 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Extraction Attacks on Split Federated Learning
Mar 13, 2023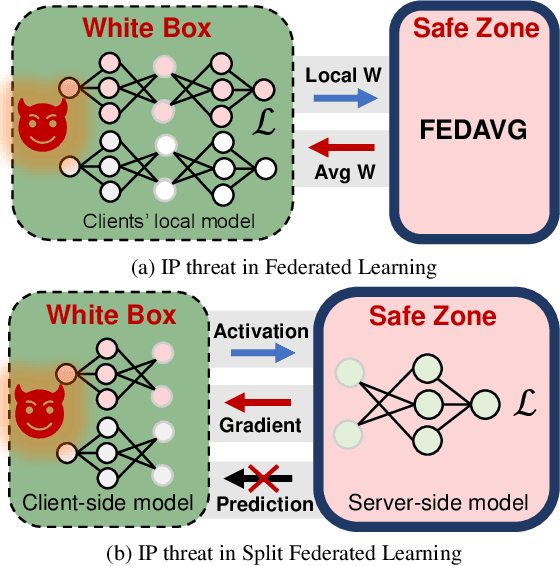

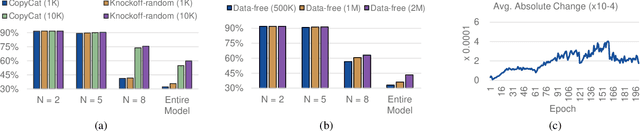

Federated Learning (FL) is a popular collaborative learning scheme involving multiple clients and a server. FL focuses on protecting clients' data but turns out to be highly vulnerable to Intellectual Property (IP) threats. Since FL periodically collects and distributes the model parameters, a free-rider can download the latest model and thus steal model IP. Split Federated Learning (SFL), a recent variant of FL that supports training with resource-constrained clients, splits the model into two, giving one part of the model to clients (client-side model), and the remaining part to the server (server-side model). Thus SFL prevents model leakage by design. Moreover, by blocking prediction queries, it can be made resistant to advanced IP threats such as traditional Model Extraction (ME) attacks. While SFL is better than FL in terms of providing IP protection, it is still vulnerable. In this paper, we expose the vulnerability of SFL and show how malicious clients can launch ME attacks by querying the gradient information from the server side. We propose five variants of ME attack which differs in the gradient usage as well as in the data assumptions. We show that under practical cases, the proposed ME attacks work exceptionally well for SFL. For instance, when the server-side model has five layers, our proposed ME attack can achieve over 90% accuracy with less than 2% accuracy degradation with VGG-11 on CIFAR-10.
Proactively Predicting Dynamic 6G Link Blockages Using LiDAR and In-Band Signatures
Nov 17, 2022



Line-of-sight link blockages represent a key challenge for the reliability and latency of millimeter wave (mmWave) and terahertz (THz) communication networks. To address this challenge, this paper leverages mmWave and LiDAR sensory data to provide awareness about the communication environment and proactively predict dynamic link blockages before they occur. This allows the network to make proactive decisions for hand-off/beam switching, enhancing the network reliability and latency. More specifically, this paper addresses the following key questions: (i) Can we predict a line-of-sight link blockage, before it happens, using in-band mmWave/THz signal and LiDAR sensing data? (ii) Can we also predict when this blockage will occur? (iii) Can we predict the blockage duration? And (iv) can we predict the direction of the moving blockage? For that, we develop machine learning solutions that learn special patterns of the received signal and sensory data, which we call \textit{pre-blockage signatures}, to infer future blockages. To evaluate the proposed approaches, we build a large-scale real-world dataset that comprises co-existing LiDAR and mmWave communication measurements in outdoor vehicular scenarios. Then, we develop an efficient LiDAR data denoising algorithm that applies some pre-processing to the LiDAR data. Based on the real-world dataset, the developed approaches are shown to achieve above 95\% accuracy in predicting blockages occurring within 100 ms and more than 80\% prediction accuracy for blockages occurring within one second. Given this future blockage prediction capability, the paper also shows that the developed solutions can achieve an order of magnitude saving in network latency, which further highlights the potential of the developed blockage prediction solutions for wireless networks.
An Adjustable Farthest Point Sampling Method for Approximately-sorted Point Cloud Data
Aug 18, 2022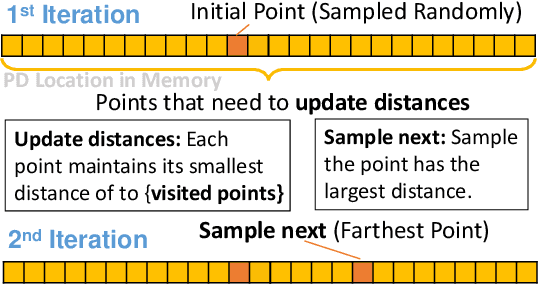
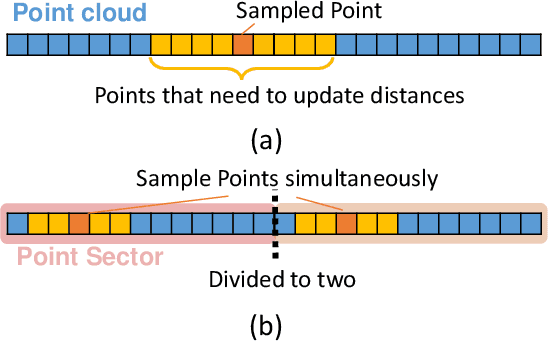
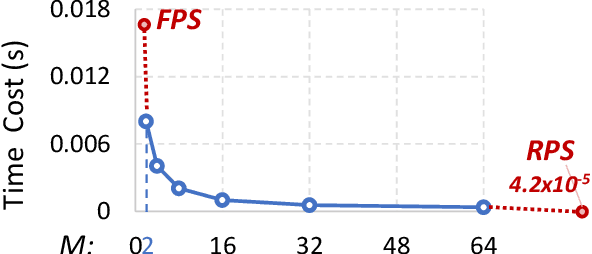
Sampling is an essential part of raw point cloud data processing such as in the popular PointNet++ scheme. Farthest Point Sampling (FPS), which iteratively samples the farthest point and performs distance updating, is one of the most popular sampling schemes. Unfortunately it suffers from low efficiency and can become the bottleneck of point cloud applications. We propose adjustable FPS (AFPS), parameterized by M, to aggressively reduce the complexity of FPS without compromising on the sampling performance. Specifically, it divides the original point cloud into M small point clouds and samples M points simultaneously. It exploits the dimensional locality of an approximately sorted point cloud data to minimize its performance degradation. AFPS method can achieve 22 to 30x speedup over original FPS. Furthermore, we propose the nearest-point-distance-updating (NPDU) method to limit the number of distance updates to a constant number. The combined NPDU on AFPS method can achieve a 34-280x speedup on a point cloud with 2K-32K points with algorithmic performance that is comparable to the original FPS. For instance, for the ShapeNet part segmentation task, it achieves 0.8490 instance average mIoU (mean Intersection of Union), which is only 0.0035 drop compared to the original FPS.
ResSFL: A Resistance Transfer Framework for Defending Model Inversion Attack in Split Federated Learning
May 09, 2022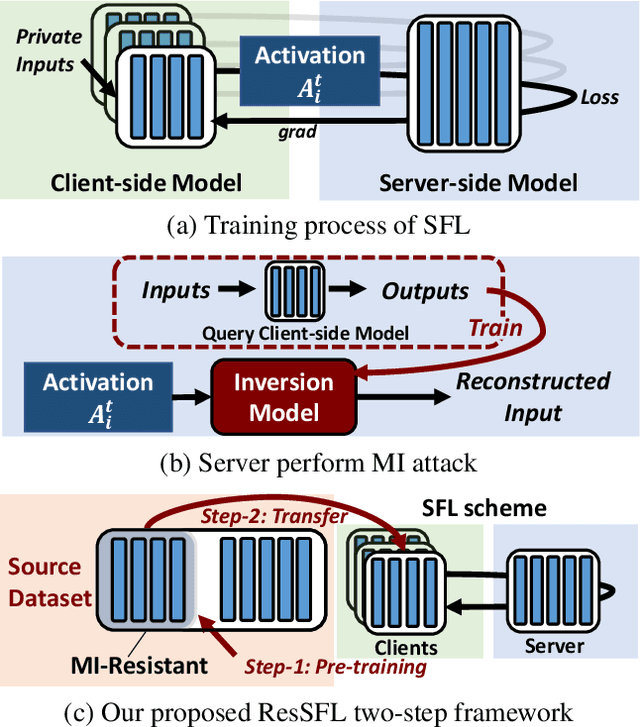
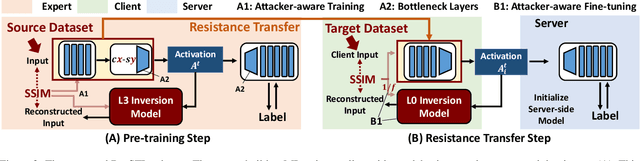
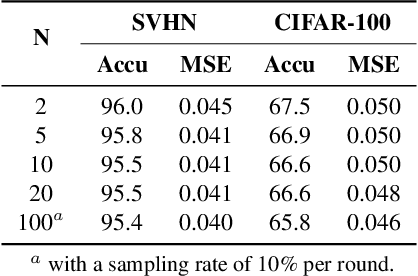
This work aims to tackle Model Inversion (MI) attack on Split Federated Learning (SFL). SFL is a recent distributed training scheme where multiple clients send intermediate activations (i.e., feature map), instead of raw data, to a central server. While such a scheme helps reduce the computational load at the client end, it opens itself to reconstruction of raw data from intermediate activation by the server. Existing works on protecting SFL only consider inference and do not handle attacks during training. So we propose ResSFL, a Split Federated Learning Framework that is designed to be MI-resistant during training. It is based on deriving a resistant feature extractor via attacker-aware training, and using this extractor to initialize the client-side model prior to standard SFL training. Such a method helps in reducing the computational complexity due to use of strong inversion model in client-side adversarial training as well as vulnerability of attacks launched in early training epochs. On CIFAR-100 dataset, our proposed framework successfully mitigates MI attack on a VGG-11 model with a high reconstruction Mean-Square-Error of 0.050 compared to 0.005 obtained by the baseline system. The framework achieves 67.5% accuracy (only 1% accuracy drop) with very low computation overhead. Code is released at: https://github.com/zlijingtao/ResSFL.
LiDAR-Aided Mobile Blockage Prediction in Real-World Millimeter Wave Systems
Nov 18, 2021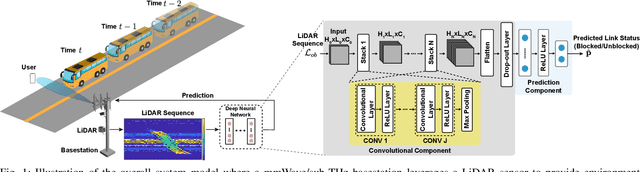
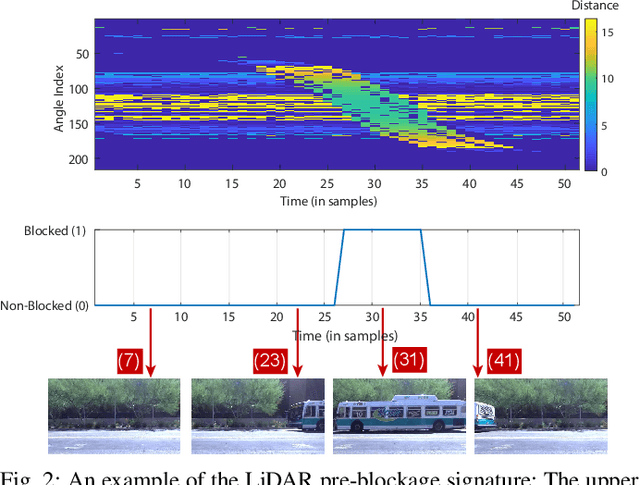
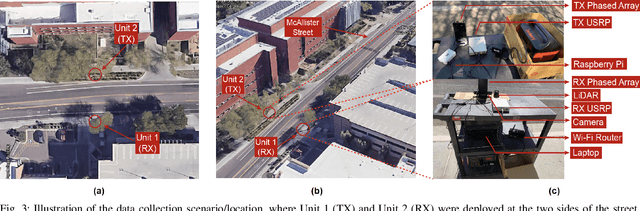
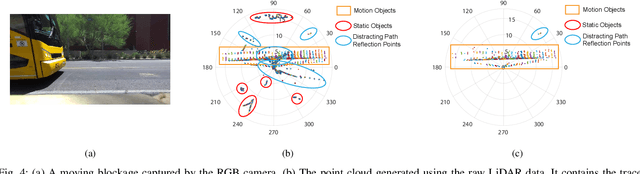
Line-of-sight link blockages represent a key challenge for the reliability and latency of millimeter wave (mmWave) and terahertz (THz) communication networks. This paper proposes to leverage LiDAR sensory data to provide awareness about the communication environment and proactively predict dynamic link blockages before they happen. This allows the network to make proactive decisions for hand-off/beam switching which enhances its reliability and latency. We formulate the LiDAR-aided blockage prediction problem and present the first real-world demonstration for LiDAR-aided blockage prediction in mmWave systems. In particular, we construct a large-scale real-world dataset, based on the DeepSense 6G structure, that comprises co-existing LiDAR and mmWave communication measurements in outdoor vehicular scenarios. Then, we develop an efficient LiDAR data denoising (static cluster removal) algorithm and a machine learning model that proactively predicts dynamic link blockages. Based on the real-world dataset, our LiDAR-aided approach is shown to achieve 95\% accuracy in predicting blockages happening within 100ms and more than 80\% prediction accuracy for blockages happening within one second. If used for proactive hand-off, the proposed solutions can potentially provide an order of magnitude saving in the network latency, which highlights a promising direction for addressing the blockage challenges in mmWave/sub-THz networks.
Blockage Prediction Using Wireless Signatures: Deep Learning Enables Real-World Demonstration
Nov 16, 2021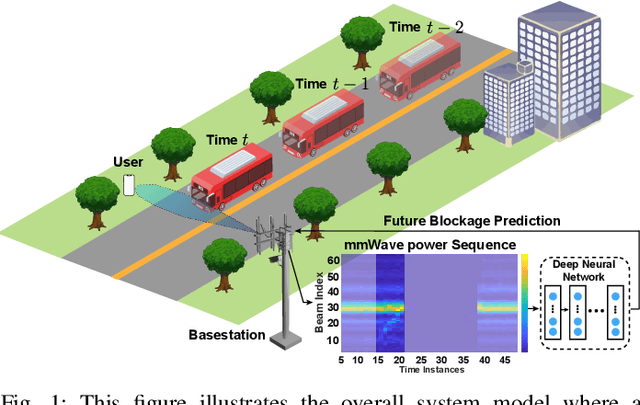
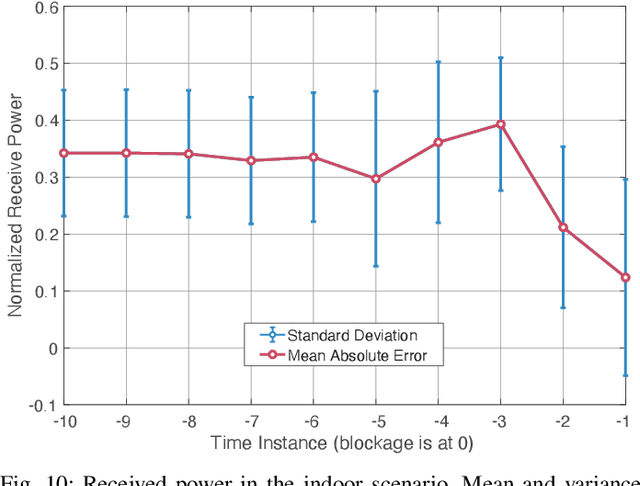
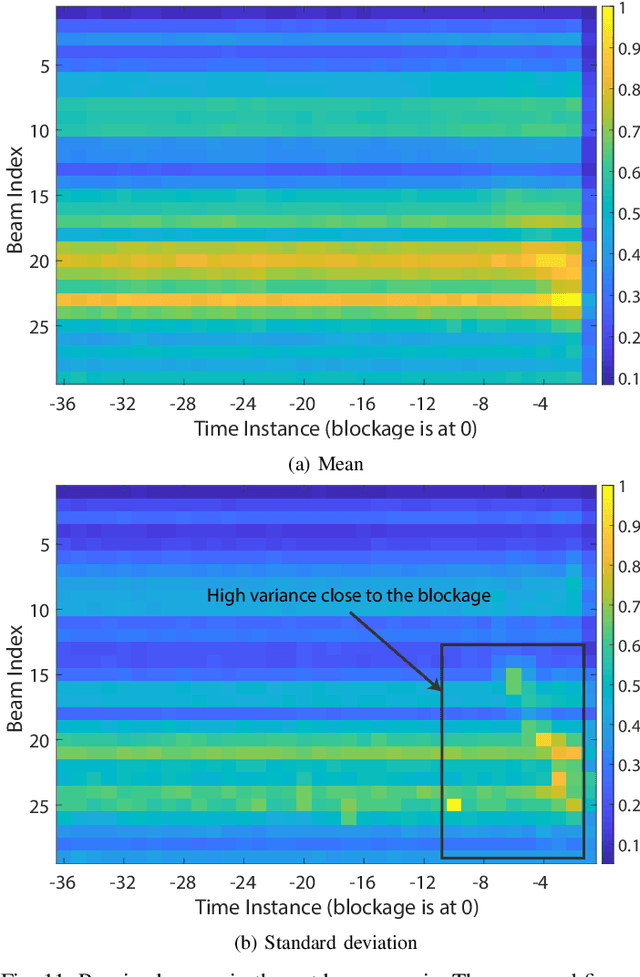
Overcoming the link blockage challenges is essential for enhancing the reliability and latency of millimeter wave (mmWave) and sub-terahertz (sub-THz) communication networks. Previous approaches relied mainly on either (i) multiple-connectivity, which under-utilizes the network resources, or on (ii) the use of out-of-band and non-RF sensors to predict link blockages, which is associated with increased cost and system complexity. In this paper, we propose a novel solution that relies only on in-band mmWave wireless measurements to proactively predict future dynamic line-of-sight (LOS) link blockages. The proposed solution utilizes deep neural networks and special patterns of received signal power, that we call pre-blockage wireless signatures to infer future blockages. Specifically, the developed machine learning models attempt to predict: (i) If a future blockage will occur? (ii) When will this blockage happen? (iii) What is the type of the blockage? And (iv) what is the direction of the moving blockage? To evaluate our proposed approach, we build a large-scale real-world dataset comprising nearly $0.5$ million data points (mmWave measurements) for both indoor and outdoor blockage scenarios. The results, using this dataset, show that the proposed approach can successfully predict the occurrence of future dynamic blockages with more than 85\% accuracy. Further, for the outdoor scenario with highly-mobile vehicular blockages, the proposed model can predict the exact time of the future blockage with less than $80$ms error for blockages happening within the future $500$ms. These results, among others, highlight the promising gains of the proposed proactive blockage prediction solution which could potentially enhance the reliability and latency of future wireless networks.
SIAM: Chiplet-based Scalable In-Memory Acceleration with Mesh for Deep Neural Networks
Aug 14, 2021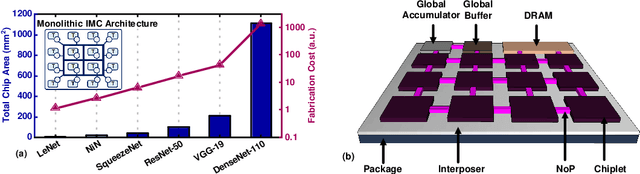
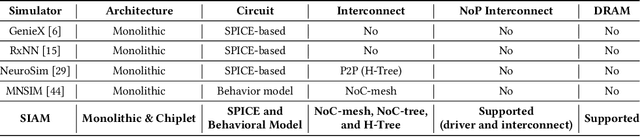
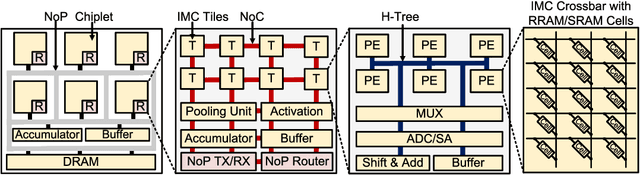
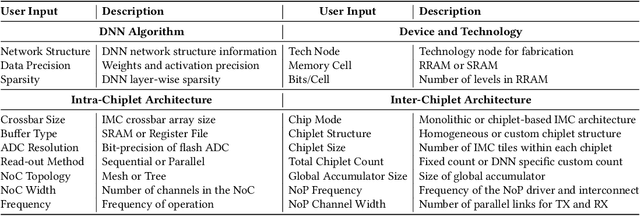
In-memory computing (IMC) on a monolithic chip for deep learning faces dramatic challenges on area, yield, and on-chip interconnection cost due to the ever-increasing model sizes. 2.5D integration or chiplet-based architectures interconnect multiple small chips (i.e., chiplets) to form a large computing system, presenting a feasible solution beyond a monolithic IMC architecture to accelerate large deep learning models. This paper presents a new benchmarking simulator, SIAM, to evaluate the performance of chiplet-based IMC architectures and explore the potential of such a paradigm shift in IMC architecture design. SIAM integrates device, circuit, architecture, network-on-chip (NoC), network-on-package (NoP), and DRAM access models to realize an end-to-end system. SIAM is scalable in its support of a wide range of deep neural networks (DNNs), customizable to various network structures and configurations, and capable of efficient design space exploration. We demonstrate the flexibility, scalability, and simulation speed of SIAM by benchmarking different state-of-the-art DNNs with CIFAR-10, CIFAR-100, and ImageNet datasets. We further calibrate the simulation results with a published silicon result, SIMBA. The chiplet-based IMC architecture obtained through SIAM shows 130$\times$ and 72$\times$ improvement in energy-efficiency for ResNet-50 on the ImageNet dataset compared to Nvidia V100 and T4 GPUs.
Communication and Computation Reduction for Split Learning using Asynchronous Training
Jul 20, 2021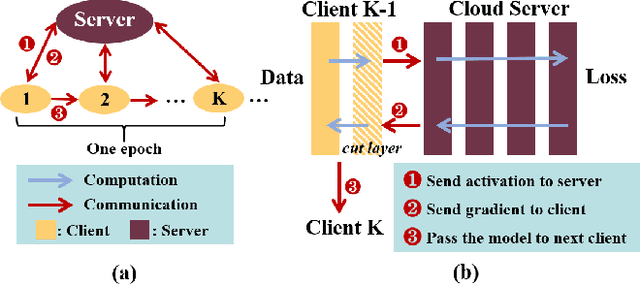
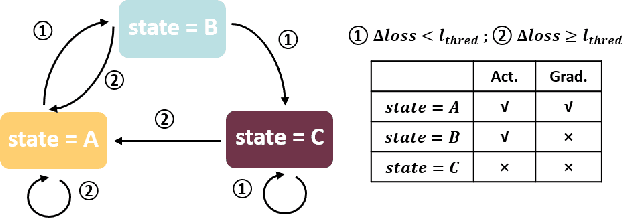
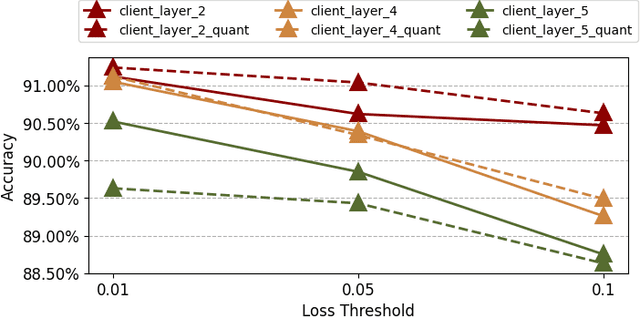
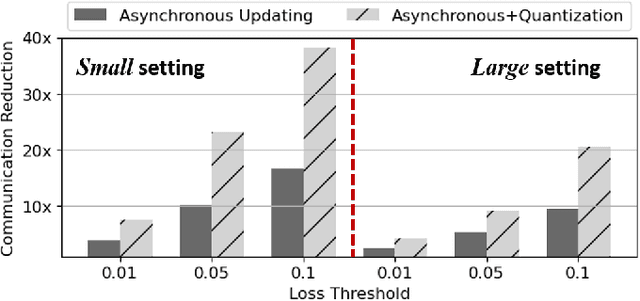
Split learning is a promising privacy-preserving distributed learning scheme that has low computation requirement at the edge device but has the disadvantage of high communication overhead between edge device and server. To reduce the communication overhead, this paper proposes a loss-based asynchronous training scheme that updates the client-side model less frequently and only sends/receives activations/gradients in selected epochs. To further reduce the communication overhead, the activations/gradients are quantized using 8-bit floating point prior to transmission. An added benefit of the proposed communication reduction method is that the computations at the client side are reduced due to reduction in the number of client model updates. Furthermore, the privacy of the proposed communication reduction based split learning method is almost the same as traditional split learning. Simulation results on VGG11, VGG13 and ResNet18 models on CIFAR-10 show that the communication cost is reduced by 1.64x-106.7x and the computations in the client are reduced by 2.86x-32.1x when the accuracy degradation is less than 0.5% for the single-client case. For 5 and 10-client cases, the communication cost reduction is 11.9x and 11.3x on VGG11 for 0.5% loss in accuracy.
Impact of On-Chip Interconnect on In-Memory Acceleration of Deep Neural Networks
Jul 06, 2021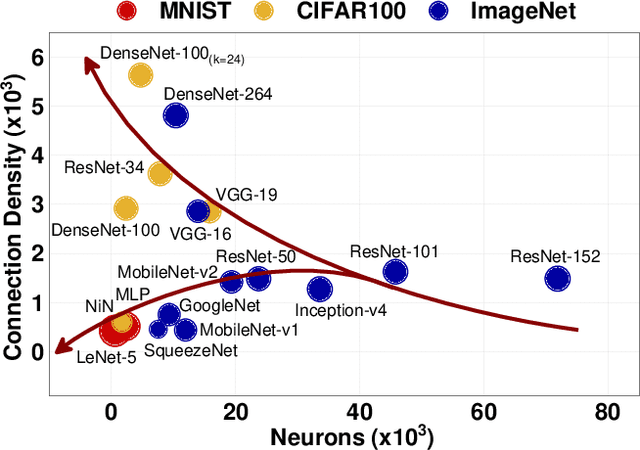
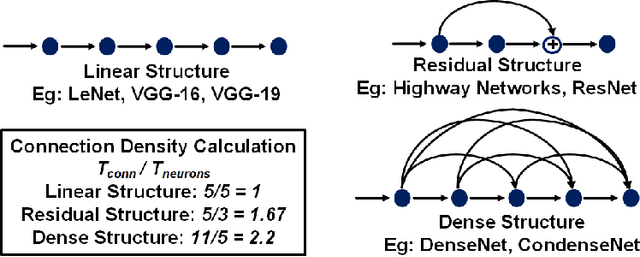

With the widespread use of Deep Neural Networks (DNNs), machine learning algorithms have evolved in two diverse directions -- one with ever-increasing connection density for better accuracy and the other with more compact sizing for energy efficiency. The increase in connection density increases on-chip data movement, which makes efficient on-chip communication a critical function of the DNN accelerator. The contribution of this work is threefold. First, we illustrate that the point-to-point (P2P)-based interconnect is incapable of handling a high volume of on-chip data movement for DNNs. Second, we evaluate P2P and network-on-chip (NoC) interconnect (with a regular topology such as a mesh) for SRAM- and ReRAM-based in-memory computing (IMC) architectures for a range of DNNs. This analysis shows the necessity for the optimal interconnect choice for an IMC DNN accelerator. Finally, we perform an experimental evaluation for different DNNs to empirically obtain the performance of the IMC architecture with both NoC-tree and NoC-mesh. We conclude that, at the tile level, NoC-tree is appropriate for compact DNNs employed at the edge, and NoC-mesh is necessary to accelerate DNNs with high connection density. Furthermore, we propose a technique to determine the optimal choice of interconnect for any given DNN. In this technique, we use analytical models of NoC to evaluate end-to-end communication latency of any given DNN. We demonstrate that the interconnect optimization in the IMC architecture results in up to 6$\times$ improvement in energy-delay-area product for VGG-19 inference compared to the state-of-the-art ReRAM-based IMC architectures.
RA-BNN: Constructing Robust & Accurate Binary Neural Network to Simultaneously Defend Adversarial Bit-Flip Attack and Improve Accuracy
Mar 22, 2021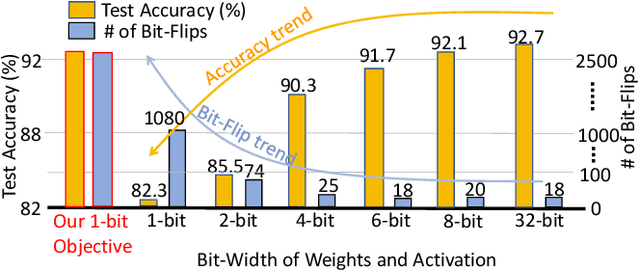
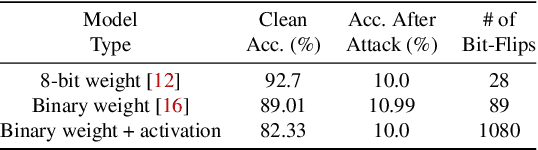
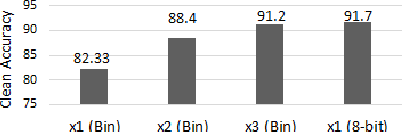

Recently developed adversarial weight attack, a.k.a. bit-flip attack (BFA), has shown enormous success in compromising Deep Neural Network (DNN) performance with an extremely small amount of model parameter perturbation. To defend against this threat, we propose RA-BNN that adopts a complete binary (i.e., for both weights and activation) neural network (BNN) to significantly improve DNN model robustness (defined as the number of bit-flips required to degrade the accuracy to as low as a random guess). However, such an aggressive low bit-width model suffers from poor clean (i.e., no attack) inference accuracy. To counter this, we propose a novel and efficient two-stage network growing method, named Early-Growth. It selectively grows the channel size of each BNN layer based on channel-wise binary masks training with Gumbel-Sigmoid function. Apart from recovering the inference accuracy, our RA-BNN after growing also shows significantly higher resistance to BFA. Our evaluation of the CIFAR-10 dataset shows that the proposed RA-BNN can improve the clean model accuracy by ~2-8 %, compared with a baseline BNN, while simultaneously improving the resistance to BFA by more than 125 x. Moreover, on ImageNet, with a sufficiently large (e.g., 5,000) amount of bit-flips, the baseline BNN accuracy drops to 4.3 % from 51.9 %, while our RA-BNN accuracy only drops to 37.1 % from 60.9 % (9 % clean accuracy improvement).