 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiMAML: Personalization of Deep Recommender Models via Meta Learning
Feb 23, 2024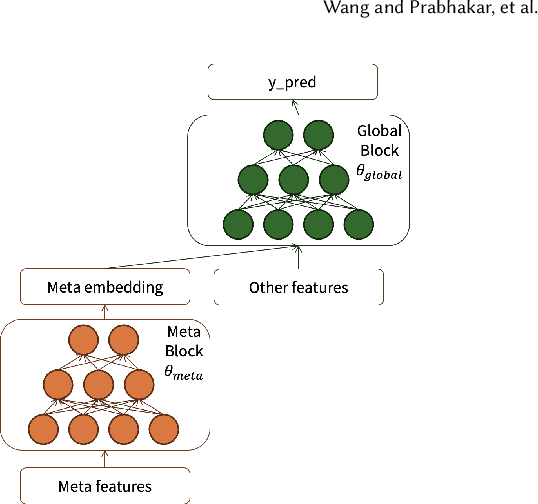


In the realm of recommender systems, the ubiquitous adoption of deep neural networks has emerged as a dominant paradigm for modeling diverse business objectives. As user bases continue to expand, the necessity of personalization and frequent model updates have assumed paramount significance to ensure the delivery of relevant and refreshed experiences to a diverse array of members. In this work, we introduce an innovative meta-learning solution tailored to the personalization of models for individual members and other entities, coupled with the frequent updates based on the latest user interaction signals. Specifically, we leverage the Model-Agnostic Meta Learning (MAML) algorithm to adapt per-task sub-networks using recent user interaction data. Given the near infeasibility of productionizing original MAML-based models in online recommendation systems, we propose an efficient strategy to operationalize meta-learned sub-networks in production, which involves transforming them into fixed-sized vectors, termed meta embeddings, thereby enabling the seamless deployment of models with hundreds of billions of parameters for online serving. Through extensive experimentation on production data drawn from various applications at LinkedIn, we demonstrate that the proposed solution consistently outperforms the baseline models of those applications, including strong baselines such as using wide-and-deep ID based personalization approach. Our approach has enabled the deployment of a range of highly personalized AI models across diverse LinkedIn applications, leading to substantial improvements in business metrics as well as refreshed experience for our members.
LiGNN: Graph Neural Networks at LinkedIn
Feb 17, 2024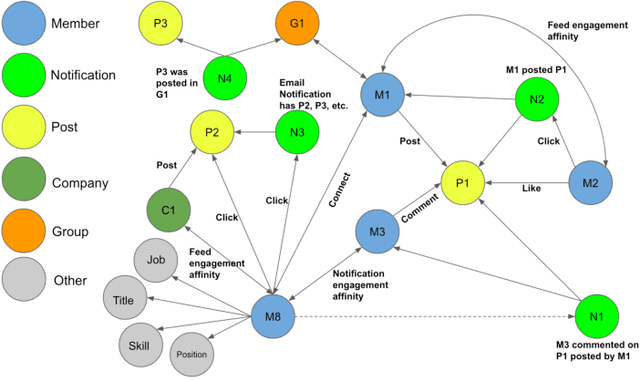

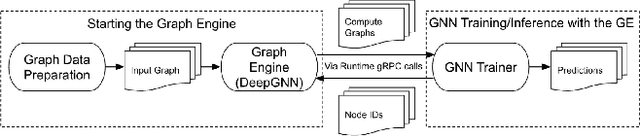

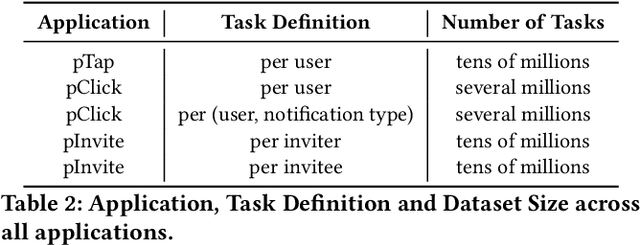
In this paper, we present LiGNN, a deployed large-scale Graph Neural Networks (GNNs) Framework. We share our insight on developing and deployment of GNNs at large scale at LinkedIn. We present a set of algorithmic improvements to the quality of GNN representation learning including temporal graph architectures with long term losses, effective cold start solutions via graph densification, ID embeddings and multi-hop neighbor sampling. We explain how we built and sped up by 7x our large-scale training on LinkedIn graphs with adaptive sampling of neighbors, grouping and slicing of training data batches, specialized shared-memory queue and local gradient optimization. We summarize our deployment lessons and learnings gathered from A/B test experiments. The techniques presented in this work have contributed to an approximate relative improvements of 1% of Job application hearing back rate, 2% Ads CTR lift, 0.5% of Feed engaged daily active users, 0.2% session lift and 0.1% weekly active user lift from people recommendation. We believe that this work can provide practical solutions and insights for engineers who are interested in applying Graph neural networks at large scale.
LiRank: Industrial Large Scale Ranking Models at LinkedIn
Feb 10, 2024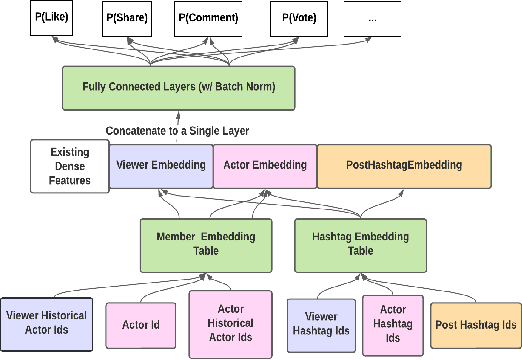

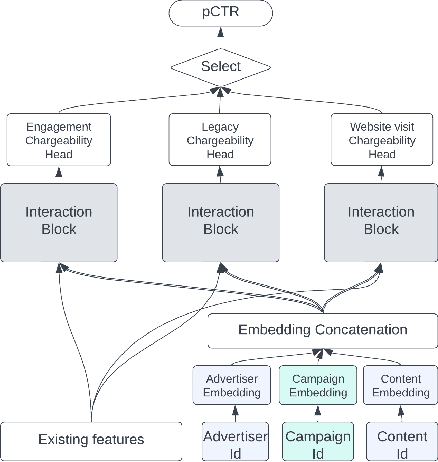

We present LiRank, a large-scale ranking framework at LinkedIn that brings to production state-of-the-art modeling architectures and optimization methods. We unveil several modeling improvements, including Residual DCN, which adds attention and residual connections to the famous DCNv2 architecture. We share insights into combining and tuning SOTA architectures to create a unified model, including Dense Gating, Transformers and Residual DCN. We also propose novel techniques for calibration and describe how we productionalized deep learning based explore/exploit methods. To enable effective, production-grade serving of large ranking models, we detail how to train and compress models using quantization and vocabulary compression. We provide details about the deployment setup for large-scale use cases of Feed ranking, Jobs Recommendations, and Ads click-through rate (CTR) prediction. We summarize our learnings from various A/B tests by elucidating the most effective technical approaches. These ideas have contributed to relative metrics improvements across the board at LinkedIn: +0.5% member sessions in the Feed, +1.76% qualified job applications for Jobs search and recommendations, and +4.3% for Ads CTR. We hope this work can provide practical insights and solutions for practitioners interested in leveraging large-scale deep ranking systems.
Incremental Learning for Personalized Recommender Systems
Aug 13, 2021
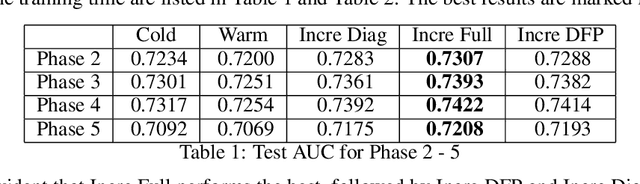
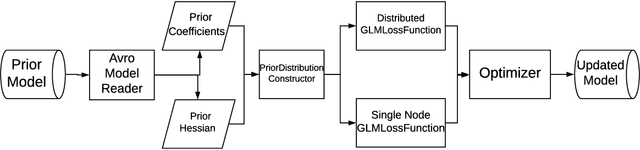

Ubiquitous personalized recommender systems are built to achieve two seemingly conflicting goals, to serve high quality content tailored to individual user's taste and to adapt quickly to the ever changing environment. The former requires a complex machine learning model that is trained on a large amount of data; the latter requires frequent update to the model. We present an incremental learning solution to provide both the training efficiency and the model quality. Our solution is based on sequential Bayesian update and quadratic approximation. Our focus is on large-scale personalized logistic regression models, with extensions to deep learning models. This paper fills in the gap between the theory and the practice by addressing a few implementation challenges that arise when applying incremental learning to large personalized recommender systems. Detailed offline and online experiments demonstrated our approach can significantly shorten the training time while maintaining the model accuracy. The solution is deployed in LinkedIn and directly applicable to industrial scale recommender systems.
An Empirical Bayes Approach for High Dimensional Classification
Feb 16, 2017



We propose an empirical Bayes estimator based on Dirichlet process mixture model for estimating the sparse normalized mean difference, which could be directly applied to the high dimensional linear classification. In theory, we build a bridge to connect the estimation error of the mean difference and the misclassification error, also provide sufficient conditions of sub-optimal classifiers and optimal classifiers. In implementation, a variational Bayes algorithm is developed to compute the posterior efficiently and could be parallelized to deal with the ultra-high dimensional case.