 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffGen: Enabling Small Language Models as Capable Autonomous Agents
Jan 31, 2026Most existing language model agentic systems today are built and optimized for large language models (e.g., GPT, Claude, Gemini) via API calls. While powerful, this approach faces several limitations including high token costs and privacy concerns for sensitive applications. We introduce effGen, an open-source agentic framework optimized for small language models (SLMs) that enables effective, efficient, and secure local deployment (pip install effgen). effGen makes four major contributions: (1) Enhanced tool-calling with prompt optimization that compresses contexts by 70-80% while preserving task semantics, (2) Intelligent task decomposition that breaks complex queries into parallel or sequential subtasks based on dependencies, (3) Complexity-based routing using five factors to make smart pre-execution decisions, and (4) Unified memory system combining short-term, long-term, and vector-based storage. Additionally, effGen unifies multiple agent protocols (MCP, A2A, ACP) for cross-protocol communication. Results on 13 benchmarks show effGen outperforms LangChain, AutoGen, and Smolagents with higher success rates, faster execution, and lower memory. Our results reveal that prompt optimization and complexity routing have complementary scaling behavior: optimization benefits SLMs more (11.2% gain at 1.5B vs 2.4% at 32B), while routing benefits large models more (3.6% at 1.5B vs 7.9% at 32B), providing consistent gains across all scales when combined. effGen (https://effgen.org/) is released under the MIT License, ensuring broad accessibility for research and commercial use. Our framework code is publicly available at https://github.com/ctrl-gaurav/effGen.
SoundBreak: A Systematic Study of Audio-Only Adversarial Attacks on Trimodal Models
Jan 20, 2026Multimodal foundation models that integrate audio, vision, and language achieve strong performance on reasoning and generation tasks, yet their robustness to adversarial manipulation remains poorly understood. We study a realistic and underexplored threat model: untargeted, audio-only adversarial attacks on trimodal audio-video-language models. We analyze six complementary attack objectives that target different stages of multimodal processing, including audio encoder representations, cross-modal attention, hidden states, and output likelihoods. Across three state-of-the-art models and multiple benchmarks, we show that audio-only perturbations can induce severe multimodal failures, achieving up to 96% attack success rate. We further show that attacks can be successful at low perceptual distortions (LPIPS <= 0.08, SI-SNR >= 0) and benefit more from extended optimization than increased data scale. Transferability across models and encoders remains limited, while speech recognition systems such as Whisper primarily respond to perturbation magnitude, achieving >97% attack success under severe distortion. These results expose a previously overlooked single-modality attack surface in multimodal systems and motivate defenses that enforce cross-modal consistency.
Hindsight is 20/20: Building Agent Memory that Retains, Recalls, and Reflects
Dec 14, 2025Agent memory has been touted as a dimension of growth for LLM-based applications, enabling agents that can accumulate experience, adapt across sessions, and move beyond single-shot question answering. The current generation of agent memory systems treats memory as an external layer that extracts salient snippets from conversations, stores them in vector or graph-based stores, and retrieves top-k items into the prompt of an otherwise stateless model. While these systems improve personalization and context carry-over, they still blur the line between evidence and inference, struggle to organize information over long horizons, and offer limited support for agents that must explain their reasoning. We present Hindsight, a memory architecture that treats agent memory as a structured, first-class substrate for reasoning by organizing it into four logical networks that distinguish world facts, agent experiences, synthesized entity summaries, and evolving beliefs. This framework supports three core operations -- retain, recall, and reflect -- that govern how information is added, accessed, and updated. Under this abstraction, a temporal, entity aware memory layer incrementally turns conversational streams into a structured, queryable memory bank, while a reflection layer reasons over this bank to produce answers and to update information in a traceable way. On key long-horizon conversational memory benchmarks like LongMemEval and LoCoMo, Hindsight with an open-source 20B model lifts overall accuracy from 39% to 83.6% over a full-context baseline with the same backbone and outperforms full context GPT-4o. Scaling the backbone further pushes Hindsight to 91.4% on LongMemEval and up to 89.61% on LoCoMo (vs. 75.78% for the strongest prior open system), consistently outperforming existing memory architectures on multi-session and open-domain questions.
DEBATE, TRAIN, EVOLVE: Self Evolution of Language Model Reasoning
May 21, 2025Large language models (LLMs) have improved significantly in their reasoning through extensive training on massive datasets. However, relying solely on additional data for improvement is becoming increasingly impractical, highlighting the need for models to autonomously enhance their reasoning without external supervision. In this paper, we propose Debate, Train, Evolve (DTE), a novel ground truth-free training framework that uses multi-agent debate traces to evolve a single language model. We also introduce a new prompting strategy Reflect-Critique-Refine, to improve debate quality by explicitly instructing agents to critique and refine their reasoning. Extensive evaluations on five reasoning benchmarks with six open-weight models show that our DTE framework achieve substantial improvements, with an average accuracy gain of 8.92% on the challenging GSM-PLUS dataset. Furthermore, we observe strong cross-domain generalization, with an average accuracy gain of 5.8% on all other benchmarks, suggesting that our method captures general reasoning capabilities.
Towards Reasoning Ability of Small Language Models
Feb 17, 2025Reasoning has long been viewed as an emergent property of large language models (LLMs), appearing at or above a certain scale ($\sim$100B parameters). However, recent studies challenge this assumption, showing that small language models (SLMs) can also achieve competitive reasoning performance. SLMs are increasingly favored for their efficiency and deployability. However, there is a lack of systematic study on the reasoning abilities of diverse SLMs, including those trained from scratch or derived from LLMs through quantization, pruning, and distillation. This raises a critical question: Can SLMs achieve reasoning abilities comparable to LLMs? In this work, we systematically survey, benchmark, and analyze 72 SLMs from six model families across 14 reasoning benchmarks. For reliable evaluation, we examine four evaluation methods and compare four LLM judges against human evaluations on 800 data points. We repeat all experiments three times to ensure a robust performance assessment. Additionally, we analyze the impact of different prompting strategies in small models. Beyond accuracy, we also evaluate model robustness under adversarial conditions and intermediate reasoning steps. Our findings challenge the assumption that scaling is the only way to achieve strong reasoning. Instead, we foresee a future where SLMs with strong reasoning capabilities can be developed through structured training or post-training compression. They can serve as efficient alternatives to LLMs for reasoning-intensive tasks.
From Features to Transformers: Redefining Ranking for Scalable Impact
Feb 05, 2025We present LiGR, a large-scale ranking framework developed at LinkedIn that brings state-of-the-art transformer-based modeling architectures into production. We introduce a modified transformer architecture that incorporates learned normalization and simultaneous set-wise attention to user history and ranked items. This architecture enables several breakthrough achievements, including: (1) the deprecation of most manually designed feature engineering, outperforming the prior state-of-the-art system using only few features (compared to hundreds in the baseline), (2) validation of the scaling law for ranking systems, showing improved performance with larger models, more training data, and longer context sequences, and (3) simultaneous joint scoring of items in a set-wise manner, leading to automated improvements in diversity. To enable efficient serving of large ranking models, we describe techniques to scale inference effectively using single-pass processing of user history and set-wise attention. We also summarize key insights from various ablation studies and A/B tests, highlighting the most impactful technical approaches.
LiMAML: Personalization of Deep Recommender Models via Meta Learning
Feb 23, 2024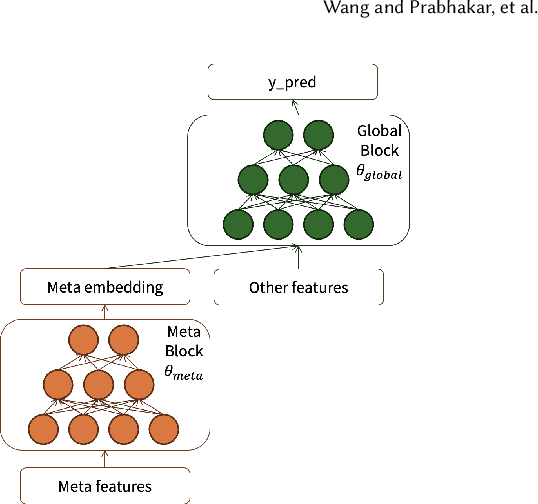


In the realm of recommender systems, the ubiquitous adoption of deep neural networks has emerged as a dominant paradigm for modeling diverse business objectives. As user bases continue to expand, the necessity of personalization and frequent model updates have assumed paramount significance to ensure the delivery of relevant and refreshed experiences to a diverse array of members. In this work, we introduce an innovative meta-learning solution tailored to the personalization of models for individual members and other entities, coupled with the frequent updates based on the latest user interaction signals. Specifically, we leverage the Model-Agnostic Meta Learning (MAML) algorithm to adapt per-task sub-networks using recent user interaction data. Given the near infeasibility of productionizing original MAML-based models in online recommendation systems, we propose an efficient strategy to operationalize meta-learned sub-networks in production, which involves transforming them into fixed-sized vectors, termed meta embeddings, thereby enabling the seamless deployment of models with hundreds of billions of parameters for online serving. Through extensive experimentation on production data drawn from various applications at LinkedIn, we demonstrate that the proposed solution consistently outperforms the baseline models of those applications, including strong baselines such as using wide-and-deep ID based personalization approach. Our approach has enabled the deployment of a range of highly personalized AI models across diverse LinkedIn applications, leading to substantial improvements in business metrics as well as refreshed experience for our members.
Multi-view Sparse Laplacian Eigenmaps for nonlinear Spectral Feature Selection
Jul 29, 2023

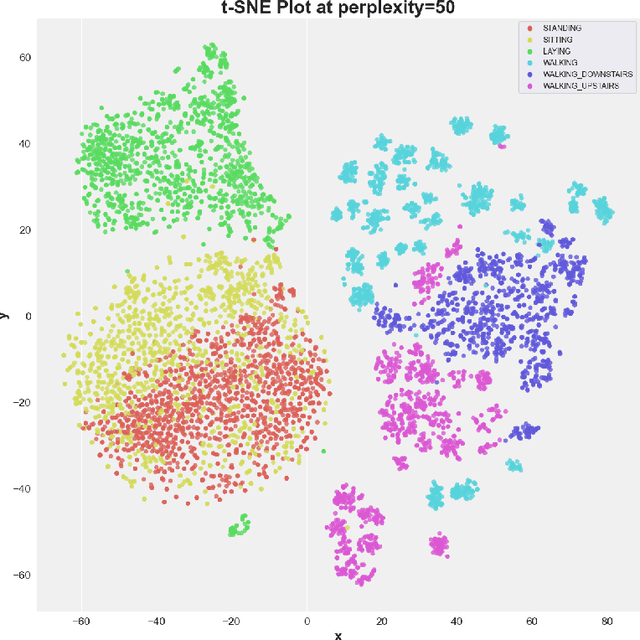

The complexity of high-dimensional datasets presents significant challenges for machine learning models, including overfitting, computational complexity, and difficulties in interpreting results. To address these challenges, it is essential to identify an informative subset of features that captures the essential structure of the data. In this study, the authors propose Multi-view Sparse Laplacian Eigenmaps (MSLE) for feature selection, which effectively combines multiple views of the data, enforces sparsity constraints, and employs a scalable optimization algorithm to identify a subset of features that capture the fundamental data structure. MSLE is a graph-based approach that leverages multiple views of the data to construct a more robust and informative representation of high-dimensional data. The method applies sparse eigendecomposition to reduce the dimensionality of the data, yielding a reduced feature set. The optimization problem is solved using an iterative algorithm alternating between updating the sparse coefficients and the Laplacian graph matrix. The sparse coefficients are updated using a soft-thresholding operator, while the graph Laplacian matrix is updated using the normalized graph Laplacian. To evaluate the performance of the MSLE technique, the authors conducted experiments on the UCI-HAR dataset, which comprises 561 features, and reduced the feature space by 10 to 90%. Our results demonstrate that even after reducing the feature space by 90%, the Support Vector Machine (SVM) maintains an error rate of 2.72%. Moreover, the authors observe that the SVM exhibits an accuracy of 96.69% with an 80% reduction in the overall feature space.
Private and Efficient Meta-Learning with Low Rank and Sparse Decomposition
Oct 07, 2022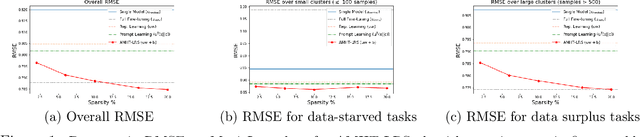
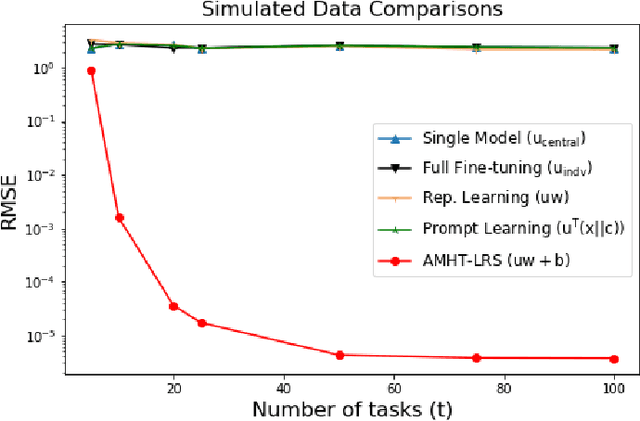
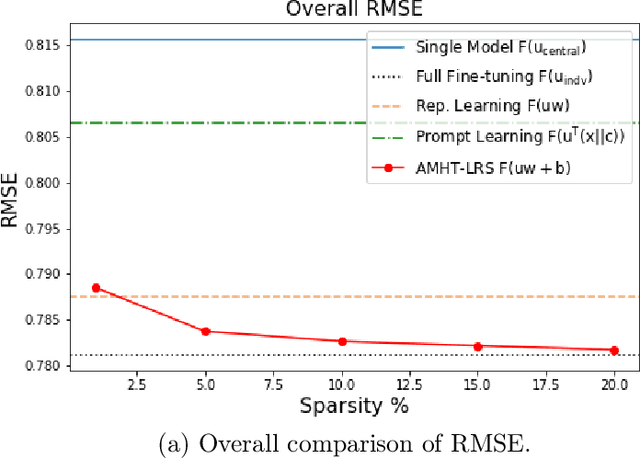
Meta-learning is critical for a variety of practical ML systems -- like personalized recommendations systems -- that are required to generalize to new tasks despite a small number of task-specific training points. Existing meta-learning techniques use two complementary approaches of either learning a low-dimensional representation of points for all tasks, or task-specific fine-tuning of a global model trained using all the tasks. In this work, we propose a novel meta-learning framework that combines both the techniques to enable handling of a large number of data-starved tasks. Our framework models network weights as a sum of low-rank and sparse matrices. This allows us to capture information from multiple domains together in the low-rank part while still allowing task specific personalization using the sparse part. We instantiate and study the framework in the linear setting, where the problem reduces to that of estimating the sum of a rank-$r$ and a $k$-column sparse matrix using a small number of linear measurements. We propose an alternating minimization method with hard thresholding -- AMHT-LRS -- to learn the low-rank and sparse part effectively and efficiently. For the realizable, Gaussian data setting, we show that AMHT-LRS indeed solves the problem efficiently with nearly optimal samples. We extend AMHT-LRS to ensure that it preserves privacy of each individual user in the dataset, while still ensuring strong generalization with nearly optimal number of samples. Finally, on multiple datasets, we demonstrate that the framework allows personalized models to obtain superior performance in the data-scarce regime.
Training and challenging models for text-guided fashion image retrieval
Apr 23, 2022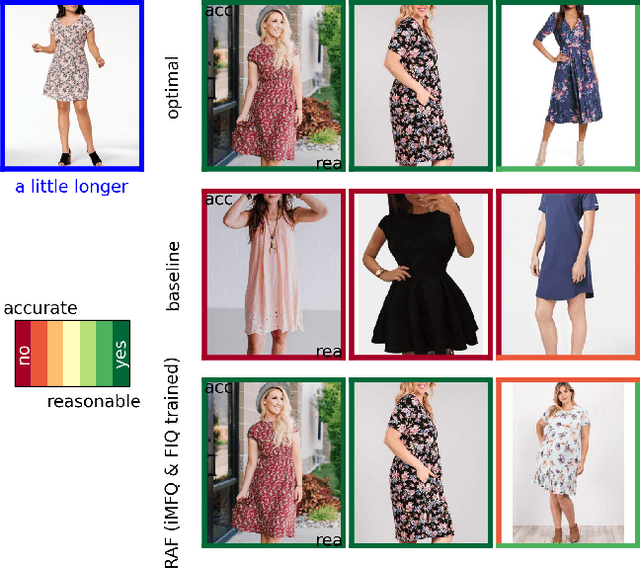
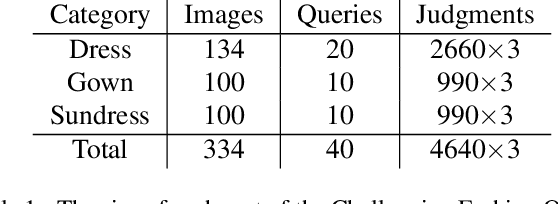
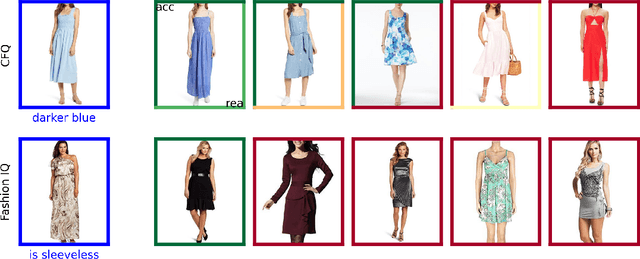

Retrieving relevant images from a catalog based on a query image together with a modifying caption is a challenging multimodal task that can particularly benefit domains like apparel shopping, where fine details and subtle variations may be best expressed through natural language. We introduce a new evaluation dataset, Challenging Fashion Queries (CFQ), as well as a modeling approach that achieves state-of-the-art performance on the existing Fashion IQ (FIQ) dataset. CFQ complements existing benchmarks by including relative captions with positive and negative labels of caption accuracy and conditional image similarity, where others provided only positive labels with a combined meaning. We demonstrate the importance of multimodal pretraining for the task and show that domain-specific weak supervision based on attribute labels can augment generic large-scale pretraining. While previous modality fusion mechanisms lose the benefits of multimodal pretraining, we introduce a residual attention fusion mechanism that improves performance. We release CFQ and our code to the research community.