 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimizing Area and Energy of Deep Learning Hardware Design Using Collective Low Precision and Structured Compression
Paper and Code
Apr 19, 2018

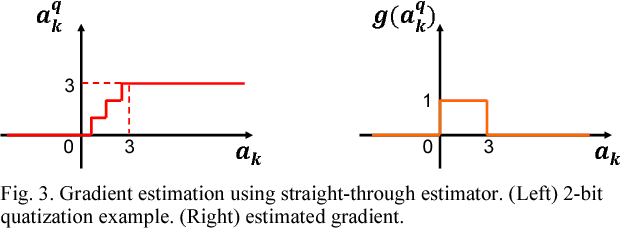
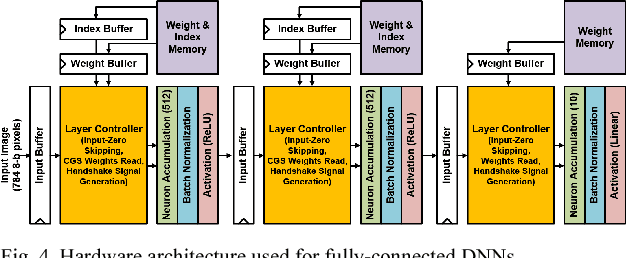
Deep learning algorithms have shown tremendous success in many recognition tasks; however, these algorithms typically include a deep neural network (DNN) structure and a large number of parameters, which makes it challenging to implement them on power/area-constrained embedded platforms. To reduce the network size, several studies investigated compression by introducing element-wise or row-/column-/block-wise sparsity via pruning and regularization. In addition, many recent works have focused on reducing precision of activations and weights with some reducing down to a single bit. However, combining various sparsity structures with binarized or very-low-precision (2-3 bit) neural networks have not been comprehensively explored. In this work, we present design techniques for minimum-area/-energy DNN hardware with minimal degradation in accuracy. During training, both binarization/low-precision and structured sparsity are applied as constraints to find the smallest memory footprint for a given deep learning algorithm. The DNN model for CIFAR-10 dataset with weight memory reduction of 50X exhibits accuracy comparable to that of the floating-point counterpart. Area, performance and energy results of DNN hardware in 40nm CMOS are reported for the MNIST dataset. The optimized DNN that combines 8X structured compression and 3-bit weight precision showed 98.4% accuracy at 20nJ per classification.