 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeeMamba: Efficient Acceleration Framework for Mamba Models in Edge Computing
Aug 14, 2025State Space Model (SSM)-based machine learning architectures have recently gained significant attention for processing sequential data. Mamba, a recent sequence-to-sequence SSM, offers competitive accuracy with superior computational efficiency compared to state-of-the-art transformer models. While this advantage makes Mamba particularly promising for resource-constrained edge devices, no hardware acceleration frameworks are currently optimized for deploying it in such environments. This paper presents eMamba, a comprehensive end-to-end hardware acceleration framework explicitly designed for deploying Mamba models on edge platforms. eMamba maximizes computational efficiency by replacing complex normalization layers with lightweight hardware-aware alternatives and approximating expensive operations, such as SiLU activation and exponentiation, considering the target applications. Then, it performs an approximation-aware neural architecture search (NAS) to tune the learnable parameters used during approximation. Evaluations with Fashion-MNIST, CIFAR-10, and MARS, an open-source human pose estimation dataset, show eMamba achieves comparable accuracy to state-of-the-art techniques using 1.63-19.9$\times$ fewer parameters. In addition, it generalizes well to large-scale natural language tasks, demonstrating stable perplexity across varying sequence lengths on the WikiText2 dataset. We also quantize and implement the entire eMamba pipeline on an AMD ZCU102 FPGA and ASIC using GlobalFoundries (GF) 22 nm technology. Experimental results show 4.95-5.62$\times$ lower latency and 2.22-9.95$\times$ higher throughput, with 4.77$\times$ smaller area, 9.84$\times$ lower power, and 48.6$\times$ lower energy consumption than baseline solutions while maintaining competitive accuracy.
PD-MORL: Preference-Driven Multi-Objective Reinforcement Learning Algorithm
Aug 16, 2022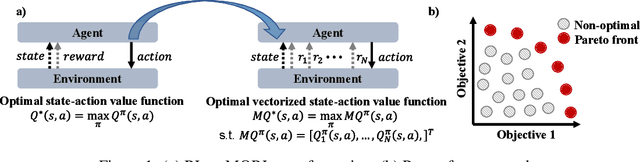

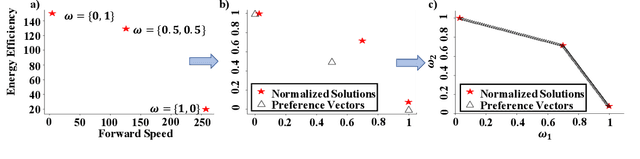
Many real-world problems involve multiple, possibly conflicting, objectives. Multi-objective reinforcement learning (MORL) approaches have emerged to tackle these problems by maximizing a joint objective function weighted by a preference vector. These approaches find fixed customized policies corresponding to preference vectors specified during training. However, the design constraints and objectives typically change dynamically in real-life scenarios. Furthermore, storing a policy for each potential preference is not scalable. Hence, obtaining a set of Pareto front solutions for the entire preference space in a given domain with a single training is critical. To this end, we propose a novel MORL algorithm that trains a single universal network to cover the entire preference space. The proposed approach, Preference-Driven MORL (PD-MORL), utilizes the preferences as guidance to update the network parameters. After demonstrating PD-MORL using classical Deep Sea Treasure and Fruit Tree Navigation benchmarks, we evaluate its performance on challenging multi-objective continuous control tasks.
COIN: Communication-Aware In-Memory Acceleration for Graph Convolutional Networks
May 15, 2022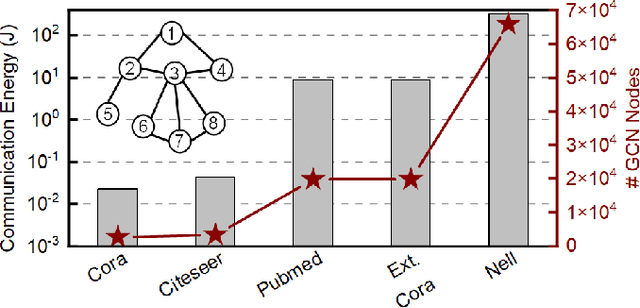
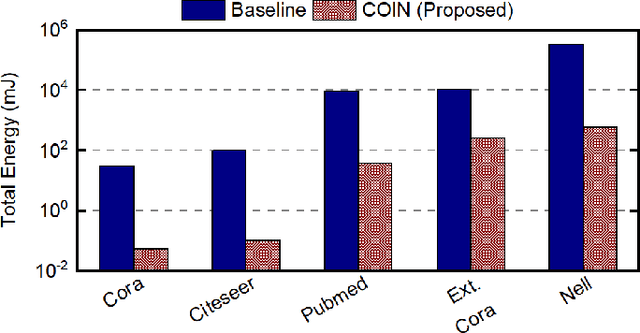
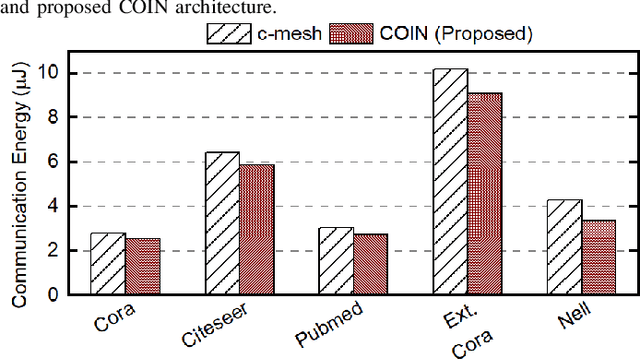
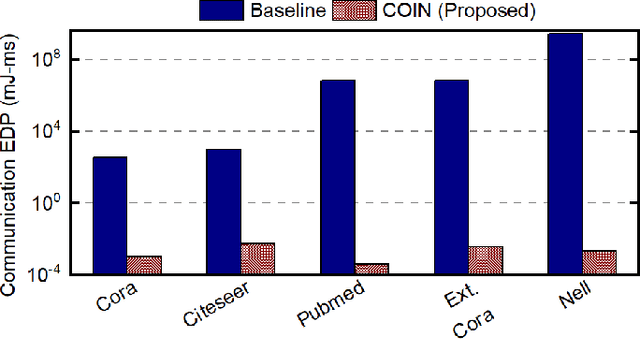
Graph convolutional networks (GCNs) have shown remarkable learning capabilities when processing graph-structured data found inherently in many application areas. GCNs distribute the outputs of neural networks embedded in each vertex over multiple iterations to take advantage of the relations captured by the underlying graphs. Consequently, they incur a significant amount of computation and irregular communication overheads, which call for GCN-specific hardware accelerators. To this end, this paper presents a communication-aware in-memory computing architecture (COIN) for GCN hardware acceleration. Besides accelerating the computation using custom compute elements (CE) and in-memory computing, COIN aims at minimizing the intra- and inter-CE communication in GCN operations to optimize the performance and energy efficiency. Experimental evaluations with widely used datasets show up to 105x improvement in energy consumption compared to state-of-the-art GCN accelerator.
Fast and Scalable Human Pose Estimation using mmWave Point Cloud
Apr 29, 2022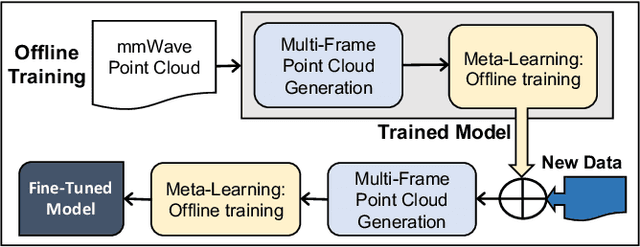
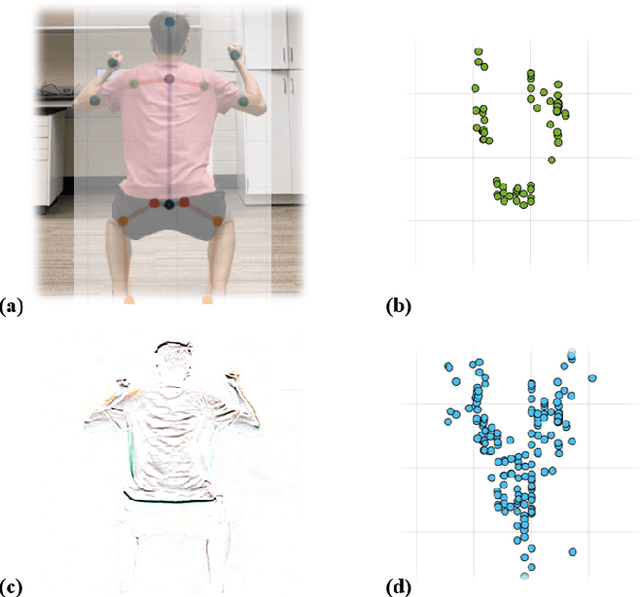
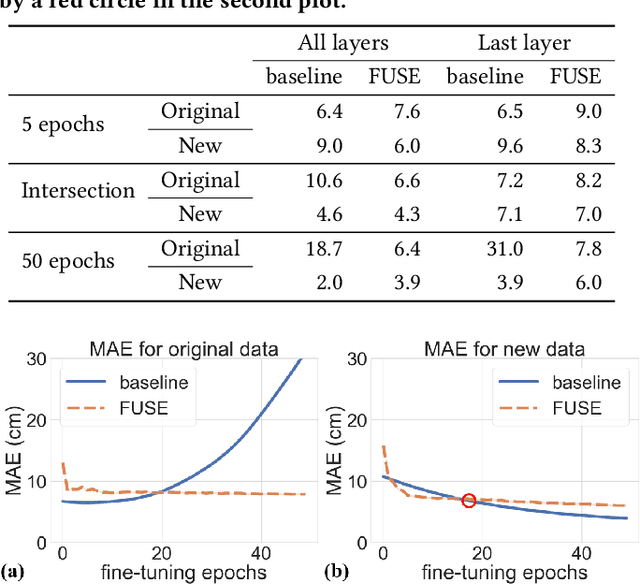
Millimeter-Wave (mmWave) radar can enable high-resolution human pose estimation with low cost and computational requirements. However, mmWave data point cloud, the primary input to processing algorithms, is highly sparse and carries significantly less information than other alternatives such as video frames. Furthermore, the scarce labeled mmWave data impedes the development of machine learning (ML) models that can generalize to unseen scenarios. We propose a fast and scalable human pose estimation (FUSE) framework that combines multi-frame representation and meta-learning to address these challenges. Experimental evaluations show that FUSE adapts to the unseen scenarios 4$\times$ faster than current supervised learning approaches and estimates human joint coordinates with about 7 cm mean absolute error.
tinyMAN: Lightweight Energy Manager using Reinforcement Learning for Energy Harvesting Wearable IoT Devices
Feb 18, 2022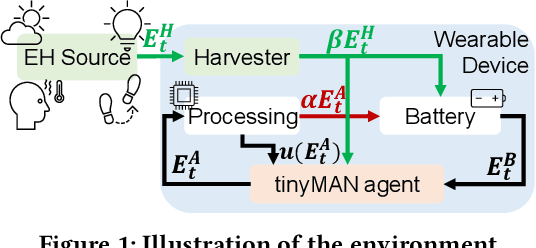

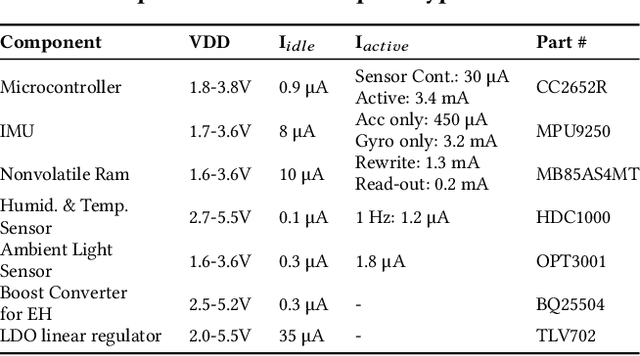
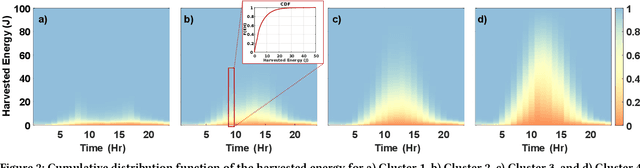
Advances in low-power electronics and machine learning techniques lead to many novel wearable IoT devices. These devices have limited battery capacity and computational power. Thus, energy harvesting from ambient sources is a promising solution to power these low-energy wearable devices. They need to manage the harvested energy optimally to achieve energy-neutral operation, which eliminates recharging requirements. Optimal energy management is a challenging task due to the dynamic nature of the harvested energy and the battery energy constraints of the target device. To address this challenge, we present a reinforcement learning-based energy management framework, tinyMAN, for resource-constrained wearable IoT devices. The framework maximizes the utilization of the target device under dynamic energy harvesting patterns and battery constraints. Moreover, tinyMAN does not rely on forecasts of the harvested energy which makes it a prediction-free approach. We deployed tinyMAN on a wearable device prototype using TensorFlow Lite for Micro thanks to its small memory footprint of less than 100 KB. Our evaluations show that tinyMAN achieves less than 2.36 ms and 27.75 $\mu$J while maintaining up to 45% higher utility compared to prior approaches.
SIAM: Chiplet-based Scalable In-Memory Acceleration with Mesh for Deep Neural Networks
Aug 14, 2021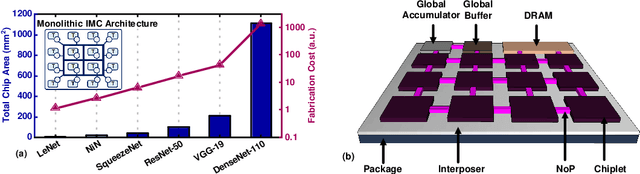
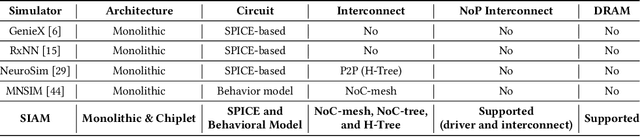
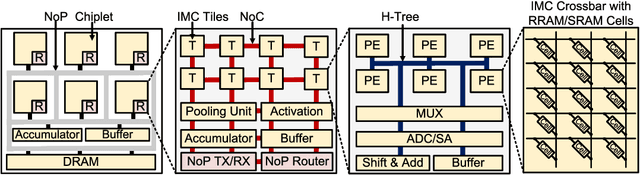
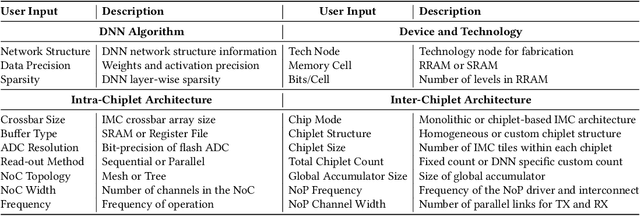
In-memory computing (IMC) on a monolithic chip for deep learning faces dramatic challenges on area, yield, and on-chip interconnection cost due to the ever-increasing model sizes. 2.5D integration or chiplet-based architectures interconnect multiple small chips (i.e., chiplets) to form a large computing system, presenting a feasible solution beyond a monolithic IMC architecture to accelerate large deep learning models. This paper presents a new benchmarking simulator, SIAM, to evaluate the performance of chiplet-based IMC architectures and explore the potential of such a paradigm shift in IMC architecture design. SIAM integrates device, circuit, architecture, network-on-chip (NoC), network-on-package (NoP), and DRAM access models to realize an end-to-end system. SIAM is scalable in its support of a wide range of deep neural networks (DNNs), customizable to various network structures and configurations, and capable of efficient design space exploration. We demonstrate the flexibility, scalability, and simulation speed of SIAM by benchmarking different state-of-the-art DNNs with CIFAR-10, CIFAR-100, and ImageNet datasets. We further calibrate the simulation results with a published silicon result, SIMBA. The chiplet-based IMC architecture obtained through SIAM shows 130$\times$ and 72$\times$ improvement in energy-efficiency for ResNet-50 on the ImageNet dataset compared to Nvidia V100 and T4 GPUs.
FLASH: Fast Neural Architecture Search with Hardware Optimization
Aug 01, 2021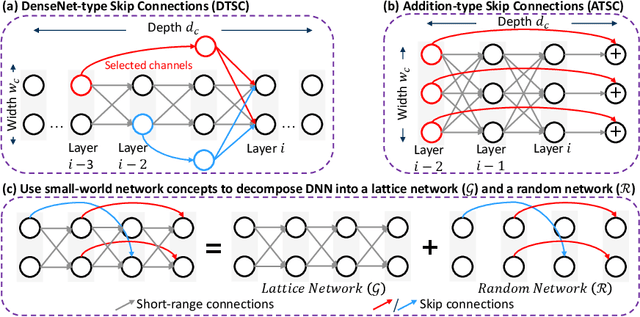

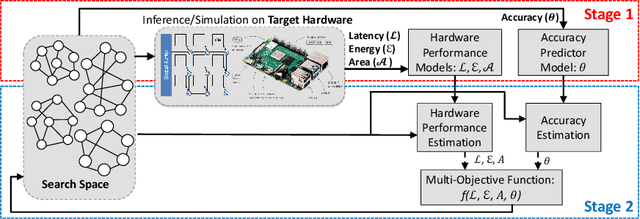

Neural architecture search (NAS) is a promising technique to design efficient and high-performance deep neural networks (DNNs). As the performance requirements of ML applications grow continuously, the hardware accelerators start playing a central role in DNN design. This trend makes NAS even more complicated and time-consuming for most real applications. This paper proposes FLASH, a very fast NAS methodology that co-optimizes the DNN accuracy and performance on a real hardware platform. As the main theoretical contribution, we first propose the NN-Degree, an analytical metric to quantify the topological characteristics of DNNs with skip connections (e.g., DenseNets, ResNets, Wide-ResNets, and MobileNets). The newly proposed NN-Degree allows us to do training-free NAS within one second and build an accuracy predictor by training as few as 25 samples out of a vast search space with more than 63 billion configurations. Second, by performing inference on the target hardware, we fine-tune and validate our analytical models to estimate the latency, area, and energy consumption of various DNN architectures while executing standard ML datasets. Third, we construct a hierarchical algorithm based on simplicial homology global optimization (SHGO) to optimize the model-architecture co-design process, while considering the area, latency, and energy consumption of the target hardware. We demonstrate that, compared to the state-of-the-art NAS approaches, our proposed hierarchical SHGO-based algorithm enables more than four orders of magnitude speedup (specifically, the execution time of the proposed algorithm is about 0.1 seconds). Finally, our experimental evaluations show that FLASH is easily transferable to different hardware architectures, thus enabling us to do NAS on a Raspberry Pi-3B processor in less than 3 seconds.
Impact of On-Chip Interconnect on In-Memory Acceleration of Deep Neural Networks
Jul 06, 2021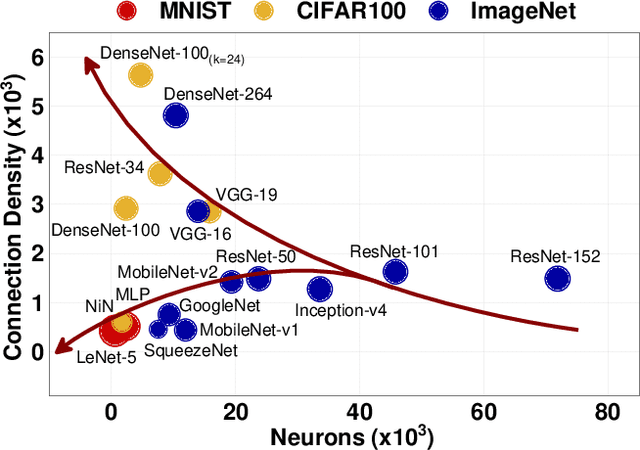
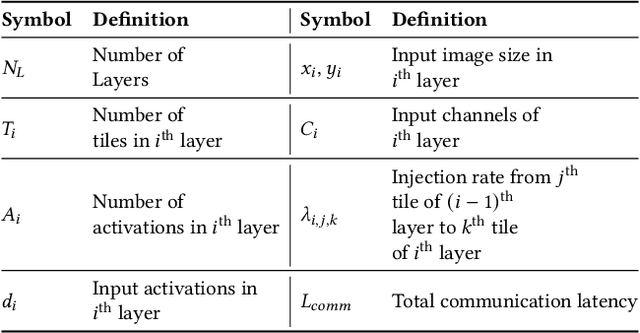
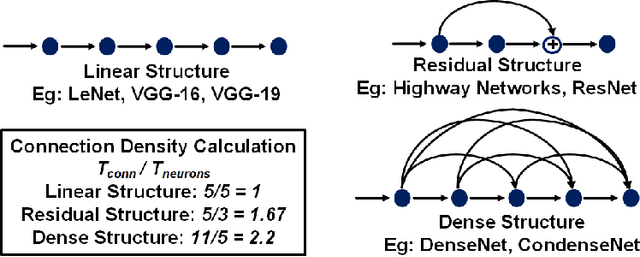

With the widespread use of Deep Neural Networks (DNNs), machine learning algorithms have evolved in two diverse directions -- one with ever-increasing connection density for better accuracy and the other with more compact sizing for energy efficiency. The increase in connection density increases on-chip data movement, which makes efficient on-chip communication a critical function of the DNN accelerator. The contribution of this work is threefold. First, we illustrate that the point-to-point (P2P)-based interconnect is incapable of handling a high volume of on-chip data movement for DNNs. Second, we evaluate P2P and network-on-chip (NoC) interconnect (with a regular topology such as a mesh) for SRAM- and ReRAM-based in-memory computing (IMC) architectures for a range of DNNs. This analysis shows the necessity for the optimal interconnect choice for an IMC DNN accelerator. Finally, we perform an experimental evaluation for different DNNs to empirically obtain the performance of the IMC architecture with both NoC-tree and NoC-mesh. We conclude that, at the tile level, NoC-tree is appropriate for compact DNNs employed at the edge, and NoC-mesh is necessary to accelerate DNNs with high connection density. Furthermore, we propose a technique to determine the optimal choice of interconnect for any given DNN. In this technique, we use analytical models of NoC to evaluate end-to-end communication latency of any given DNN. We demonstrate that the interconnect optimization in the IMC architecture results in up to 6$\times$ improvement in energy-delay-area product for VGG-19 inference compared to the state-of-the-art ReRAM-based IMC architectures.
Hypervector Design for Efficient Hyperdimensional Computing on Edge Devices
Mar 08, 2021
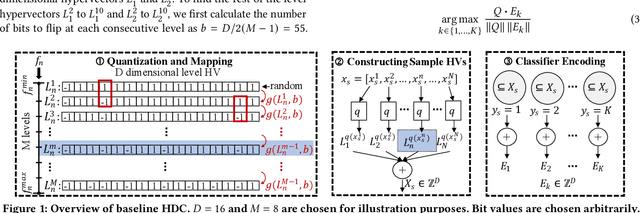

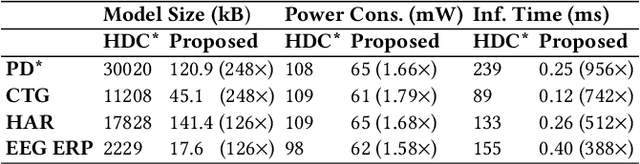
Hyperdimensional computing (HDC) has emerged as a new light-weight learning algorithm with smaller computation and energy requirements compared to conventional techniques. In HDC, data points are represented by high-dimensional vectors (hypervectors), which are mapped to high-dimensional space (hyperspace). Typically, a large hypervector dimension ($\geq1000$) is required to achieve accuracies comparable to conventional alternatives. However, unnecessarily large hypervectors increase hardware and energy costs, which can undermine their benefits. This paper presents a technique to minimize the hypervector dimension while maintaining the accuracy and improving the robustness of the classifier. To this end, we formulate the hypervector design as a multi-objective optimization problem for the first time in the literature. The proposed approach decreases the hypervector dimension by more than $32\times$ while maintaining or increasing the accuracy achieved by conventional HDC. Experiments on a commercial hardware platform show that the proposed approach achieves more than one order of magnitude reduction in model size, inference time, and energy consumption. We also demonstrate the trade-off between accuracy and robustness to noise and provide Pareto front solutions as a design parameter in our hypervector design.
Online Adaptive Learning for Runtime Resource Management of Heterogeneous SoCs
Aug 22, 2020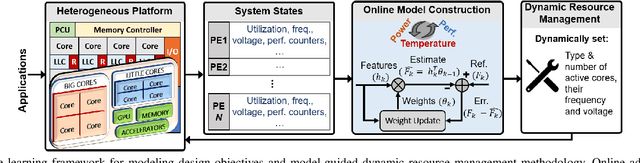
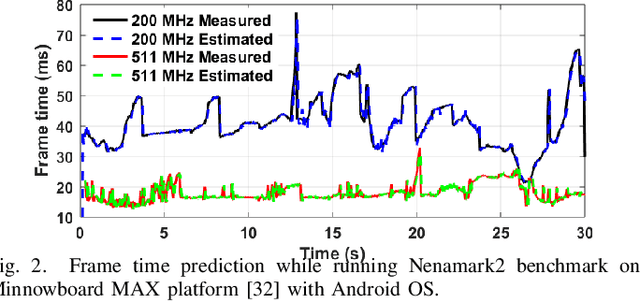
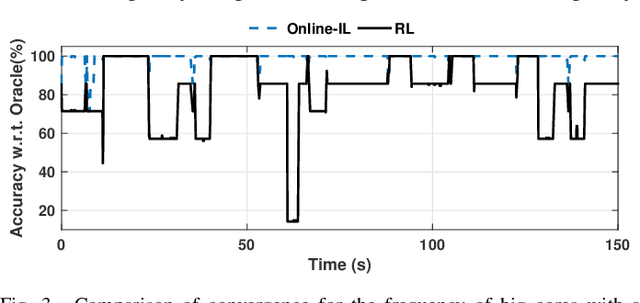
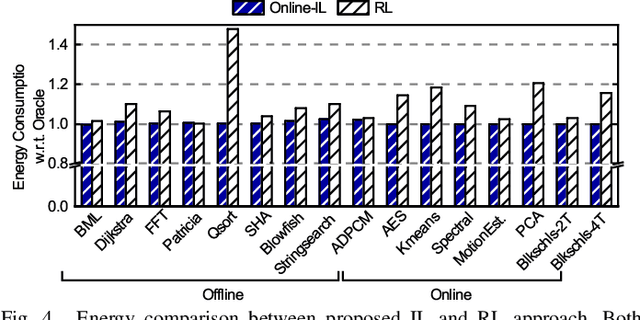
Dynamic resource management has become one of the major areas of research in modern computer and communication system design due to lower power consumption and higher performance demands. The number of integrated cores, level of heterogeneity and amount of control knobs increase steadily. As a result, the system complexity is increasing faster than our ability to optimize and dynamically manage the resources. Moreover, offline approaches are sub-optimal due to workload variations and large volume of new applications unknown at design time. This paper first reviews recent online learning techniques for predicting system performance, power, and temperature. Then, we describe the use of predictive models for online control using two modern approaches: imitation learning (IL) and an explicit nonlinear model predictive control (NMPC). Evaluations on a commercial mobile platform with 16 benchmarks show that the IL approach successfully adapts the control policy to unknown applications. The explicit NMPC provides 25% energy savings compared to a state-of-the-art algorithm for multi-variable power management of modern GPU sub-systems.