 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSHOW3D: Capturing Scenes of 3D Hands and Objects in the Wild
Mar 30, 2026Accurate 3D understanding of human hands and objects during manipulation remains a significant challenge for egocentric computer vision. Existing hand-object interaction datasets are predominantly captured in controlled studio settings, which limits both environmental diversity and the ability of models trained on such data to generalize to real-world scenarios. To address this challenge, we introduce a novel marker-less multi-camera system that allows for nearly unconstrained mobility in genuinely in-the-wild conditions, while still having the ability to generate precise 3D annotations of hands and objects. The capture system consists of a lightweight, back-mounted, multi-camera rig that is synchronized and calibrated with a user-worn VR headset. For 3D ground-truth annotation of hands and objects, we develop an ego-exo tracking pipeline and rigorously evaluate its quality. Finally, we present SHOW3D, the first large-scale dataset with 3D annotations that show hands interacting with objects in diverse real-world environments, including outdoor settings. Our approach significantly reduces the fundamental trade-off between environmental realism and accuracy of 3D annotations, which we validate with experiments on several downstream tasks. show3d-dataset.github.io
UMO: Unified In-Context Learning Unlocks Motion Foundation Model Priors
Mar 16, 2026Large-scale foundation models (LFMs) have recently made impressive progress in text-to-motion generation by learning strong generative priors from massive 3D human motion datasets and paired text descriptions. However, how to effectively and efficiently leverage such single-purpose motion LFMs, i.e., text-to-motion synthesis, in more diverse cross-modal and in-context motion generation downstream tasks remains largely unclear. Prior work typically adapts pretrained generative priors to individual downstream tasks in a task-specific manner. In contrast, our goal is to unlock such priors to support a broad spectrum of downstream motion generation tasks within a single unified framework. To bridge this gap, we present UMO, a simple yet general unified formulation that casts diverse downstream tasks into compositions of atomic per-frame operations, enabling in-context adaptation to unlock the generative priors of pretrained DiT-based motion LFMs. Specifically, UMO introduces three learnable frame-level meta-operation embeddings to specify per-frame intent and employs lightweight temporal fusion to inject in-context cues into the pretrained backbone, with negligible runtime overhead compared to the base model. With this design, UMO finetunes the pretrained model, originally limited to text-to-motion generation, to support diverse previously unsupported tasks, including temporal inpainting, text-guided motion editing, text-serialized geometric constraints, and multi-identity reaction generation. Experiments demonstrate that UMO consistently outperforms task-specific and training-free baselines across a wide range of benchmarks, despite using a single unified model. Code and model will be publicly available. Project Page: https://oliver-cong02.github.io/UMO.github.io/
LLaMo: Scaling Pretrained Language Models for Unified Motion Understanding and Generation with Continuous Autoregressive Tokens
Feb 12, 2026Recent progress in large models has led to significant advances in unified multimodal generation and understanding. However, the development of models that unify motion-language generation and understanding remains largely underexplored. Existing approaches often fine-tune large language models (LLMs) on paired motion-text data, which can result in catastrophic forgetting of linguistic capabilities due to the limited scale of available text-motion pairs. Furthermore, prior methods typically convert motion into discrete representations via quantization to integrate with language models, introducing substantial jitter artifacts from discrete tokenization. To address these challenges, we propose LLaMo, a unified framework that extends pretrained LLMs through a modality-specific Mixture-of-Transformers (MoT) architecture. This design inherently preserves the language understanding of the base model while enabling scalable multimodal adaptation. We encode human motion into a causal continuous latent space and maintain the next-token prediction paradigm in the decoder-only backbone through a lightweight flow-matching head, allowing for streaming motion generation in real-time (>30 FPS). Leveraging the comprehensive language understanding of pretrained LLMs and large-scale motion-text pretraining, our experiments demonstrate that LLaMo achieves high-fidelity text-to-motion generation and motion-to-text captioning in general settings, especially zero-shot motion generation, marking a significant step towards a general unified motion-language large model.
SphereHead: Stable 3D Full-head Synthesis with Spherical Tri-plane Representation
Apr 08, 2024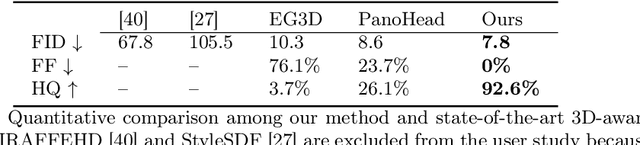

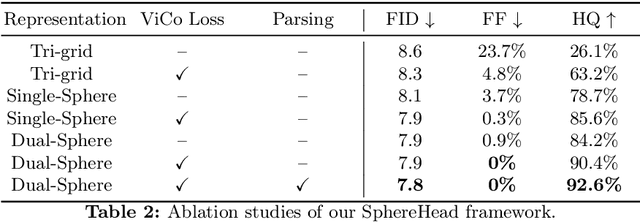
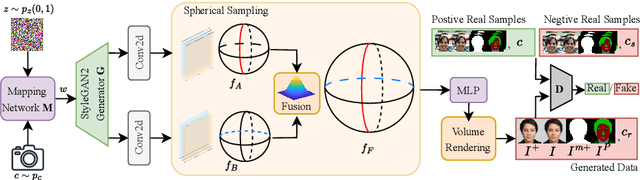
While recent advances in 3D-aware Generative Adversarial Networks (GANs) have aided the development of near-frontal view human face synthesis, the challenge of comprehensively synthesizing a full 3D head viewable from all angles still persists. Although PanoHead proves the possibilities of using a large-scale dataset with images of both frontal and back views for full-head synthesis, it often causes artifacts for back views. Based on our in-depth analysis, we found the reasons are mainly twofold. First, from network architecture perspective, we found each plane in the utilized tri-plane/tri-grid representation space tends to confuse the features from both sides, causing "mirroring" artifacts (e.g., the glasses appear in the back). Second, from data supervision aspect, we found that existing discriminator training in 3D GANs mainly focuses on the quality of the rendered image itself, and does not care much about its plausibility with the perspective from which it was rendered. This makes it possible to generate "face" in non-frontal views, due to its easiness to fool the discriminator. In response, we propose SphereHead, a novel tri-plane representation in the spherical coordinate system that fits the human head's geometric characteristics and efficiently mitigates many of the generated artifacts. We further introduce a view-image consistency loss for the discriminator to emphasize the correspondence of the camera parameters and the images. The combination of these efforts results in visually superior outcomes with significantly fewer artifacts. Our code and dataset are publicly available at https://lhyfst.github.io/spherehead.
PAniC-3D: Stylized Single-view 3D Reconstruction from Portraits of Anime Characters
Mar 25, 2023We propose PAniC-3D, a system to reconstruct stylized 3D character heads directly from illustrated (p)ortraits of (ani)me (c)haracters. Our anime-style domain poses unique challenges to single-view reconstruction; compared to natural images of human heads, character portrait illustrations have hair and accessories with more complex and diverse geometry, and are shaded with non-photorealistic contour lines. In addition, there is a lack of both 3D model and portrait illustration data suitable to train and evaluate this ambiguous stylized reconstruction task. Facing these challenges, our proposed PAniC-3D architecture crosses the illustration-to-3D domain gap with a line-filling model, and represents sophisticated geometries with a volumetric radiance field. We train our system with two large new datasets (11.2k Vroid 3D models, 1k Vtuber portrait illustrations), and evaluate on a novel AnimeRecon benchmark of illustration-to-3D pairs. PAniC-3D significantly outperforms baseline methods, and provides data to establish the task of stylized reconstruction from portrait illustrations.
PanoHead: Geometry-Aware 3D Full-Head Synthesis in 360$^{\circ}$
Mar 23, 2023
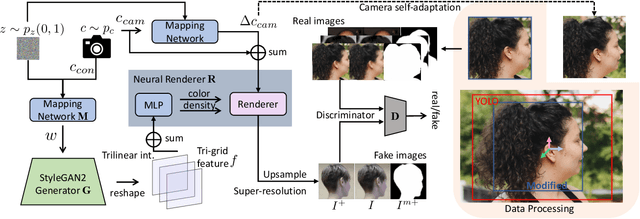


Synthesis and reconstruction of 3D human head has gained increasing interests in computer vision and computer graphics recently. Existing state-of-the-art 3D generative adversarial networks (GANs) for 3D human head synthesis are either limited to near-frontal views or hard to preserve 3D consistency in large view angles. We propose PanoHead, the first 3D-aware generative model that enables high-quality view-consistent image synthesis of full heads in $360^\circ$ with diverse appearance and detailed geometry using only in-the-wild unstructured images for training. At its core, we lift up the representation power of recent 3D GANs and bridge the data alignment gap when training from in-the-wild images with widely distributed views. Specifically, we propose a novel two-stage self-adaptive image alignment for robust 3D GAN training. We further introduce a tri-grid neural volume representation that effectively addresses front-face and back-head feature entanglement rooted in the widely-adopted tri-plane formulation. Our method instills prior knowledge of 2D image segmentation in adversarial learning of 3D neural scene structures, enabling compositable head synthesis in diverse backgrounds. Benefiting from these designs, our method significantly outperforms previous 3D GANs, generating high-quality 3D heads with accurate geometry and diverse appearances, even with long wavy and afro hairstyles, renderable from arbitrary poses. Furthermore, we show that our system can reconstruct full 3D heads from single input images for personalized realistic 3D avatars.
mRI: Multi-modal 3D Human Pose Estimation Dataset using mmWave, RGB-D, and Inertial Sensors
Oct 15, 2022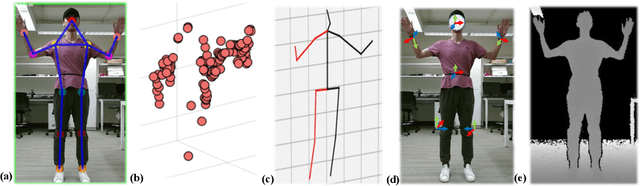
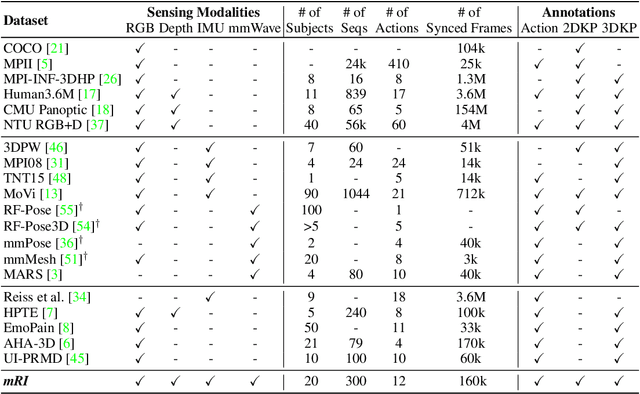


The ability to estimate 3D human body pose and movement, also known as human pose estimation (HPE), enables many applications for home-based health monitoring, such as remote rehabilitation training. Several possible solutions have emerged using sensors ranging from RGB cameras, depth sensors, millimeter-Wave (mmWave) radars, and wearable inertial sensors. Despite previous efforts on datasets and benchmarks for HPE, few dataset exploits multiple modalities and focuses on home-based health monitoring. To bridge the gap, we present mRI, a multi-modal 3D human pose estimation dataset with mmWave, RGB-D, and Inertial Sensors. Our dataset consists of over 160k synchronized frames from 20 subjects performing rehabilitation exercises and supports the benchmarks of HPE and action detection. We perform extensive experiments using our dataset and delineate the strength of each modality. We hope that the release of mRI can catalyze the research in pose estimation, multi-modal learning, and action understanding, and more importantly facilitate the applications of home-based health monitoring.
Fast and Scalable Human Pose Estimation using mmWave Point Cloud
Apr 29, 2022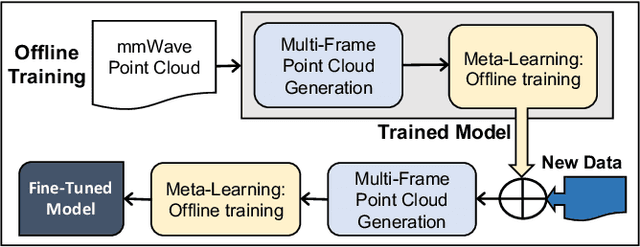
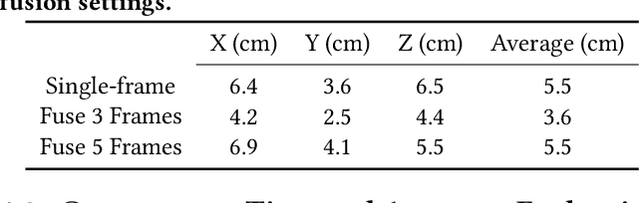
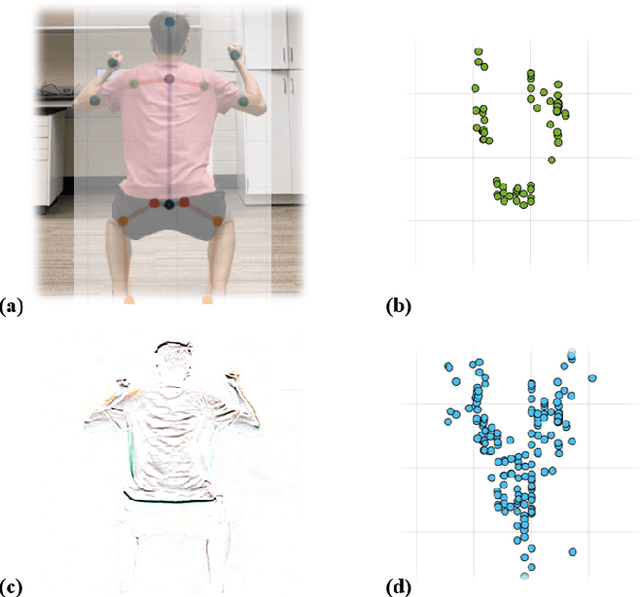
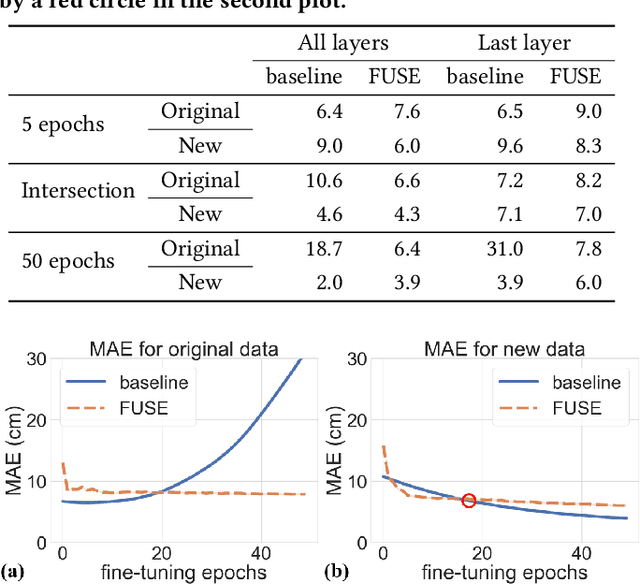
Millimeter-Wave (mmWave) radar can enable high-resolution human pose estimation with low cost and computational requirements. However, mmWave data point cloud, the primary input to processing algorithms, is highly sparse and carries significantly less information than other alternatives such as video frames. Furthermore, the scarce labeled mmWave data impedes the development of machine learning (ML) models that can generalize to unseen scenarios. We propose a fast and scalable human pose estimation (FUSE) framework that combines multi-frame representation and meta-learning to address these challenges. Experimental evaluations show that FUSE adapts to the unseen scenarios 4$\times$ faster than current supervised learning approaches and estimates human joint coordinates with about 7 cm mean absolute error.
MGait: Model-Based Gait Analysis Using Wearable Bend and Inertial Sensors
Feb 23, 2021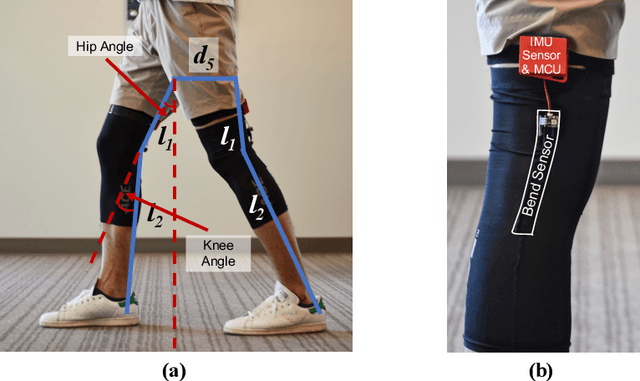
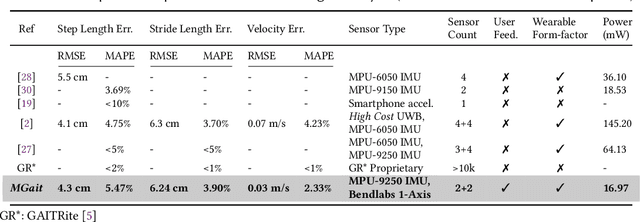
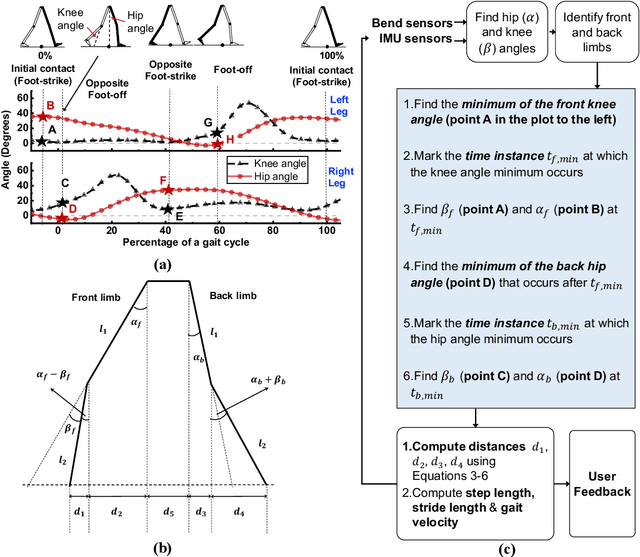
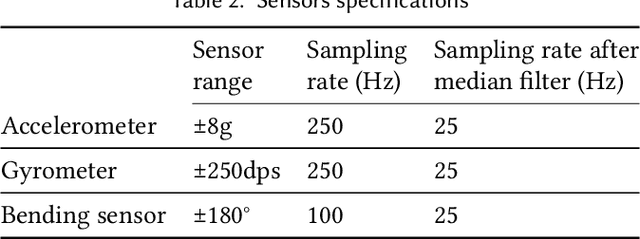
Movement disorders, such as Parkinson's disease, affect more than 10 million people worldwide. Gait analysis is a critical step in the diagnosis and rehabilitation of these disorders. Specifically, step length provides valuable insights into the gait quality and rehabilitation process. However, traditional approaches for estimating step length are not suitable for continuous daily monitoring since they rely on special mats and clinical environments. To address this limitation, we present a novel and practical step-length estimation technique using low-power wearable bend and inertial sensors. Experimental results show that the proposed model estimates step length with 5.49% mean absolute percentage error and provides accurate real-time feedback to the user.
Transfer Learning for Human Activity Recognition using Representational Analysis of Neural Networks
Dec 05, 2020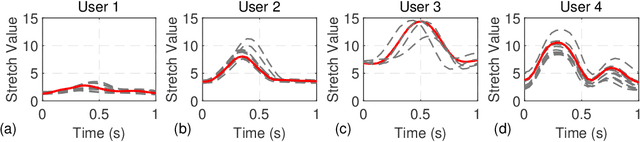
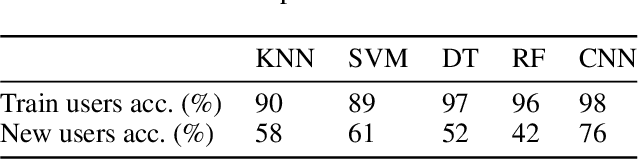

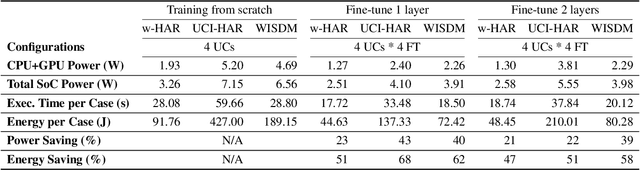
Human activity recognition (HAR) research has increased in recent years due to its applications in mobile health monitoring, activity recognition, and patient rehabilitation. The typical approach is training a HAR classifier offline with known users and then using the same classifier for new users. However, the accuracy for new users can be low with this approach if their activity patterns are different than those in the training data. At the same time, training from scratch for new users is not feasible for mobile applications due to the high computational cost and training time. To address this issue, we propose a HAR transfer learning framework with two components. First, a representational analysis reveals common features that can transfer across users and user-specific features that need to be customized. Using this insight, we transfer the reusable portion of the offline classifier to new users and fine-tune only the rest. Our experiments with five datasets show up to 43% accuracy improvement and 66% training time reduction when compared to the baseline without using transfer learning. Furthermore, measurements on the Nvidia Jetson Xavier-NX hardware platform reveal that the power and energy consumption decrease by 43% and 68%, respectively, while achieving the same or higher accuracy as training from scratch.