 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFPI-Det: a face--phone Interaction Dataset for phone-use detection and understanding
Sep 11, 2025The widespread use of mobile devices has created new challenges for vision systems in safety monitoring, workplace productivity assessment, and attention management. Detecting whether a person is using a phone requires not only object recognition but also an understanding of behavioral context, which involves reasoning about the relationship between faces, hands, and devices under diverse conditions. Existing generic benchmarks do not fully capture such fine-grained human--device interactions. To address this gap, we introduce the FPI-Det, containing 22{,}879 images with synchronized annotations for faces and phones across workplace, education, transportation, and public scenarios. The dataset features extreme scale variation, frequent occlusions, and varied capture conditions. We evaluate representative YOLO and DETR detectors, providing baseline results and an analysis of performance across object sizes, occlusion levels, and environments. Source code and dataset is available at https://github.com/KvCgRv/FPI-Det.
A Complex-valued SAR Foundation Model Based on Physically Inspired Representation Learning
Apr 16, 2025Vision foundation models in remote sensing have been extensively studied due to their superior generalization on various downstream tasks. Synthetic Aperture Radar (SAR) offers all-day, all-weather imaging capabilities, providing significant advantages for Earth observation. However, establishing a foundation model for SAR image interpretation inevitably encounters the challenges of insufficient information utilization and poor interpretability. In this paper, we propose a remote sensing foundation model based on complex-valued SAR data, which simulates the polarimetric decomposition process for pre-training, i.e., characterizing pixel scattering intensity as a weighted combination of scattering bases and scattering coefficients, thereby endowing the foundation model with physical interpretability. Specifically, we construct a series of scattering queries, each representing an independent and meaningful scattering basis, which interact with SAR features in the scattering query decoder and output the corresponding scattering coefficient. To guide the pre-training process, polarimetric decomposition loss and power self-supervision loss are constructed. The former aligns the predicted coefficients with Yamaguchi coefficients, while the latter reconstructs power from the predicted coefficients and compares it to the input image's power. The performance of our foundation model is validated on six typical downstream tasks, achieving state-of-the-art results. Notably, the foundation model can extract stable feature representations and exhibits strong generalization, even in data-scarce conditions.
Joint ML-Bayesian Approach to Adaptive Radar Detection in the presence of Gaussian Interference
Mar 04, 2025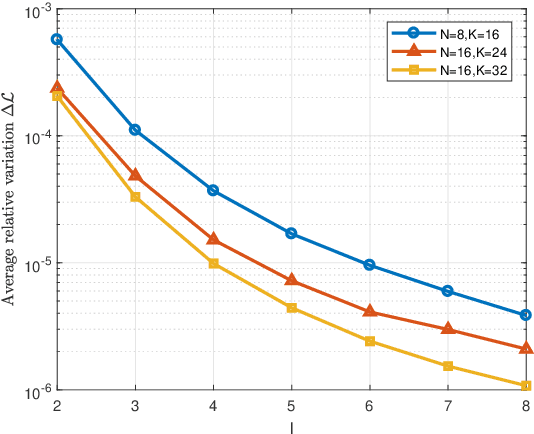
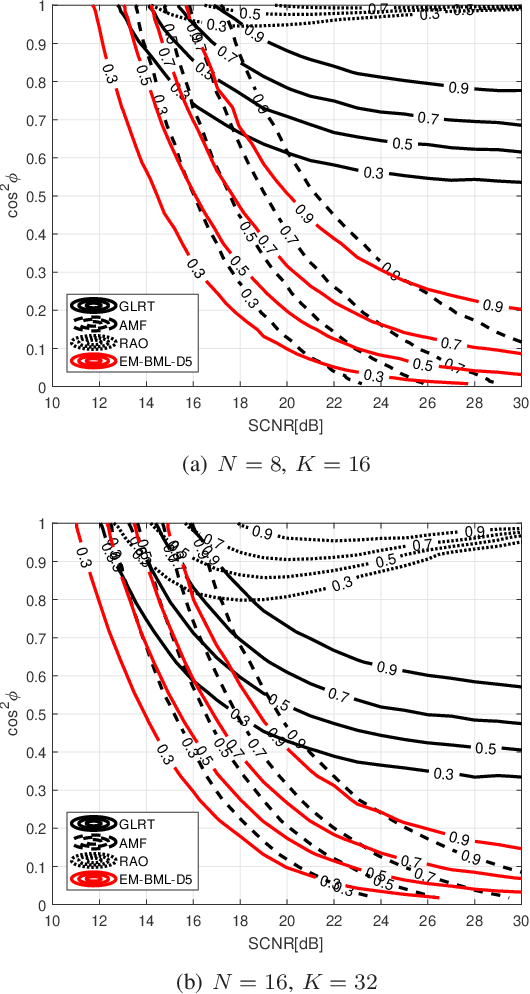
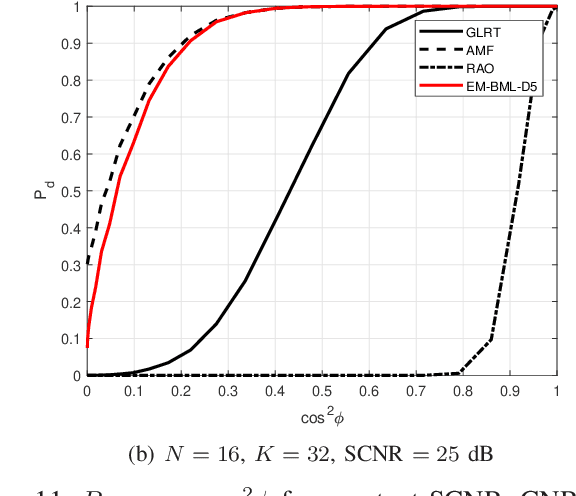
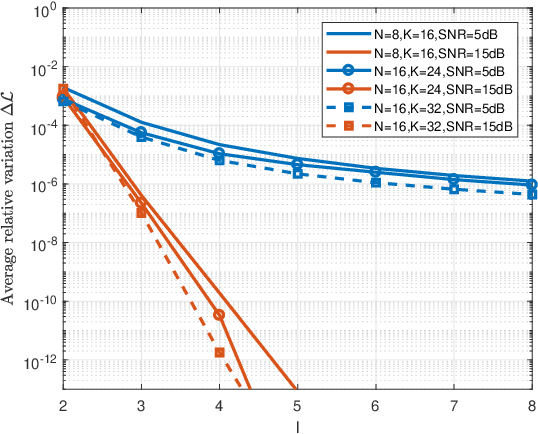
This paper addresses the adaptive radar target detection problem in the presence of Gaussian interference with unknown statistical properties. To this end, the problem is first formulated as a binary hypothesis test, and then we derive a detection architecture grounded on the hybrid of Maximum Likelihood (ML) and Maximum A Posterior (MAP) approach. Specifically, we resort to the hidden discrete latent variables in conjunction with the Expectation-Maximization (EM) algorithms which cyclically updates the estimates of the unknowns. In this framework, the estimates of the a posteriori probabilities under each hypothesis are representative of the inherent nature of data and used to decide for the presence of a potential target. In addition, we prove that the developed detection scheme ensures the desired Constant False Alarm Rate property with respect to the unknown interference covariance matrix. Numerical examples obtained through synthetic and real recorded data corroborate the effectiveness of the proposed architecture and show that the MAP-based approach ensures evident improvement with respect to the conventional generalized likelihood ratio test at least for the considered scenarios and parameter setting.
On the Discrimination and Consistency for Exemplar-Free Class Incremental Learning
Jan 26, 2025



Exemplar-free class incremental learning (EF-CIL) is a nontrivial task that requires continuously enriching model capability with new classes while maintaining previously learned knowledge without storing and replaying any old class exemplars. An emerging theory-guided framework for CIL trains task-specific models for a shared network, shifting the pressure of forgetting to task-id prediction. In EF-CIL, task-id prediction is more challenging due to the lack of inter-task interaction (e.g., replays of exemplars). To address this issue, we conduct a theoretical analysis of the importance and feasibility of preserving a discriminative and consistent feature space, upon which we propose a novel method termed DCNet. Concretely, it progressively maps class representations into a hyperspherical space, in which different classes are orthogonally distributed to achieve ample inter-class separation. Meanwhile, it also introduces compensatory training to adaptively adjust supervision intensity, thereby aligning the degree of intra-class aggregation. Extensive experiments and theoretical analysis verified the superiority of the proposed DCNet.
KAN based Autoencoders for Factor Models
Aug 04, 2024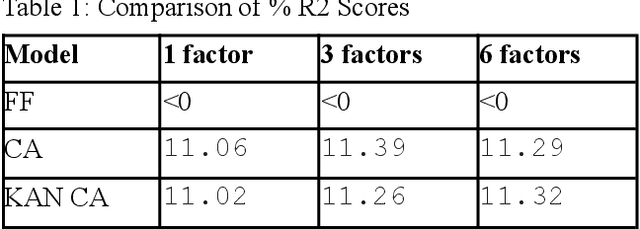
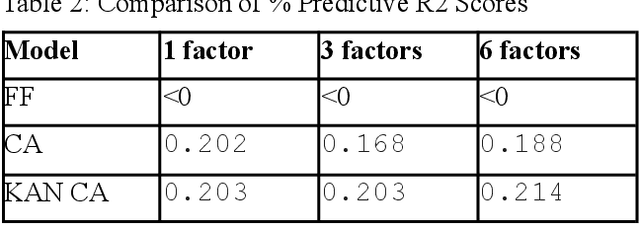
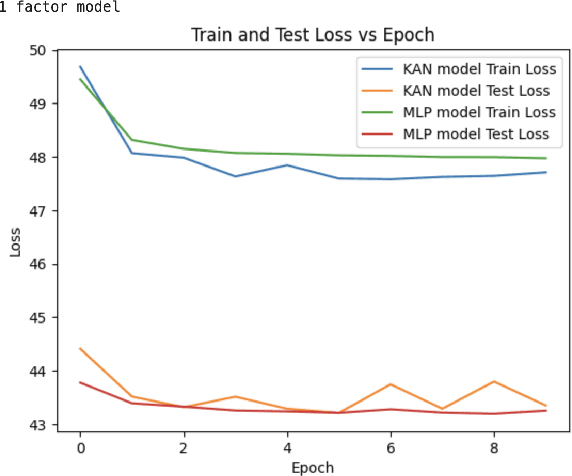
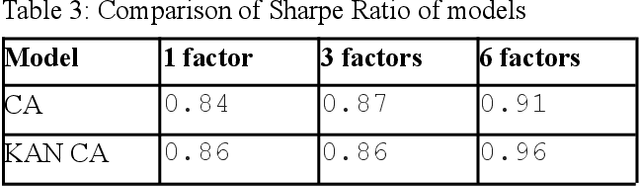
Inspired by recent advances in Kolmogorov-Arnold Networks (KANs), we introduce a novel approach to latent factor conditional asset pricing models. While previous machine learning applications in asset pricing have predominantly used Multilayer Perceptrons with ReLU activation functions to model latent factor exposures, our method introduces a KAN-based autoencoder which surpasses MLP models in both accuracy and interpretability. Our model offers enhanced flexibility in approximating exposures as nonlinear functions of asset characteristics, while simultaneously providing users with an intuitive framework for interpreting latent factors. Empirical backtesting demonstrates our model's superior ability to explain cross-sectional risk exposures. Moreover, long-short portfolios constructed using our model's predictions achieve higher Sharpe ratios, highlighting its practical value in investment management.
Harnessing Neural Unit Dynamics for Effective and Scalable Class-Incremental Learning
Jun 04, 2024Class-incremental learning (CIL) aims to train a model to learn new classes from non-stationary data streams without forgetting old ones. In this paper, we propose a new kind of connectionist model by tailoring neural unit dynamics that adapt the behavior of neural networks for CIL. In each training session, it introduces a supervisory mechanism to guide network expansion whose growth size is compactly commensurate with the intrinsic complexity of a newly arriving task. This constructs a near-minimal network while allowing the model to expand its capacity when cannot sufficiently hold new classes. At inference time, it automatically reactivates the required neural units to retrieve knowledge and leaves the remaining inactivated to prevent interference. We name our model AutoActivator, which is effective and scalable. To gain insights into the neural unit dynamics, we theoretically analyze the model's convergence property via a universal approximation theorem on learning sequential mappings, which is under-explored in the CIL community. Experiments show that our method achieves strong CIL performance in rehearsal-free and minimal-expansion settings with different backbones.
DriveCoT: Integrating Chain-of-Thought Reasoning with End-to-End Driving
Mar 25, 2024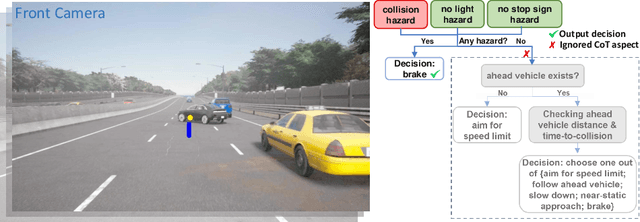
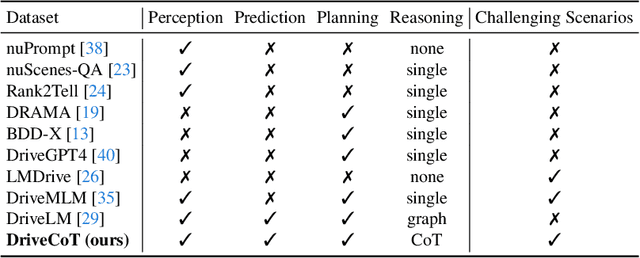

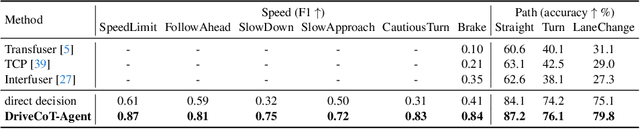
End-to-end driving has made significant progress in recent years, demonstrating benefits such as system simplicity and competitive driving performance under both open-loop and closed-loop settings. Nevertheless, the lack of interpretability and controllability in its driving decisions hinders real-world deployment for end-to-end driving systems. In this paper, we collect a comprehensive end-to-end driving dataset named DriveCoT, leveraging the CARLA simulator. It contains sensor data, control decisions, and chain-of-thought labels to indicate the reasoning process. We utilize the challenging driving scenarios from the CARLA leaderboard 2.0, which involve high-speed driving and lane-changing, and propose a rule-based expert policy to control the vehicle and generate ground truth labels for its reasoning process across different driving aspects and the final decisions. This dataset can serve as an open-loop end-to-end driving benchmark, enabling the evaluation of accuracy in various chain-of-thought aspects and the final decision. In addition, we propose a baseline model called DriveCoT-Agent, trained on our dataset, to generate chain-of-thought predictions and final decisions. The trained model exhibits strong performance in both open-loop and closed-loop evaluations, demonstrating the effectiveness of our proposed dataset.
LiMAML: Personalization of Deep Recommender Models via Meta Learning
Feb 23, 2024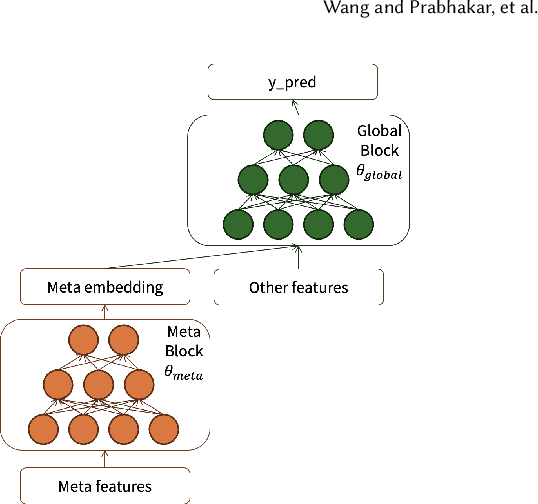

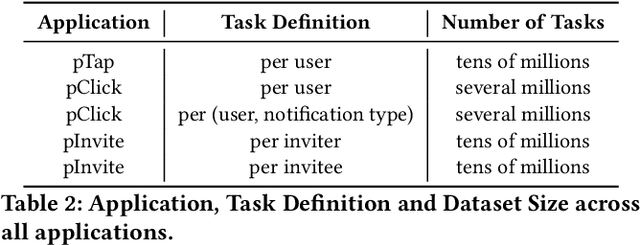

In the realm of recommender systems, the ubiquitous adoption of deep neural networks has emerged as a dominant paradigm for modeling diverse business objectives. As user bases continue to expand, the necessity of personalization and frequent model updates have assumed paramount significance to ensure the delivery of relevant and refreshed experiences to a diverse array of members. In this work, we introduce an innovative meta-learning solution tailored to the personalization of models for individual members and other entities, coupled with the frequent updates based on the latest user interaction signals. Specifically, we leverage the Model-Agnostic Meta Learning (MAML) algorithm to adapt per-task sub-networks using recent user interaction data. Given the near infeasibility of productionizing original MAML-based models in online recommendation systems, we propose an efficient strategy to operationalize meta-learned sub-networks in production, which involves transforming them into fixed-sized vectors, termed meta embeddings, thereby enabling the seamless deployment of models with hundreds of billions of parameters for online serving. Through extensive experimentation on production data drawn from various applications at LinkedIn, we demonstrate that the proposed solution consistently outperforms the baseline models of those applications, including strong baselines such as using wide-and-deep ID based personalization approach. Our approach has enabled the deployment of a range of highly personalized AI models across diverse LinkedIn applications, leading to substantial improvements in business metrics as well as refreshed experience for our members.
Towards Continual Learning Desiderata via HSIC-Bottleneck Orthogonalization and Equiangular Embedding
Jan 17, 2024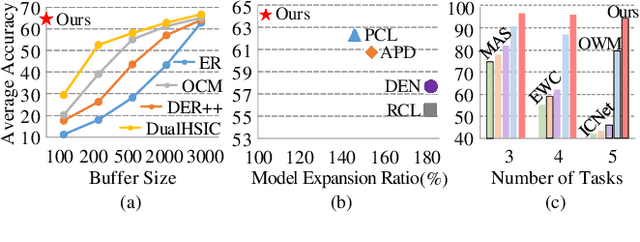
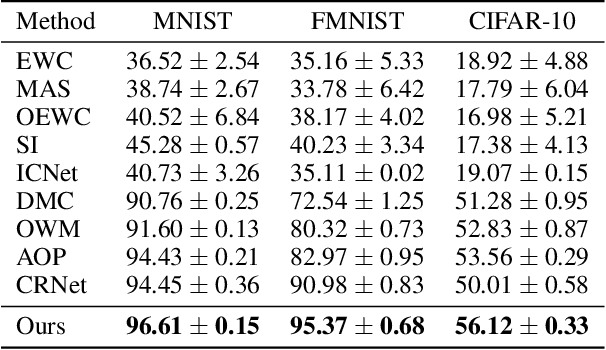
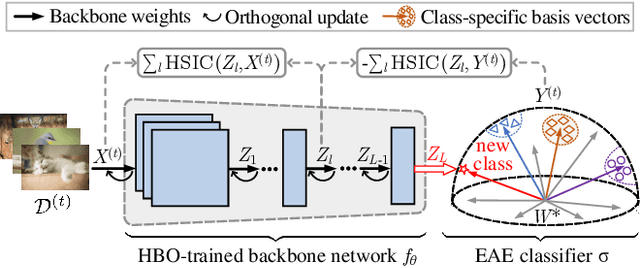

Deep neural networks are susceptible to catastrophic forgetting when trained on sequential tasks. Various continual learning (CL) methods often rely on exemplar buffers or/and network expansion for balancing model stability and plasticity, which, however, compromises their practical value due to privacy and memory concerns. Instead, this paper considers a strict yet realistic setting, where the training data from previous tasks is unavailable and the model size remains relatively constant during sequential training. To achieve such desiderata, we propose a conceptually simple yet effective method that attributes forgetting to layer-wise parameter overwriting and the resulting decision boundary distortion. This is achieved by the synergy between two key components: HSIC-Bottleneck Orthogonalization (HBO) implements non-overwritten parameter updates mediated by Hilbert-Schmidt independence criterion in an orthogonal space and EquiAngular Embedding (EAE) enhances decision boundary adaptation between old and new tasks with predefined basis vectors. Extensive experiments demonstrate that our method achieves competitive accuracy performance, even with absolute superiority of zero exemplar buffer and 1.02x the base model.
AccidentGPT: Accident Analysis and Prevention from V2X Environmental Perception with Multi-modal Large Model
Dec 29, 2023



Traffic accidents, being a significant contributor to both human casualties and property damage, have long been a focal point of research for many scholars in the field of traffic safety. However, previous studies, whether focusing on static environmental assessments or dynamic driving analyses, as well as pre-accident predictions or post-accident rule analyses, have typically been conducted in isolation. There has been a lack of an effective framework for developing a comprehensive understanding and application of traffic safety. To address this gap, this paper introduces AccidentGPT, a comprehensive accident analysis and prevention multi-modal large model. AccidentGPT establishes a multi-modal information interaction framework grounded in multi-sensor perception, thereby enabling a holistic approach to accident analysis and prevention in the field of traffic safety. Specifically, our capabilities can be categorized as follows: for autonomous driving vehicles, we provide comprehensive environmental perception and understanding to control the vehicle and avoid collisions. For human-driven vehicles, we offer proactive long-range safety warnings and blind-spot alerts while also providing safety driving recommendations and behavioral norms through human-machine dialogue and interaction. Additionally, for traffic police and management agencies, our framework supports intelligent and real-time analysis of traffic safety, encompassing pedestrian, vehicles, roads, and the environment through collaborative perception from multiple vehicles and road testing devices. The system is also capable of providing a thorough analysis of accident causes and liability after vehicle collisions. Our framework stands as the first large model to integrate comprehensive scene understanding into traffic safety studies. Project page: https://accidentgpt.github.io