 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiMAML: Personalization of Deep Recommender Models via Meta Learning
Feb 23, 2024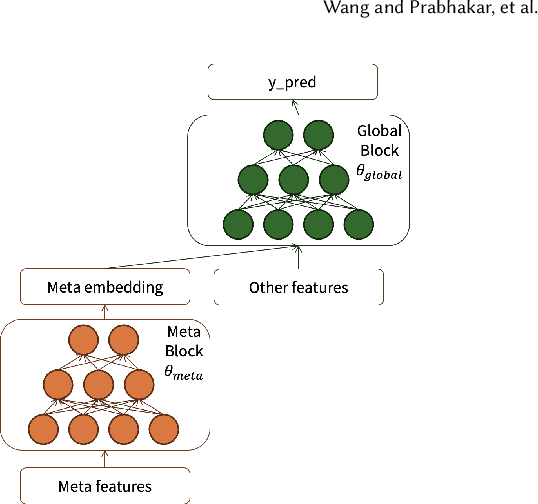

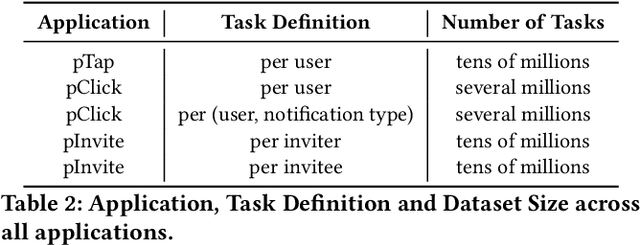

In the realm of recommender systems, the ubiquitous adoption of deep neural networks has emerged as a dominant paradigm for modeling diverse business objectives. As user bases continue to expand, the necessity of personalization and frequent model updates have assumed paramount significance to ensure the delivery of relevant and refreshed experiences to a diverse array of members. In this work, we introduce an innovative meta-learning solution tailored to the personalization of models for individual members and other entities, coupled with the frequent updates based on the latest user interaction signals. Specifically, we leverage the Model-Agnostic Meta Learning (MAML) algorithm to adapt per-task sub-networks using recent user interaction data. Given the near infeasibility of productionizing original MAML-based models in online recommendation systems, we propose an efficient strategy to operationalize meta-learned sub-networks in production, which involves transforming them into fixed-sized vectors, termed meta embeddings, thereby enabling the seamless deployment of models with hundreds of billions of parameters for online serving. Through extensive experimentation on production data drawn from various applications at LinkedIn, we demonstrate that the proposed solution consistently outperforms the baseline models of those applications, including strong baselines such as using wide-and-deep ID based personalization approach. Our approach has enabled the deployment of a range of highly personalized AI models across diverse LinkedIn applications, leading to substantial improvements in business metrics as well as refreshed experience for our members.
On Measuring the Diversity of Organizational Networks
May 14, 2021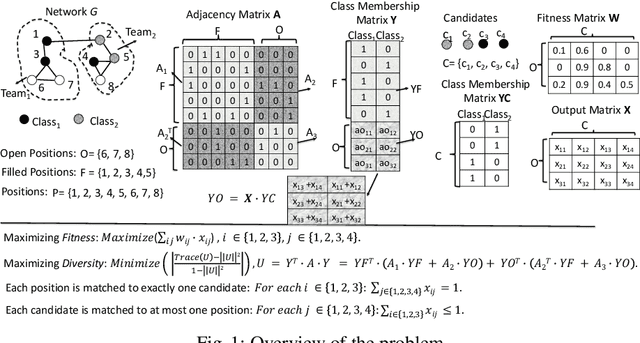
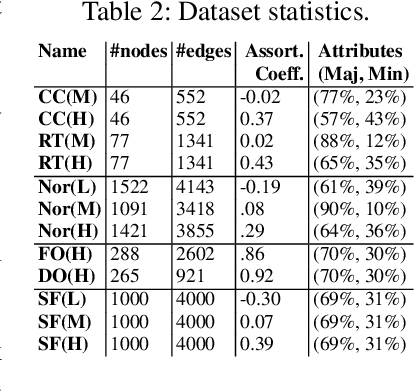

The interaction patterns of employees in social and professional networks play an important role in the success of employees and organizations as a whole. However, in many fields there is a severe under-representation of minority groups; moreover, minority individuals may be segregated from the rest of the network or isolated from one another. While the problem of increasing the representation of minority groups in various fields has been well-studied, diver- sification in terms of numbers alone may not be sufficient: social relationships should also be considered. In this work, we consider the problem of assigning a set of employment candidates to positions in a social network so that diversity and overall fitness are maximized, and propose Fair Employee Assignment (FairEA), a novel algorithm for finding such a matching. The output from FairEA can be used as a benchmark by organizations wishing to evaluate their hiring and assignment practices. On real and synthetic networks, we demonstrate that FairEA does well at finding high-fitness, high-diversity matchings.
An Ultra-Efficient Memristor-Based DNN Framework with Structured Weight Pruning and Quantization Using ADMM
Aug 29, 2019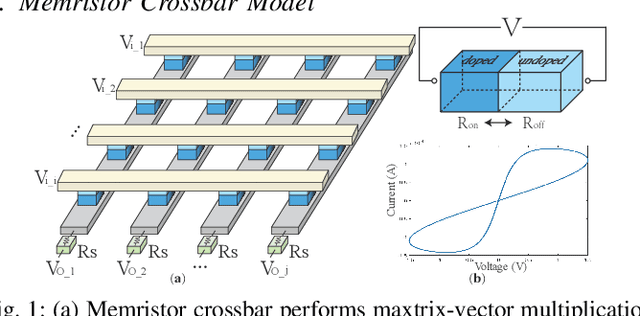
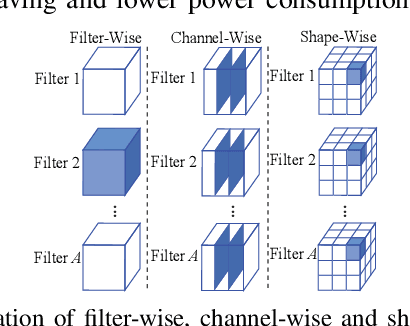
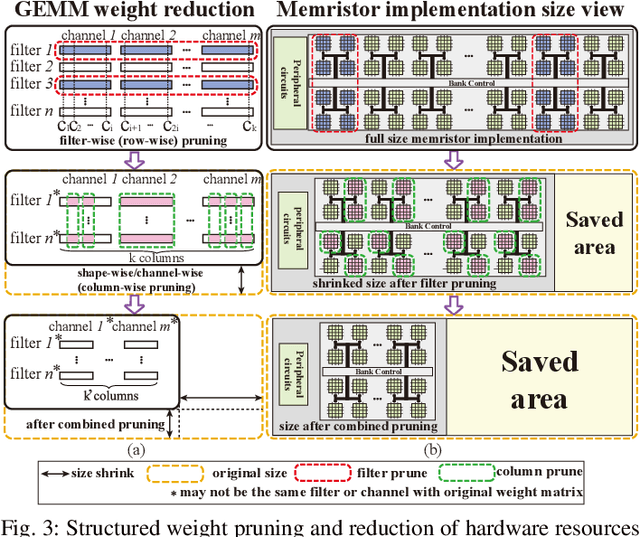
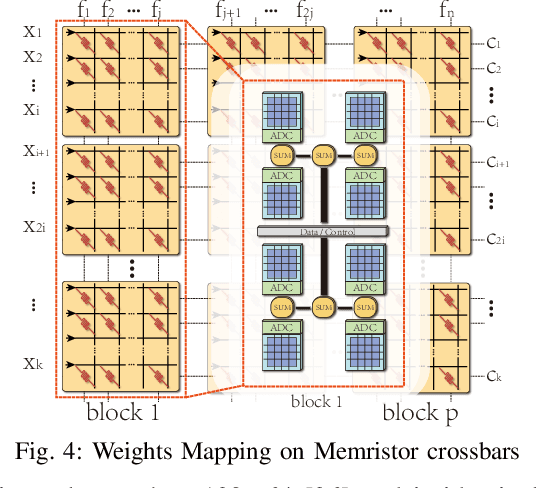
The high computation and memory storage of large deep neural networks (DNNs) models pose intensive challenges to the conventional Von-Neumann architecture, incurring substantial data movements in the memory hierarchy. The memristor crossbar array has emerged as a promising solution to mitigate the challenges and enable low-power acceleration of DNNs. Memristor-based weight pruning and weight quantization have been seperately investigated and proven effectiveness in reducing area and power consumption compared to the original DNN model. However, there has been no systematic investigation of memristor-based neuromorphic computing (NC) systems considering both weight pruning and weight quantization. In this paper, we propose an unified and systematic memristor-based framework considering both structured weight pruning and weight quantization by incorporating alternating direction method of multipliers (ADMM) into DNNs training. We consider hardware constraints such as crossbar blocks pruning, conductance range, and mismatch between weight value and real devices, to achieve high accuracy and low power and small area footprint. Our framework is mainly integrated by three steps, i.e., memristor-based ADMM regularized optimization, masked mapping and retraining. Experimental results show that our proposed framework achieves 29.81X (20.88X) weight compression ratio, with 98.38% (96.96%) and 98.29% (97.47%) power and area reduction on VGG-16 (ResNet-18) network where only have 0.5% (0.76%) accuracy loss, compared to the original DNN models. We share our models at link http://bit.ly/2Jp5LHJ.