 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDISHA: Low-Energy Sparse Transformer at Edge for Outdoor Navigation for the Visually Impaired Individuals
Jun 22, 2024Assistive technology for visually impaired individuals is extremely useful to make them independent of another human being in performing day-to-day chores and instill confidence in them. One of the important aspects of assistive technology is outdoor navigation for visually impaired people. While there exist several techniques for outdoor navigation in the literature, they are mainly limited to obstacle detection. However, navigating a visually impaired person through the sidewalk (while the person is walking outside) is important too. Moreover, the assistive technology should ensure low-energy operation to extend the battery life of the device. Therefore, in this work, we propose an end-to-end technology deployed on an edge device to assist visually impaired people. Specifically, we propose a novel pruning technique for transformer algorithm which detects sidewalk. The pruning technique ensures low latency of execution and low energy consumption when the pruned transformer algorithm is deployed on the edge device. Extensive experimental evaluation shows that our proposed technology provides up to 32.49% improvement in accuracy and 1.4 hours of extension in battery life with respect to a baseline technique.
COIN: Communication-Aware In-Memory Acceleration for Graph Convolutional Networks
May 15, 2022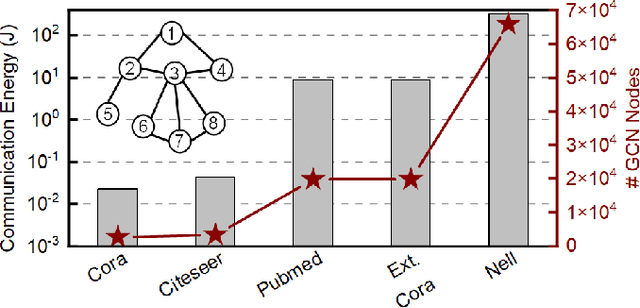
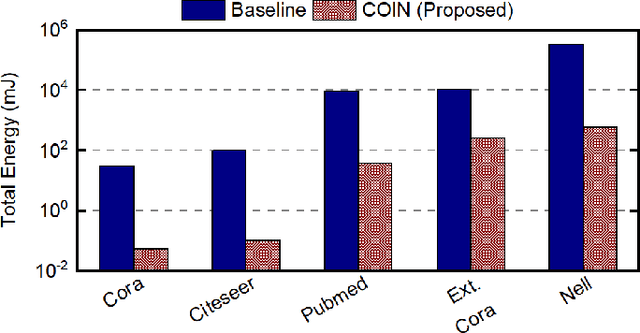
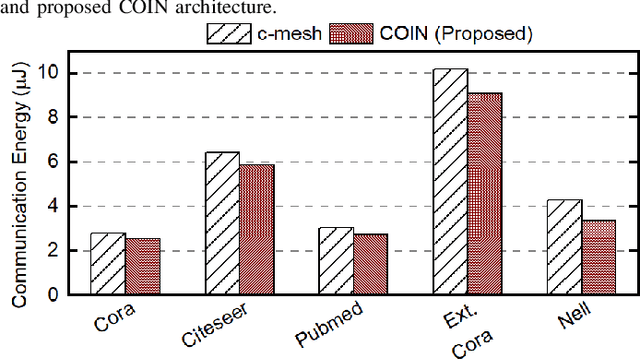
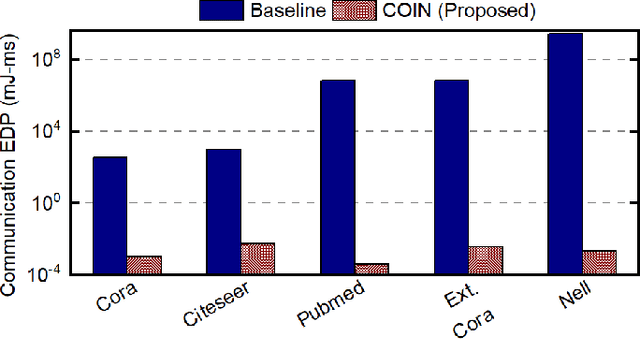
Graph convolutional networks (GCNs) have shown remarkable learning capabilities when processing graph-structured data found inherently in many application areas. GCNs distribute the outputs of neural networks embedded in each vertex over multiple iterations to take advantage of the relations captured by the underlying graphs. Consequently, they incur a significant amount of computation and irregular communication overheads, which call for GCN-specific hardware accelerators. To this end, this paper presents a communication-aware in-memory computing architecture (COIN) for GCN hardware acceleration. Besides accelerating the computation using custom compute elements (CE) and in-memory computing, COIN aims at minimizing the intra- and inter-CE communication in GCN operations to optimize the performance and energy efficiency. Experimental evaluations with widely used datasets show up to 105x improvement in energy consumption compared to state-of-the-art GCN accelerator.
SIAM: Chiplet-based Scalable In-Memory Acceleration with Mesh for Deep Neural Networks
Aug 14, 2021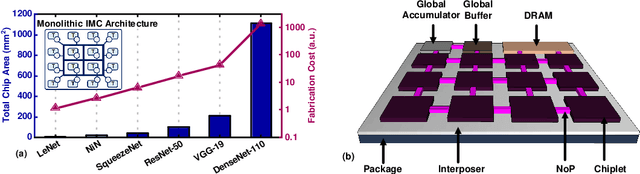
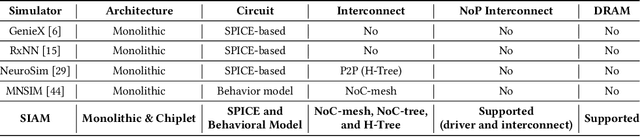
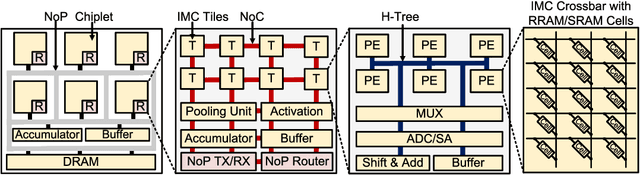
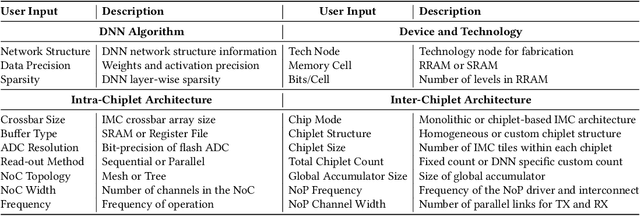
In-memory computing (IMC) on a monolithic chip for deep learning faces dramatic challenges on area, yield, and on-chip interconnection cost due to the ever-increasing model sizes. 2.5D integration or chiplet-based architectures interconnect multiple small chips (i.e., chiplets) to form a large computing system, presenting a feasible solution beyond a monolithic IMC architecture to accelerate large deep learning models. This paper presents a new benchmarking simulator, SIAM, to evaluate the performance of chiplet-based IMC architectures and explore the potential of such a paradigm shift in IMC architecture design. SIAM integrates device, circuit, architecture, network-on-chip (NoC), network-on-package (NoP), and DRAM access models to realize an end-to-end system. SIAM is scalable in its support of a wide range of deep neural networks (DNNs), customizable to various network structures and configurations, and capable of efficient design space exploration. We demonstrate the flexibility, scalability, and simulation speed of SIAM by benchmarking different state-of-the-art DNNs with CIFAR-10, CIFAR-100, and ImageNet datasets. We further calibrate the simulation results with a published silicon result, SIMBA. The chiplet-based IMC architecture obtained through SIAM shows 130$\times$ and 72$\times$ improvement in energy-efficiency for ResNet-50 on the ImageNet dataset compared to Nvidia V100 and T4 GPUs.
FLASH: Fast Neural Architecture Search with Hardware Optimization
Aug 01, 2021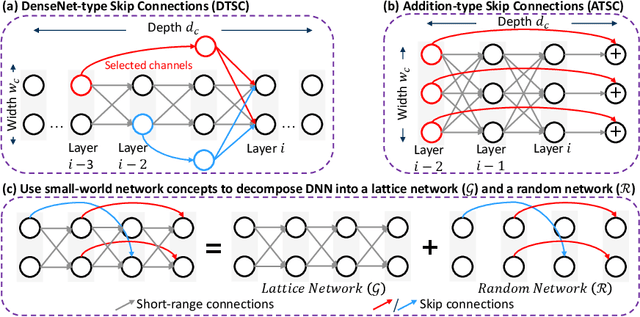

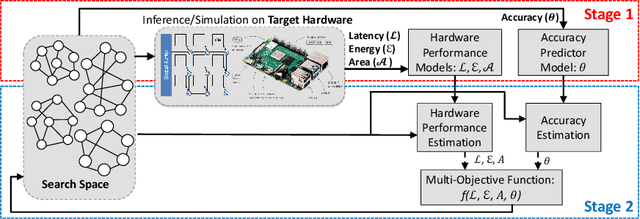

Neural architecture search (NAS) is a promising technique to design efficient and high-performance deep neural networks (DNNs). As the performance requirements of ML applications grow continuously, the hardware accelerators start playing a central role in DNN design. This trend makes NAS even more complicated and time-consuming for most real applications. This paper proposes FLASH, a very fast NAS methodology that co-optimizes the DNN accuracy and performance on a real hardware platform. As the main theoretical contribution, we first propose the NN-Degree, an analytical metric to quantify the topological characteristics of DNNs with skip connections (e.g., DenseNets, ResNets, Wide-ResNets, and MobileNets). The newly proposed NN-Degree allows us to do training-free NAS within one second and build an accuracy predictor by training as few as 25 samples out of a vast search space with more than 63 billion configurations. Second, by performing inference on the target hardware, we fine-tune and validate our analytical models to estimate the latency, area, and energy consumption of various DNN architectures while executing standard ML datasets. Third, we construct a hierarchical algorithm based on simplicial homology global optimization (SHGO) to optimize the model-architecture co-design process, while considering the area, latency, and energy consumption of the target hardware. We demonstrate that, compared to the state-of-the-art NAS approaches, our proposed hierarchical SHGO-based algorithm enables more than four orders of magnitude speedup (specifically, the execution time of the proposed algorithm is about 0.1 seconds). Finally, our experimental evaluations show that FLASH is easily transferable to different hardware architectures, thus enabling us to do NAS on a Raspberry Pi-3B processor in less than 3 seconds.
Impact of On-Chip Interconnect on In-Memory Acceleration of Deep Neural Networks
Jul 06, 2021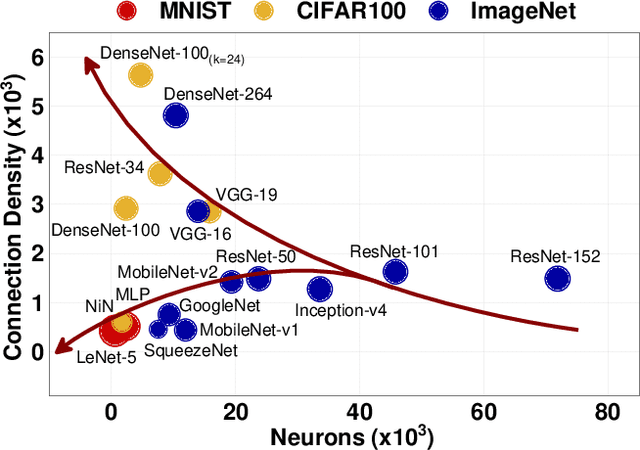
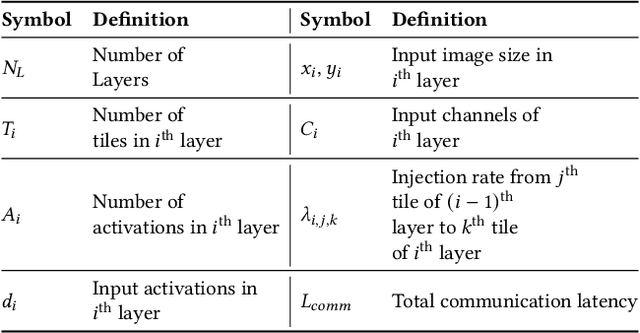
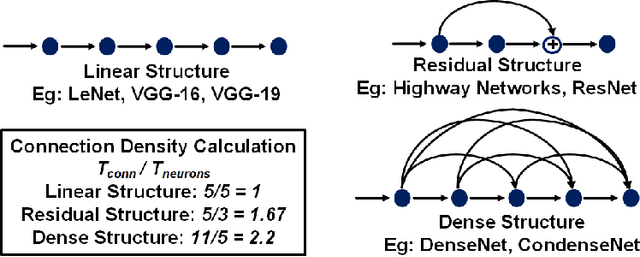

With the widespread use of Deep Neural Networks (DNNs), machine learning algorithms have evolved in two diverse directions -- one with ever-increasing connection density for better accuracy and the other with more compact sizing for energy efficiency. The increase in connection density increases on-chip data movement, which makes efficient on-chip communication a critical function of the DNN accelerator. The contribution of this work is threefold. First, we illustrate that the point-to-point (P2P)-based interconnect is incapable of handling a high volume of on-chip data movement for DNNs. Second, we evaluate P2P and network-on-chip (NoC) interconnect (with a regular topology such as a mesh) for SRAM- and ReRAM-based in-memory computing (IMC) architectures for a range of DNNs. This analysis shows the necessity for the optimal interconnect choice for an IMC DNN accelerator. Finally, we perform an experimental evaluation for different DNNs to empirically obtain the performance of the IMC architecture with both NoC-tree and NoC-mesh. We conclude that, at the tile level, NoC-tree is appropriate for compact DNNs employed at the edge, and NoC-mesh is necessary to accelerate DNNs with high connection density. Furthermore, we propose a technique to determine the optimal choice of interconnect for any given DNN. In this technique, we use analytical models of NoC to evaluate end-to-end communication latency of any given DNN. We demonstrate that the interconnect optimization in the IMC architecture results in up to 6$\times$ improvement in energy-delay-area product for VGG-19 inference compared to the state-of-the-art ReRAM-based IMC architectures.
Online Adaptive Learning for Runtime Resource Management of Heterogeneous SoCs
Aug 22, 2020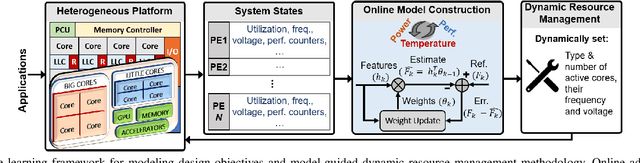
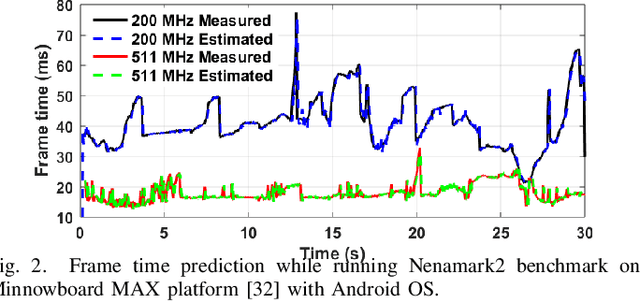
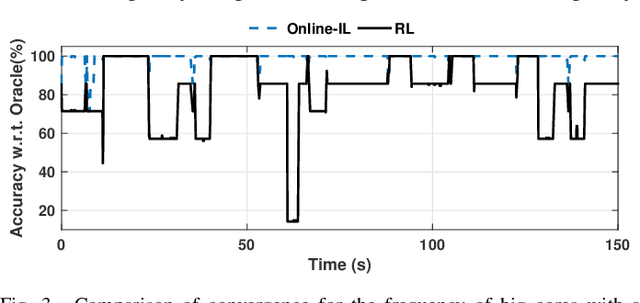
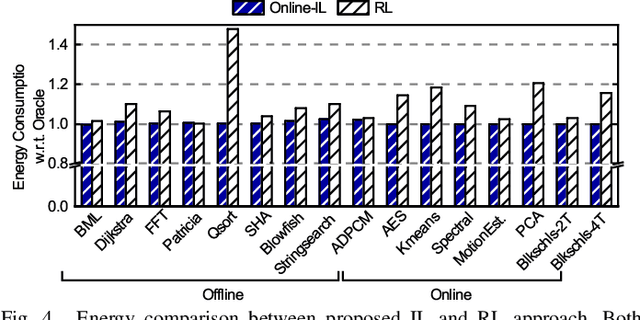
Dynamic resource management has become one of the major areas of research in modern computer and communication system design due to lower power consumption and higher performance demands. The number of integrated cores, level of heterogeneity and amount of control knobs increase steadily. As a result, the system complexity is increasing faster than our ability to optimize and dynamically manage the resources. Moreover, offline approaches are sub-optimal due to workload variations and large volume of new applications unknown at design time. This paper first reviews recent online learning techniques for predicting system performance, power, and temperature. Then, we describe the use of predictive models for online control using two modern approaches: imitation learning (IL) and an explicit nonlinear model predictive control (NMPC). Evaluations on a commercial mobile platform with 16 benchmarks show that the IL approach successfully adapts the control policy to unknown applications. The explicit NMPC provides 25% energy savings compared to a state-of-the-art algorithm for multi-variable power management of modern GPU sub-systems.
An Energy-Aware Online Learning Framework for Resource Management in Heterogeneous Platforms
Mar 20, 2020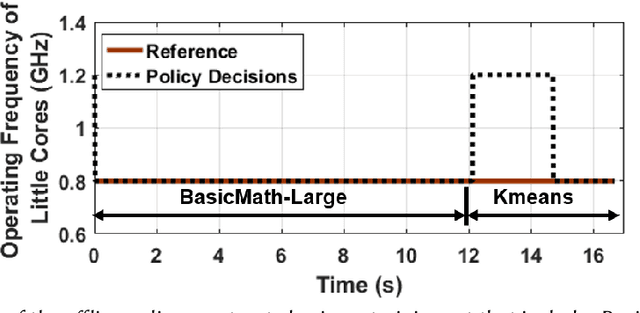
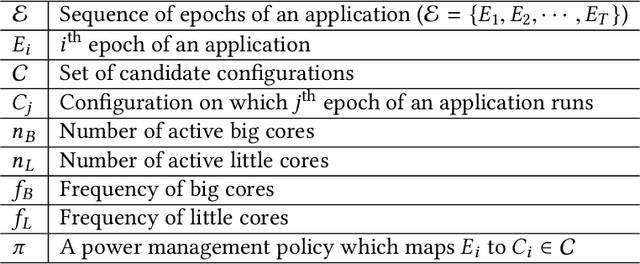

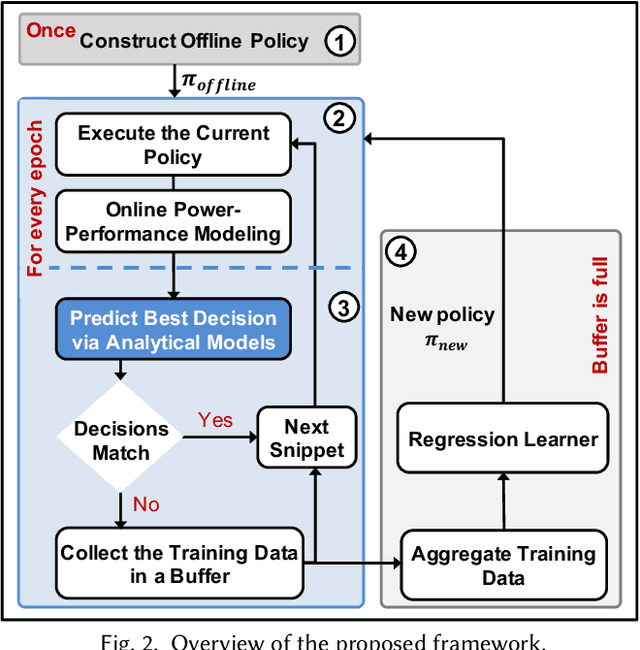
Mobile platforms must satisfy the contradictory requirements of fast response time and minimum energy consumption as a function of dynamically changing applications. To address this need, system-on-chips (SoC) that are at the heart of these devices provide a variety of control knobs, such as the number of active cores and their voltage/frequency levels. Controlling these knobs optimally at runtime is challenging for two reasons. First, the large configuration space prohibits exhaustive solutions. Second, control policies designed offline are at best sub-optimal since many potential new applications are unknown at design-time. We address these challenges by proposing an online imitation learning approach. Our key idea is to construct an offline policy and adapt it online to new applications to optimize a given metric (e.g., energy). The proposed methodology leverages the supervision enabled by power-performance models learned at runtime. We demonstrate its effectiveness on a commercial mobile platform with 16 diverse benchmarks. Our approach successfully adapts the control policy to an unknown application after executing less than 25% of its instructions.