-Instruct, it achieves significant improvements in mathematical reasoning ($+14.4\%$ on Math-Hard) and coding performance ($+10\%$ on MBPP-PLUS). On Llama3.1-8B, it enhances multilingual capabilities ($+10.6\%$ on C-Eval, $+6.8\%$ on CMMLU, and $+30.2\%$ on CMMLU-0shot-CoT). It surpasses existing methods and achieves SOTA among open-source models tuned from the same base model, using substantially less data and compute. Crucially, these gains are realized while preserving strong original capabilities, with minimal degradation ($<4.3\% \text{on MMLU}$) compared to $>35\%$ in open-source Math and Coding models. This approach has been successfully deployed in LinkedIn's GenAI-powered job seeker and Ads unit products. To support further research, we release the training and evaluation code (\url{https://github.com/linkedin/ControlLLM}) along with models trained on public datasets (\url{ https://huggingface.co/ControlLLM}) to the community.
Learning to Retrieve for Job Matching
Feb 21, 2024



Web-scale search systems typically tackle the scalability challenge with a two-step paradigm: retrieval and ranking. The retrieval step, also known as candidate selection, often involves extracting standardized entities, creating an inverted index, and performing term matching for retrieval. Such traditional methods require manual and time-consuming development of query models. In this paper, we discuss applying learning-to-retrieve technology to enhance LinkedIns job search and recommendation systems. In the realm of promoted jobs, the key objective is to improve the quality of applicants, thereby delivering value to recruiter customers. To achieve this, we leverage confirmed hire data to construct a graph that evaluates a seeker's qualification for a job, and utilize learned links for retrieval. Our learned model is easy to explain, debug, and adjust. On the other hand, the focus for organic jobs is to optimize seeker engagement. We accomplished this by training embeddings for personalized retrieval, fortified by a set of rules derived from the categorization of member feedback. In addition to a solution based on a conventional inverted index, we developed an on-GPU solution capable of supporting both KNN and term matching efficiently.
LinkSAGE: Optimizing Job Matching Using Graph Neural Networks
Feb 20, 2024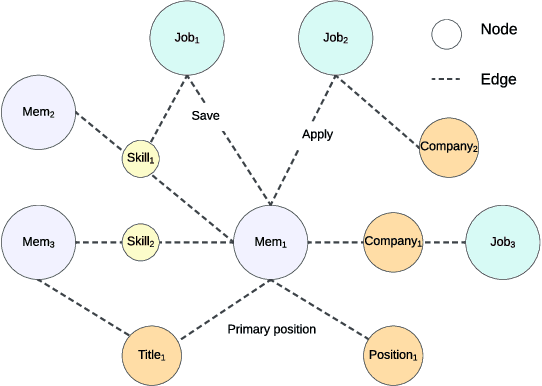

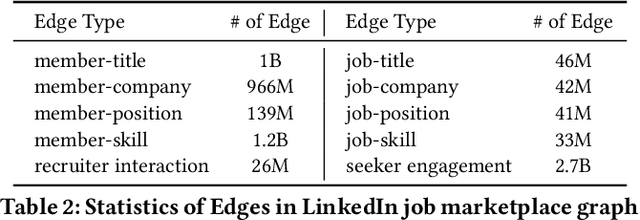

We present LinkSAGE, an innovative framework that integrates Graph Neural Networks (GNNs) into large-scale personalized job matching systems, designed to address the complex dynamics of LinkedIns extensive professional network. Our approach capitalizes on a novel job marketplace graph, the largest and most intricate of its kind in industry, with billions of nodes and edges. This graph is not merely extensive but also richly detailed, encompassing member and job nodes along with key attributes, thus creating an expansive and interwoven network. A key innovation in LinkSAGE is its training and serving methodology, which effectively combines inductive graph learning on a heterogeneous, evolving graph with an encoder-decoder GNN model. This methodology decouples the training of the GNN model from that of existing Deep Neural Nets (DNN) models, eliminating the need for frequent GNN retraining while maintaining up-to-date graph signals in near realtime, allowing for the effective integration of GNN insights through transfer learning. The subsequent nearline inference system serves the GNN encoder within a real-world setting, significantly reducing online latency and obviating the need for costly real-time GNN infrastructure. Validated across multiple online A/B tests in diverse product scenarios, LinkSAGE demonstrates marked improvements in member engagement, relevance matching, and member retention, confirming its generalizability and practical impact.
LiGNN: Graph Neural Networks at LinkedIn
Feb 17, 2024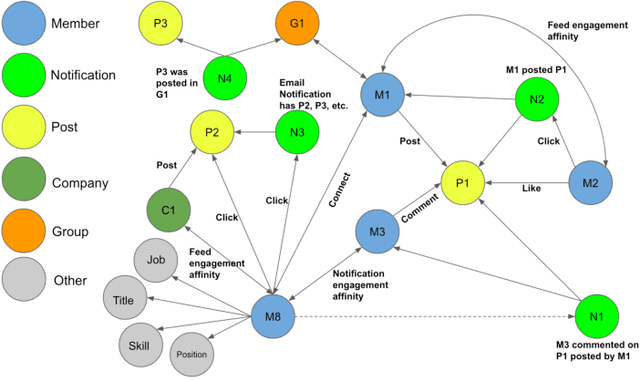

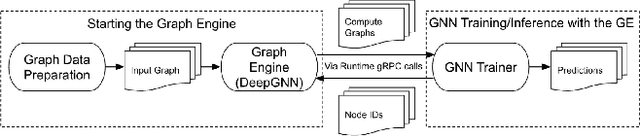

In this paper, we present LiGNN, a deployed large-scale Graph Neural Networks (GNNs) Framework. We share our insight on developing and deployment of GNNs at large scale at LinkedIn. We present a set of algorithmic improvements to the quality of GNN representation learning including temporal graph architectures with long term losses, effective cold start solutions via graph densification, ID embeddings and multi-hop neighbor sampling. We explain how we built and sped up by 7x our large-scale training on LinkedIn graphs with adaptive sampling of neighbors, grouping and slicing of training data batches, specialized shared-memory queue and local gradient optimization. We summarize our deployment lessons and learnings gathered from A/B test experiments. The techniques presented in this work have contributed to an approximate relative improvements of 1% of Job application hearing back rate, 2% Ads CTR lift, 0.5% of Feed engaged daily active users, 0.2% session lift and 0.1% weekly active user lift from people recommendation. We believe that this work can provide practical solutions and insights for engineers who are interested in applying Graph neural networks at large scale.
LiRank: Industrial Large Scale Ranking Models at LinkedIn
Feb 10, 2024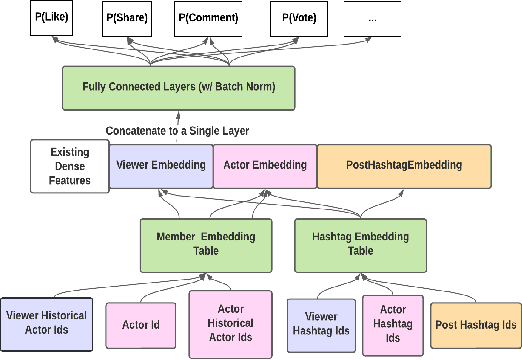

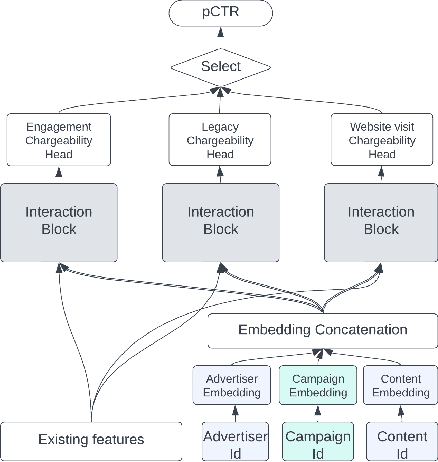

We present LiRank, a large-scale ranking framework at LinkedIn that brings to production state-of-the-art modeling architectures and optimization methods. We unveil several modeling improvements, including Residual DCN, which adds attention and residual connections to the famous DCNv2 architecture. We share insights into combining and tuning SOTA architectures to create a unified model, including Dense Gating, Transformers and Residual DCN. We also propose novel techniques for calibration and describe how we productionalized deep learning based explore/exploit methods. To enable effective, production-grade serving of large ranking models, we detail how to train and compress models using quantization and vocabulary compression. We provide details about the deployment setup for large-scale use cases of Feed ranking, Jobs Recommendations, and Ads click-through rate (CTR) prediction. We summarize our learnings from various A/B tests by elucidating the most effective technical approaches. These ideas have contributed to relative metrics improvements across the board at LinkedIn: +0.5% member sessions in the Feed, +1.76% qualified job applications for Jobs search and recommendations, and +4.3% for Ads CTR. We hope this work can provide practical insights and solutions for practitioners interested in leveraging large-scale deep ranking systems.
Incremental Learning for Personalized Recommender Systems
Aug 13, 2021
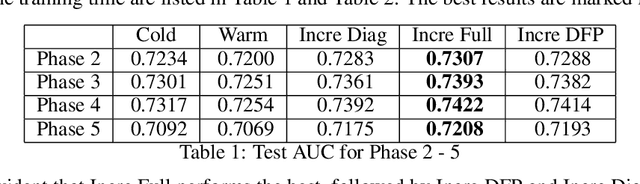
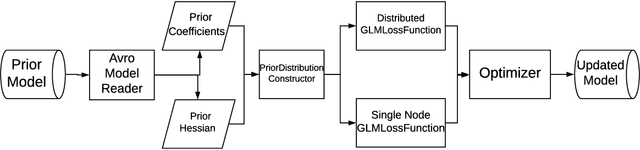

Ubiquitous personalized recommender systems are built to achieve two seemingly conflicting goals, to serve high quality content tailored to individual user's taste and to adapt quickly to the ever changing environment. The former requires a complex machine learning model that is trained on a large amount of data; the latter requires frequent update to the model. We present an incremental learning solution to provide both the training efficiency and the model quality. Our solution is based on sequential Bayesian update and quadratic approximation. Our focus is on large-scale personalized logistic regression models, with extensions to deep learning models. This paper fills in the gap between the theory and the practice by addressing a few implementation challenges that arise when applying incremental learning to large personalized recommender systems. Detailed offline and online experiments demonstrated our approach can significantly shorten the training time while maintaining the model accuracy. The solution is deployed in LinkedIn and directly applicable to industrial scale recommender systems.