 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Source Retrieval Question Answering Framework Based on RAG
May 29, 2024



With the rapid development of large-scale language models, Retrieval-Augmented Generation (RAG) has been widely adopted. However, existing RAG paradigms are inevitably influenced by erroneous retrieval information, thereby reducing the reliability and correctness of generated results. Therefore, to improve the relevance of retrieval information, this study proposes a method that replaces traditional retrievers with GPT-3.5, leveraging its vast corpus knowledge to generate retrieval information. We also propose a web retrieval based method to implement fine-grained knowledge retrieval, Utilizing the powerful reasoning capability of GPT-3.5 to realize semantic partitioning of problem.In order to mitigate the illusion of GPT retrieval and reduce noise in Web retrieval,we proposes a multi-source retrieval framework, named MSRAG, which combines GPT retrieval with web retrieval. Experiments on multiple knowledge-intensive QA datasets demonstrate that the proposed framework in this study performs better than existing RAG framework in enhancing the overall efficiency and accuracy of QA systems.
PAniC-3D: Stylized Single-view 3D Reconstruction from Portraits of Anime Characters
Mar 25, 2023We propose PAniC-3D, a system to reconstruct stylized 3D character heads directly from illustrated (p)ortraits of (ani)me (c)haracters. Our anime-style domain poses unique challenges to single-view reconstruction; compared to natural images of human heads, character portrait illustrations have hair and accessories with more complex and diverse geometry, and are shaded with non-photorealistic contour lines. In addition, there is a lack of both 3D model and portrait illustration data suitable to train and evaluate this ambiguous stylized reconstruction task. Facing these challenges, our proposed PAniC-3D architecture crosses the illustration-to-3D domain gap with a line-filling model, and represents sophisticated geometries with a volumetric radiance field. We train our system with two large new datasets (11.2k Vroid 3D models, 1k Vtuber portrait illustrations), and evaluate on a novel AnimeRecon benchmark of illustration-to-3D pairs. PAniC-3D significantly outperforms baseline methods, and provides data to establish the task of stylized reconstruction from portrait illustrations.
Improving the Perceptual Quality of 2D Animation Interpolation
Nov 24, 2021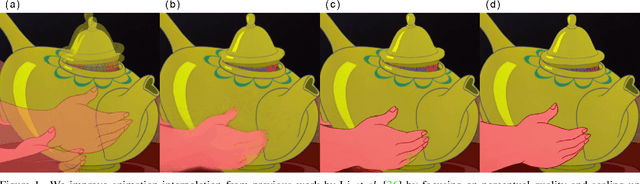



Traditional 2D animation is labor-intensive, often requiring animators to manually draw twelve illustrations per second of movement. While automatic frame interpolation may ease this burden, the artistic effects inherent to 2D animation make video synthesis particularly challenging compared to in the photorealistic domain. Lower framerates result in larger displacements and occlusions, discrete perceptual elements (e.g. lines and solid-color regions) pose difficulties for texture-oriented convolutional networks, and exaggerated nonlinear movements hinder training data collection. Previous work tried addressing these issues, but used unscalable methods and focused on pixel-perfect performance. In contrast, we build a scalable system more appropriately centered on perceptual quality for this artistic domain. Firstly, we propose a lightweight architecture with a simple yet effective occlusion-inpainting technique to improve convergence on perceptual metrics with fewer trainable parameters. Secondly, we design a novel auxiliary module that leverages the Euclidean distance transform to improve the preservation of key line and region structures. Thirdly, we automatically double the existing manually-collected dataset for this task by quantitatively filtering out movement nonlinearities, allowing us to improve model generalization. Finally, we establish LPIPS and chamfer distance as strongly preferable to PSNR and SSIM through a user study, validating our system's emphasis on perceptual quality in the 2D animation domain.
Transfer Learning for Pose Estimation of Illustrated Characters
Aug 04, 2021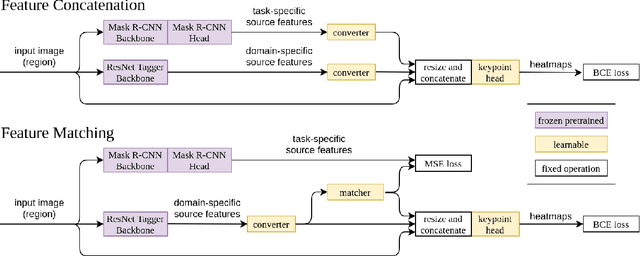
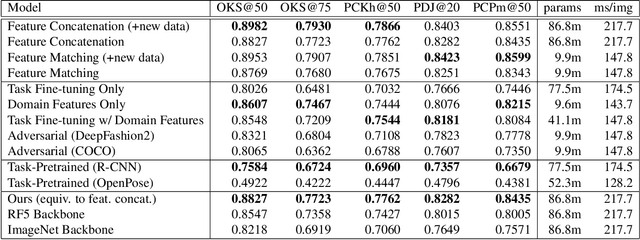
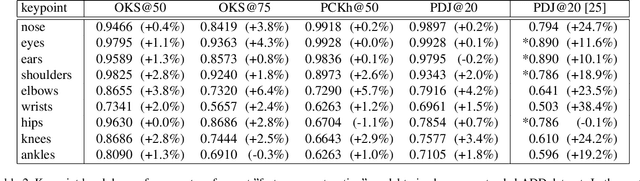

Human pose information is a critical component in many downstream image processing tasks, such as activity recognition and motion tracking. Likewise, a pose estimator for the illustrated character domain would provide a valuable prior for assistive content creation tasks, such as reference pose retrieval and automatic character animation. But while modern data-driven techniques have substantially improved pose estimation performance on natural images, little work has been done for illustrations. In our work, we bridge this domain gap by efficiently transfer-learning from both domain-specific and task-specific source models. Additionally, we upgrade and expand an existing illustrated pose estimation dataset, and introduce two new datasets for classification and segmentation subtasks. We then apply the resultant state-of-the-art character pose estimator to solve the novel task of pose-guided illustration retrieval. All data, models, and code will be made publicly available.
Neural Radiosity
May 26, 2021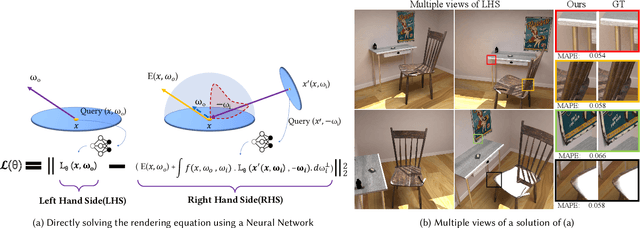
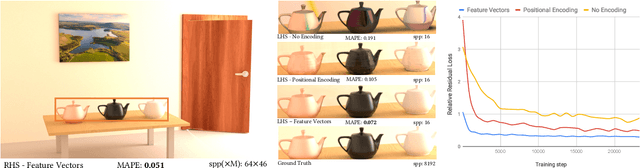


We introduce Neural Radiosity, an algorithm to solve the rendering equation by minimizing the norm of its residual similar as in traditional radiosity techniques. Traditional basis functions used in radiosity techniques, such as piecewise polynomials or meshless basis functions are typically limited to representing isotropic scattering from diffuse surfaces. Instead, we propose to leverage neural networks to represent the full four-dimensional radiance distribution, directly optimizing network parameters to minimize the norm of the residual. Our approach decouples solving the rendering equation from rendering (perspective) images similar as in traditional radiosity techniques, and allows us to efficiently synthesize arbitrary views of a scene. In addition, we propose a network architecture using geometric learnable features that improves convergence of our solver compared to previous techniques. Our approach leads to an algorithm that is simple to implement, and we demonstrate its effectiveness on a variety of scenes with non-diffuse surfaces.
Using Sampling Strategy to Assist Consensus Sequence Analysis
Aug 19, 2020
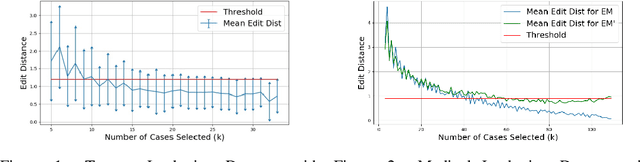
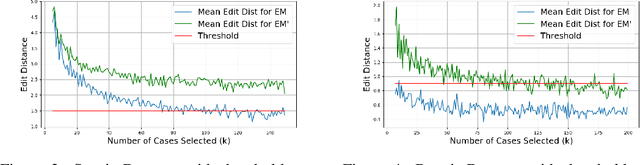

Consensus Sequences of event logs are often used in process mining to quickly grasp the core sequence of events to be performed in a process, or to represent the backbone of the process for doing other analyses. However, it is still not clear how many traces are enough to properly represent the underlying process. In this paper, we propose a novel sampling strategy to determine the number of traces necessary to produce a representative consensus sequence. We show how to estimate the difference between the predefined Expert Model and the real processes carried out. This difference level can be used as reference for domain experts to adjust the Expert Model. In addition, we apply this strategy to several real-world workflow activity datasets as a case study. We show a sample curve fitting task to help readers better understand our proposed methodology.
Tri-axial Self-Attention for Concurrent Activity Recognition
Dec 06, 2018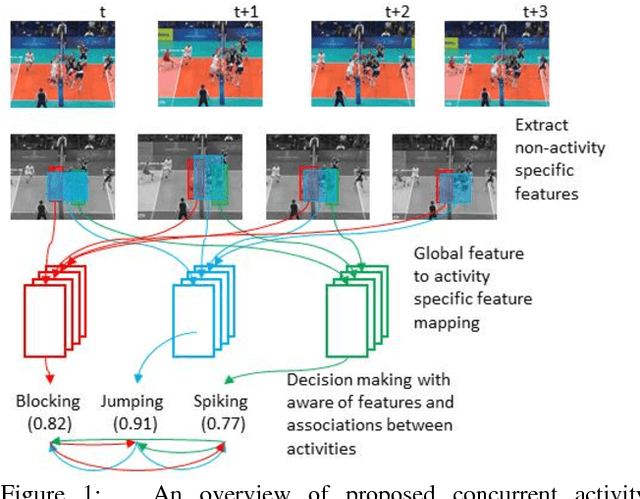
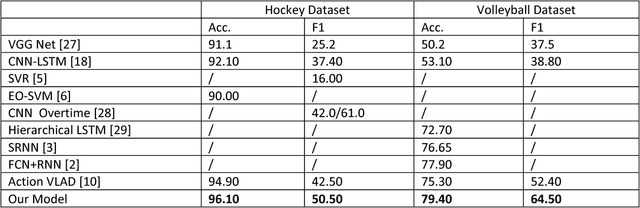
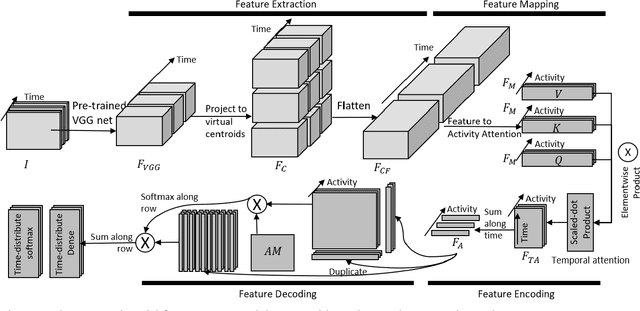
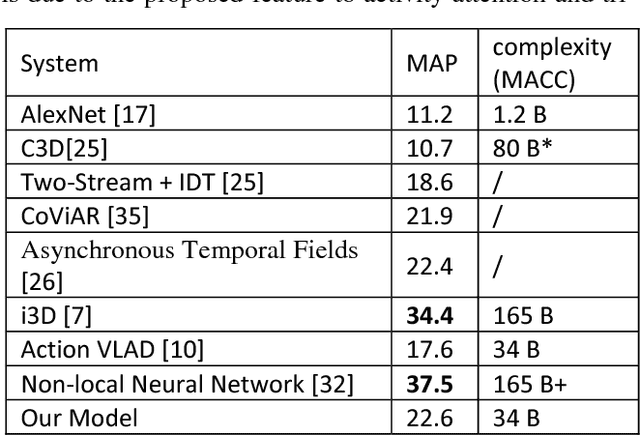
We present a system for concurrent activity recognition. To extract features associated with different activities, we propose a feature-to-activity attention that maps the extracted global features to sub-features associated with individual activities. To model the temporal associations of individual activities, we propose a transformer-network encoder that models independent temporal associations for each activity. To make the concurrent activity prediction aware of the potential associations between activities, we propose self-attention with an association mask. Our system achieved state-of-the-art or comparable performance on three commonly used concurrent activity detection datasets. Our visualizations demonstrate that our system is able to locate the important spatial-temporal features for final decision making. We also showed that our system can be applied to general multilabel classification problems.
Multimodal Affective Analysis Using Hierarchical Attention Strategy with Word-Level Alignment
May 22, 2018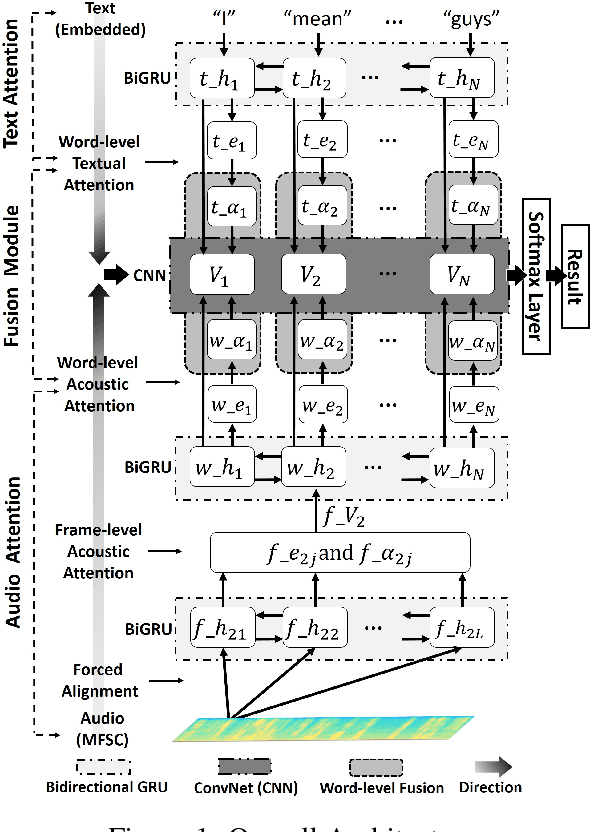
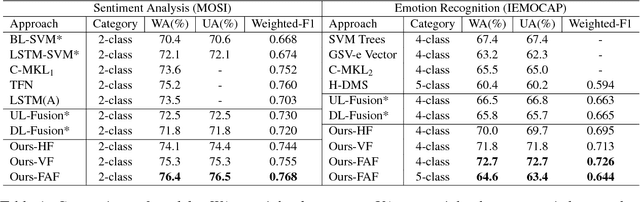
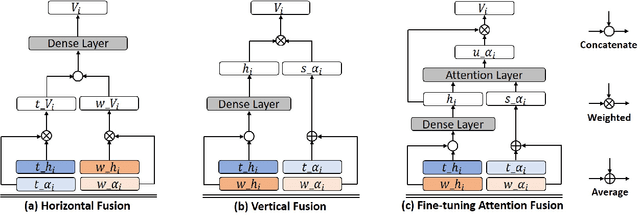
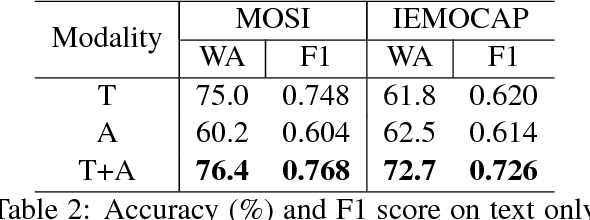
Multimodal affective computing, learning to recognize and interpret human affects and subjective information from multiple data sources, is still challenging because: (i) it is hard to extract informative features to represent human affects from heterogeneous inputs; (ii) current fusion strategies only fuse different modalities at abstract level, ignoring time-dependent interactions between modalities. Addressing such issues, we introduce a hierarchical multimodal architecture with attention and word-level fusion to classify utter-ance-level sentiment and emotion from text and audio data. Our introduced model outperforms the state-of-the-art approaches on published datasets and we demonstrated that our model is able to visualize and interpret the synchronized attention over modalities.
Deep Multimodal Learning for Emotion Recognition in Spoken Language
Feb 22, 2018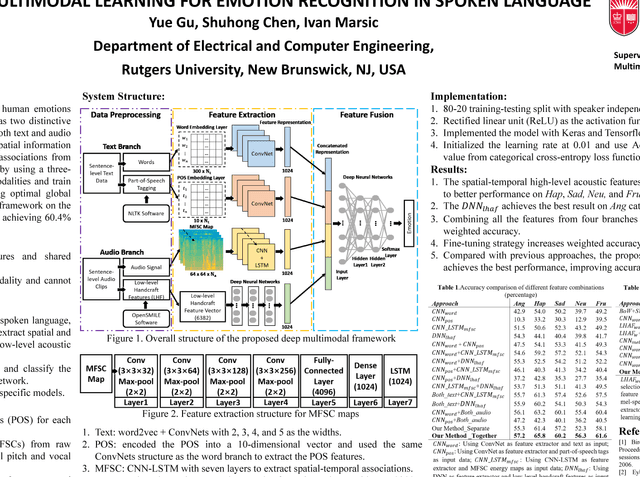
In this paper, we present a novel deep multimodal framework to predict human emotions based on sentence-level spoken language. Our architecture has two distinctive characteristics. First, it extracts the high-level features from both text and audio via a hybrid deep multimodal structure, which considers the spatial information from text, temporal information from audio, and high-level associations from low-level handcrafted features. Second, we fuse all features by using a three-layer deep neural network to learn the correlations across modalities and train the feature extraction and fusion modules together, allowing optimal global fine-tuning of the entire structure. We evaluated the proposed framework on the IEMOCAP dataset. Our result shows promising performance, achieving 60.4% in weighted accuracy for five emotion categories.
Process-oriented Iterative Multiple Alignment for Medical Process Mining
Sep 16, 2017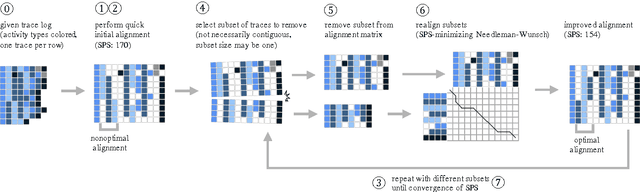
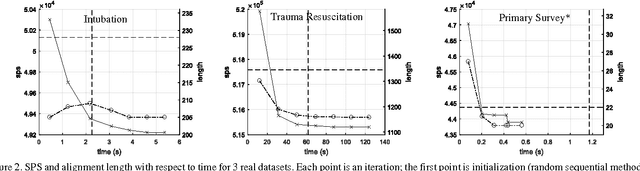
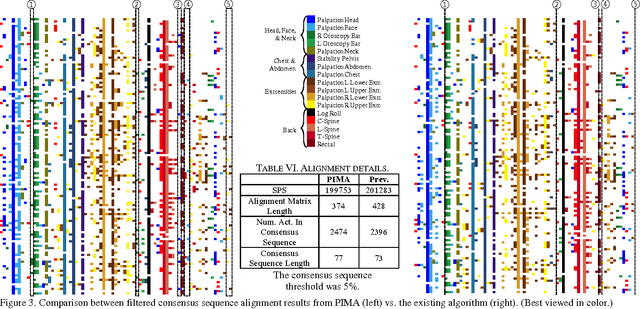

Adapted from biological sequence alignment, trace alignment is a process mining technique used to visualize and analyze workflow data. Any analysis done with this method, however, is affected by the alignment quality. The best existing trace alignment techniques use progressive guide-trees to heuristically approximate the optimal alignment in O(N2L2) time. These algorithms are heavily dependent on the selected guide-tree metric, often return sum-of-pairs-score-reducing errors that interfere with interpretation, and are computationally intensive for large datasets. To alleviate these issues, we propose process-oriented iterative multiple alignment (PIMA), which contains specialized optimizations to better handle workflow data. We demonstrate that PIMA is a flexible framework capable of achieving better sum-of-pairs score than existing trace alignment algorithms in only O(NL2) time. We applied PIMA to analyzing medical workflow data, showing how iterative alignment can better represent the data and facilitate the extraction of insights from data visualization.