 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAtleus: Accelerating Transformers on the Edge Enabled by 3D Heterogeneous Manycore Architectures
Jan 16, 2025Transformer architectures have become the standard neural network model for various machine learning applications including natural language processing and computer vision. However, the compute and memory requirements introduced by transformer models make them challenging to adopt for edge applications. Furthermore, fine-tuning pre-trained transformers (e.g., foundation models) is a common task to enhance the model's predictive performance on specific tasks/applications. Existing transformer accelerators are oblivious to complexities introduced by fine-tuning. In this paper, we propose the design of a three-dimensional (3D) heterogeneous architecture referred to as Atleus that incorporates heterogeneous computing resources specifically optimized to accelerate transformer models for the dual purposes of fine-tuning and inference. Specifically, Atleus utilizes non-volatile memory and systolic array for accelerating transformer computational kernels using an integrated 3D platform. Moreover, we design a suitable NoC to achieve high performance and energy efficiency. Finally, Atleus adopts an effective quantization scheme to support model compression. Experimental results demonstrate that Atleus outperforms existing state-of-the-art by up to 56x and 64.5x in terms of performance and energy efficiency respectively
HeTraX: Energy Efficient 3D Heterogeneous Manycore Architecture for Transformer Acceleration
Aug 06, 2024Transformers have revolutionized deep learning and generative modeling to enable unprecedented advancements in natural language processing tasks and beyond. However, designing hardware accelerators for executing transformer models is challenging due to the wide variety of computing kernels involved in the transformer architecture. Existing accelerators are either inadequate to accelerate end-to-end transformer models or suffer notable thermal limitations. In this paper, we propose the design of a three-dimensional heterogeneous architecture referred to as HeTraX specifically optimized to accelerate end-to-end transformer models. HeTraX employs hardware resources aligned with the computational kernels of transformers and optimizes both performance and energy. Experimental results show that HeTraX outperforms existing state-of-the-art by up to 5.6x in speedup and improves EDP by 14.5x while ensuring thermally feasibility.
Dataflow-Aware PIM-Enabled Manycore Architecture for Deep Learning Workloads
Mar 28, 2024

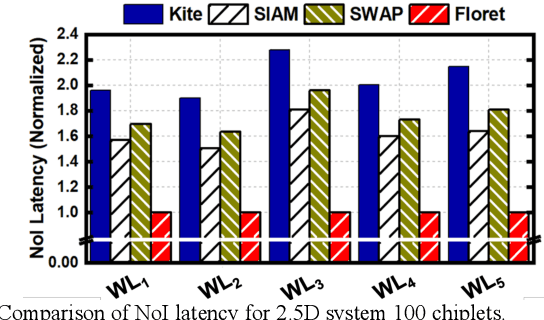
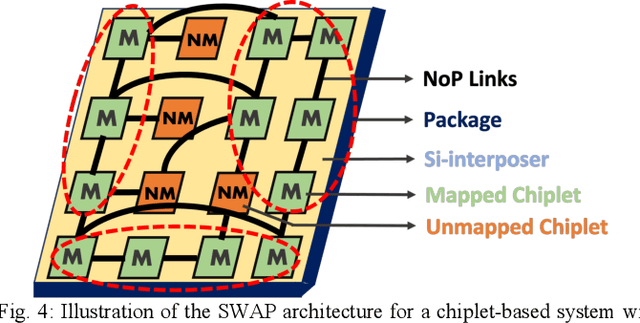
Processing-in-memory (PIM) has emerged as an enabler for the energy-efficient and high-performance acceleration of deep learning (DL) workloads. Resistive random-access memory (ReRAM) is one of the most promising technologies to implement PIM. However, as the complexity of Deep convolutional neural networks (DNNs) grows, we need to design a manycore architecture with multiple ReRAM-based processing elements (PEs) on a single chip. Existing PIM-based architectures mostly focus on computation while ignoring the role of communication. ReRAM-based tiled manycore architectures often involve many Processing Elements (PEs), which need to be interconnected via an efficient on-chip communication infrastructure. Simply allocating more resources (ReRAMs) to speed up only computation is ineffective if the communication infrastructure cannot keep up with it. In this paper, we highlight the design principles of a dataflow-aware PIM-enabled manycore platform tailor-made for various types of DL workloads. We consider the design challenges with both 2.5D interposer- and 3D integration-enabled architectures.
FARe: Fault-Aware GNN Training on ReRAM-based PIM Accelerators
Jan 19, 2024


Resistive random-access memory (ReRAM)-based processing-in-memory (PIM) architecture is an attractive solution for training Graph Neural Networks (GNNs) on edge platforms. However, the immature fabrication process and limited write endurance of ReRAMs make them prone to hardware faults, thereby limiting their widespread adoption for GNN training. Further, the existing fault-tolerant solutions prove inadequate for effectively training GNNs in the presence of faults. In this paper, we propose a fault-aware framework referred to as FARe that mitigates the effect of faults during GNN training. FARe outperforms existing approaches in terms of both accuracy and timing overhead. Experimental results demonstrate that FARe framework can restore GNN test accuracy by 47.6% on faulty ReRAM hardware with a ~1% timing overhead compared to the fault-free counterpart.
SETGAN: Scale and Energy Trade-off GANs for Image Applications on Mobile Platforms
Mar 23, 2021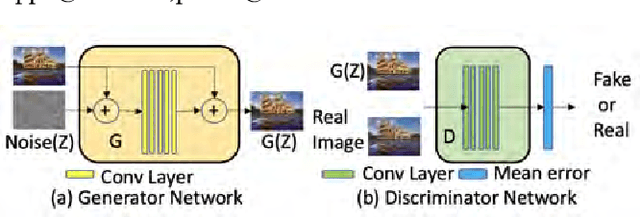

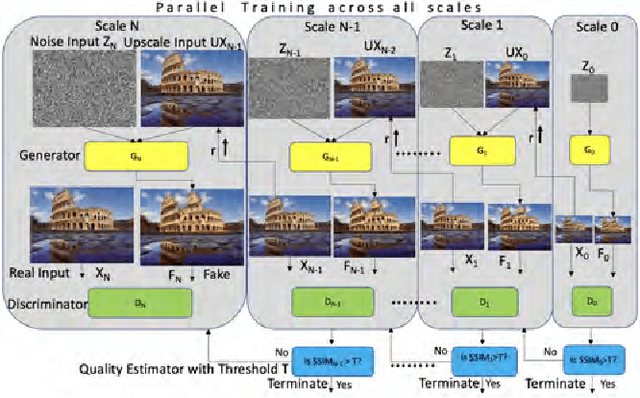
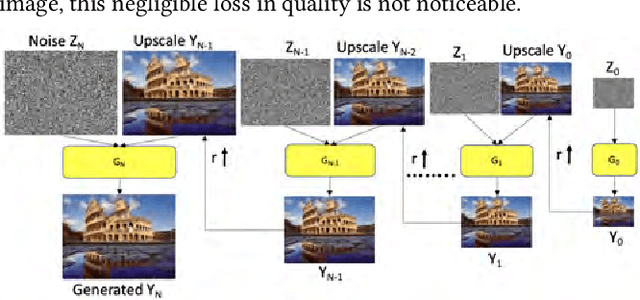
We consider the task of photo-realistic unconditional image generation (generate high quality, diverse samples that carry the same visual content as the image) on mobile platforms using Generative Adversarial Networks (GANs). In this paper, we propose a novel approach to trade-off image generation accuracy of a GAN for the energy consumed (compute) at run-time called Scale-Energy Tradeoff GAN (SETGAN). GANs usually take a long time to train and consume a huge memory hence making it difficult to run on edge devices. The key idea behind SETGAN for an image generation task is for a given input image, we train a GAN on a remote server and use the trained model on edge devices. We use SinGAN, a single image unconditional generative model, that contains a pyramid of fully convolutional GANs, each responsible for learning the patch distribution at a different scale of the image. During the training process, we determine the optimal number of scales for a given input image and the energy constraint from the target edge device. Results show that with SETGAN's unique client-server-based architecture, we were able to achieve a 56% gain in energy for a loss of 3% to 12% SSIM accuracy. Also, with the parallel multi-scale training, we obtain around 4x gain in training time on the server.
An Energy-Aware Online Learning Framework for Resource Management in Heterogeneous Platforms
Mar 20, 2020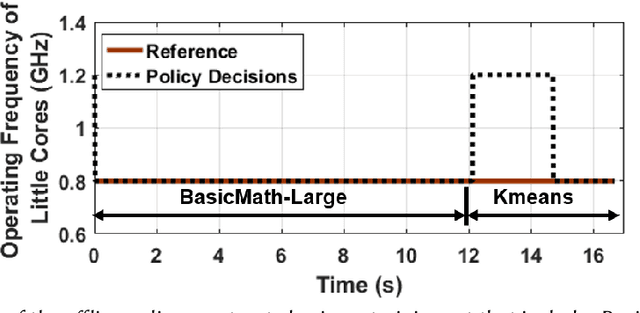
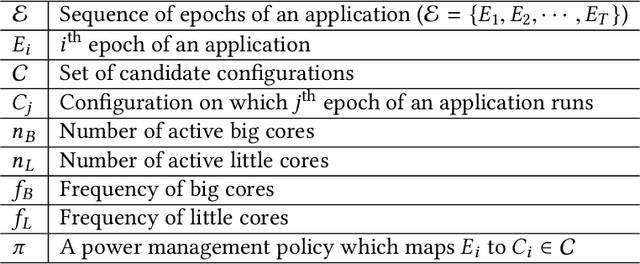

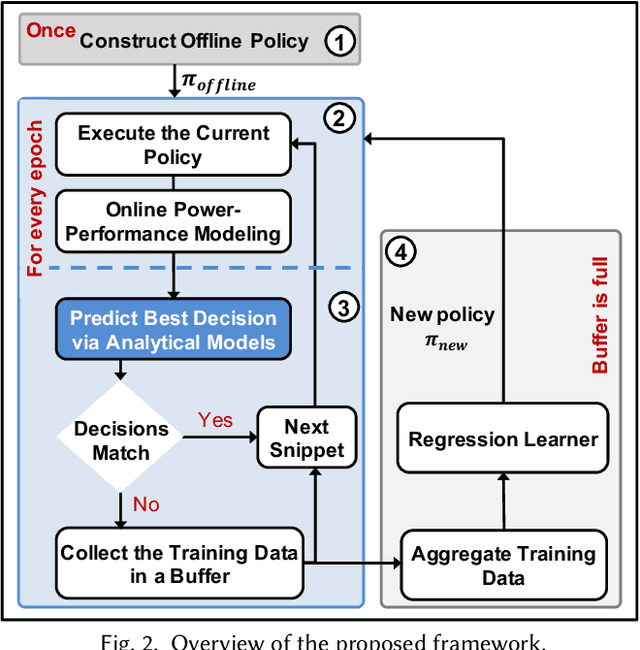
Mobile platforms must satisfy the contradictory requirements of fast response time and minimum energy consumption as a function of dynamically changing applications. To address this need, system-on-chips (SoC) that are at the heart of these devices provide a variety of control knobs, such as the number of active cores and their voltage/frequency levels. Controlling these knobs optimally at runtime is challenging for two reasons. First, the large configuration space prohibits exhaustive solutions. Second, control policies designed offline are at best sub-optimal since many potential new applications are unknown at design-time. We address these challenges by proposing an online imitation learning approach. Our key idea is to construct an offline policy and adapt it online to new applications to optimize a given metric (e.g., energy). The proposed methodology leverages the supervision enabled by power-performance models learned at runtime. We demonstrate its effectiveness on a commercial mobile platform with 16 diverse benchmarks. Our approach successfully adapts the control policy to an unknown application after executing less than 25% of its instructions.
Trading-off Accuracy and Energy of Deep Inference on Embedded Systems: A Co-Design Approach
Jan 29, 2019
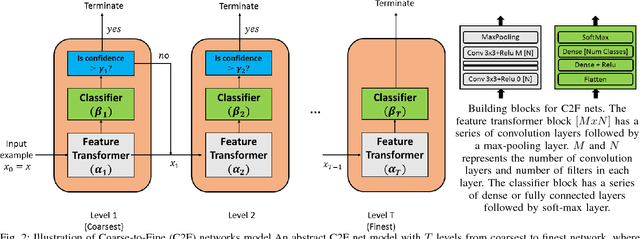
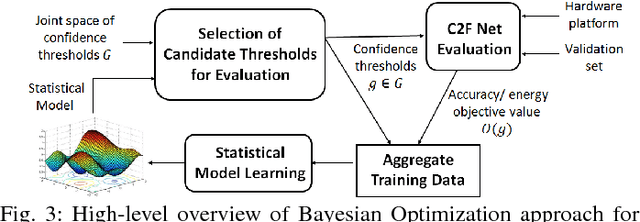
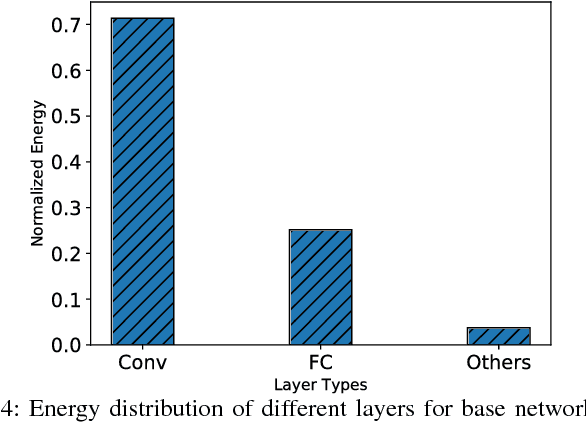
Deep neural networks have seen tremendous success for different modalities of data including images, videos, and speech. This success has led to their deployment in mobile and embedded systems for real-time applications. However, making repeated inferences using deep networks on embedded systems poses significant challenges due to constrained resources (e.g., energy and computing power). To address these challenges, we develop a principled co-design approach. Building on prior work, we develop a formalism referred to as Coarse-to-Fine Networks (C2F Nets) that allow us to employ classifiers of varying complexity to make predictions. We propose a principled optimization algorithm to automatically configure C2F Nets for a specified trade-off between accuracy and energy consumption for inference. The key idea is to select a classifier on-the-fly whose complexity is proportional to the hardness of the input example: simple classifiers for easy inputs and complex classifiers for hard inputs. We perform comprehensive experimental evaluation using four different C2F Net architectures on multiple real-world image classification tasks. Our results show that optimized C2F Net can reduce the Energy Delay Product (EDP) by 27 to 60 percent with no loss in accuracy when compared to the baseline solution, where all predictions are made using the most complex classifier in C2F Net.
* Published in IEEE Trans. on CAD of Integrated Circuits and Systems
Learning-based Application-Agnostic 3D NoC Design for Heterogeneous Manycore Systems
Oct 20, 2018
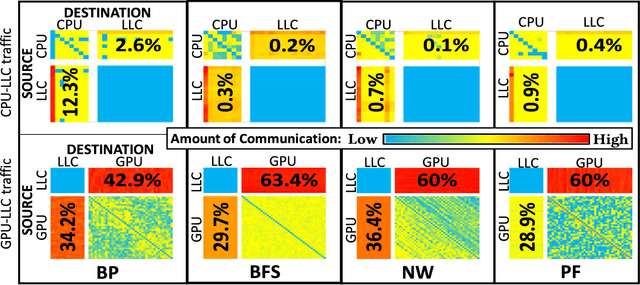
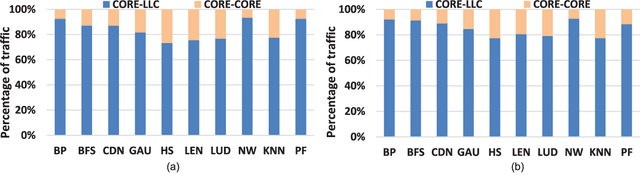
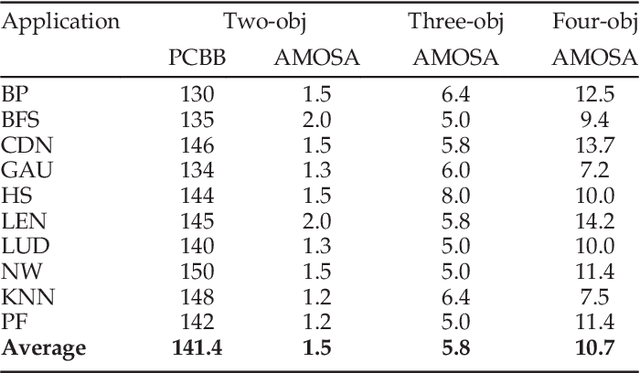
The rising use of deep learning and other big-data algorithms has led to an increasing demand for hardware platforms that are computationally powerful, yet energy-efficient. Due to the amount of data parallelism in these algorithms, high-performance 3D manycore platforms that incorporate both CPUs and GPUs present a promising direction. However, as systems use heterogeneity (e.g., a combination of CPUs, GPUs, and accelerators) to improve performance and efficiency, it becomes more pertinent to address the distinct and likely conflicting communication requirements (e.g., CPU memory access latency or GPU network throughput) that arise from such heterogeneity. Unfortunately, it is difficult to quickly explore the hardware design space and choose appropriate tradeoffs between these heterogeneous requirements. To address these challenges, we propose the design of a 3D Network-on-Chip (NoC) for heterogeneous manycore platforms that considers the appropriate design objectives for a 3D heterogeneous system and explores various tradeoffs using an efficient ML-based multi-objective optimization technique. The proposed design space exploration considers the various requirements of its heterogeneous components and generates a set of 3D NoC architectures that efficiently trades off these design objectives. Our findings show that by jointly considering these requirements (latency, throughput, temperature, and energy), we can achieve 9.6% better Energy-Delay Product on average at nearly iso-temperature conditions when compared to a thermally-optimized design for 3D heterogeneous NoCs. More importantly, our results suggest that our 3D NoCs optimized for a few applications can be generalized for unknown applications as well. Our results show that these generalized 3D NoCs only incur a 1.8% (36-tile system) and 1.1% (64-tile system) average performance loss compared to application-specific NoCs.
Machine Learning and Manycore Systems Design: A Serendipitous Symbiosis
Nov 30, 2017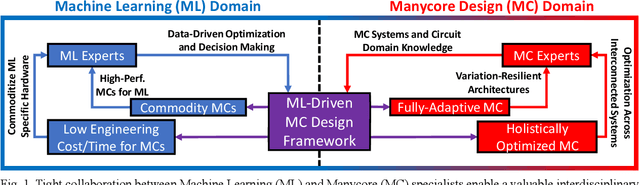

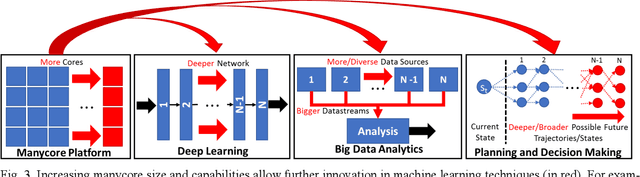
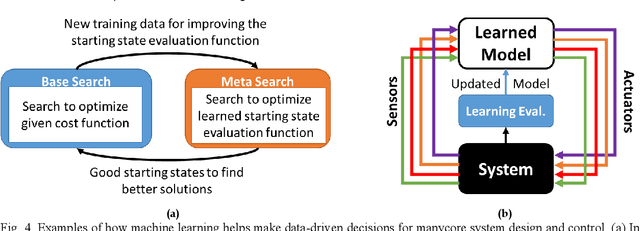
Tight collaboration between experts of machine learning and manycore system design is necessary to create a data-driven manycore design framework that integrates both learning and expert knowledge. Such a framework will be necessary to address the rising complexity of designing large-scale manycore systems and machine learning techniques.