 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast and Scalable Human Pose Estimation using mmWave Point Cloud
Paper and Code
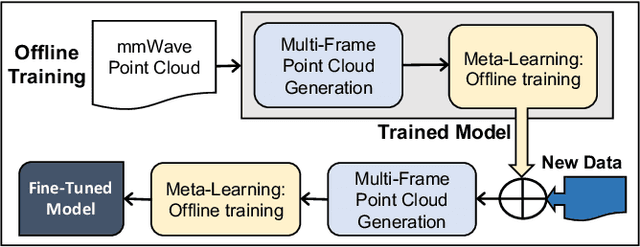
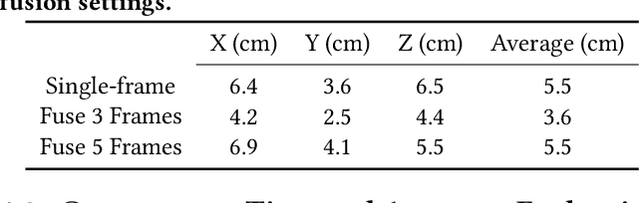
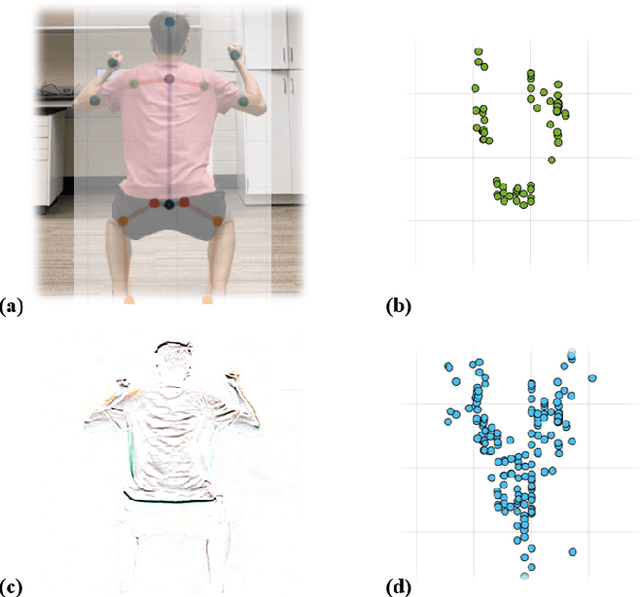
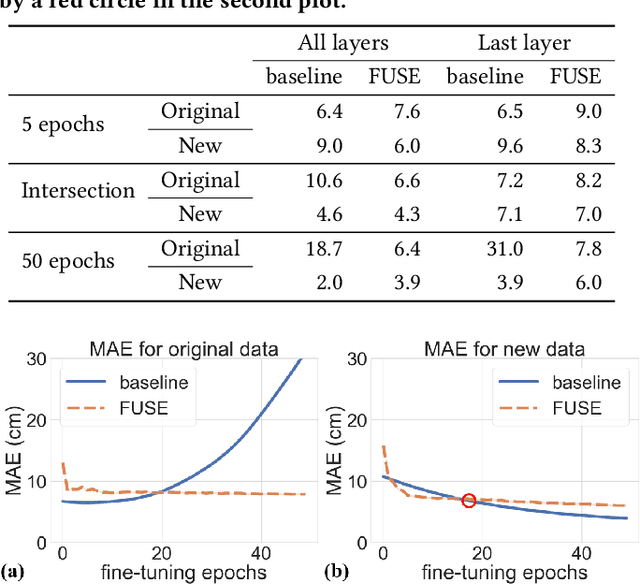
Millimeter-Wave (mmWave) radar can enable high-resolution human pose estimation with low cost and computational requirements. However, mmWave data point cloud, the primary input to processing algorithms, is highly sparse and carries significantly less information than other alternatives such as video frames. Furthermore, the scarce labeled mmWave data impedes the development of machine learning (ML) models that can generalize to unseen scenarios. We propose a fast and scalable human pose estimation (FUSE) framework that combines multi-frame representation and meta-learning to address these challenges. Experimental evaluations show that FUSE adapts to the unseen scenarios 4$\times$ faster than current supervised learning approaches and estimates human joint coordinates with about 7 cm mean absolute error.